
RAGのビジネス適用に向けたパフォーマンス改善ガイド

日鉄ソリューションズ株式会社でW&Bの技術支援を担当している藤野・高畠です。生成AIにおいて重要な役割を果たすRAGですが、ビジネスシーンで効果的に活用するためには、回答精度の向上をはじめとしたさまざまな改善が求められます。本記事では、RAG改善のために押さえておきたいポイントを解説します。
1. RAG改善の目的
Retrieval-Augmented Generation (RAG)は、生成AIアプリケーションにおいて外部データソースを活用しながら応答を生成するアプローチであり、大規模言語モデル (LLM) の強力な生成能力と外部知識ベースの情報を組み合わせることで、幅広いユースケースに対応できる事からLLMの実業務適用の手法としてデファクトスタンダードとなりつつあります。
しかし、開発したRAGシステムを実業務へ適用する場合、以下に代表される様々な項目でユーザの要求に応える必要があり、RAGのパフォーマンスを改善していく事が業務適用効果の創出の鍵となります。
RAGシステムの代表的な評価項目
検索品質
関連性の高い情報をどの程度正常に取得しているかを、精度(Precision), 再現率(Recall), MRR(Mean Reciprocal Rank) に代表される指標により評価します。
応答品質
ユーザのリクエストに対し適切に応答しているかを、正確性(Correctness)、根拠性(Groundedness)、有害性(Toxicity)に代表される指標により評価します。
システムパフォーマンス
データ量やユーザー数の増加に伴う応答時間の変化に基づくレイテンシーや、トークン消費量や計算リソースの使用量などに基づくコストの観点からシステムのパフォーマンスを評価します。システムパフォーマンスの低下はユーザビリティやビジネスインパクトの低下に繋がるため重要な指標の一つとなります。
2. RAGのパフォーマンス低下の原因
ではRAGのパフォーマンスが低くなる原因とは何でしょうか?
実際にRAGの実業務適用を進める上での代表例としては以下が挙げられます。
①曖昧なクエリ
ユーザーの質問が曖昧で具体性を欠いている場合、関連する情報を正確に取得するのが難しく、ユーザの意図とは異なる検索結果となる可能性があります。
②インデックスの最適化不足
データのチャンク化や埋め込みベクトルの品質が不十分だと、クエリと検索対象データの関連性が低いことから、十分な検索性能が得られない原因となります。
③リランキングの不備
リランキングは検索性能を補うテクニックとして有効ですが、リランキングが十分に機能していない場合、検索結果に本来抽出すべき最も関連性の高いデータが含まれない可能性があります。
④応答の一貫性の欠如
回答の生成を行うLLMの性能が十分でない事などが原因となり、検索結果と生成された回答に矛盾が生じるといった問題があります。
それでは次にこれら原因に対しどのような改善手法があるかを見ていきます。
3. RAG改善手法
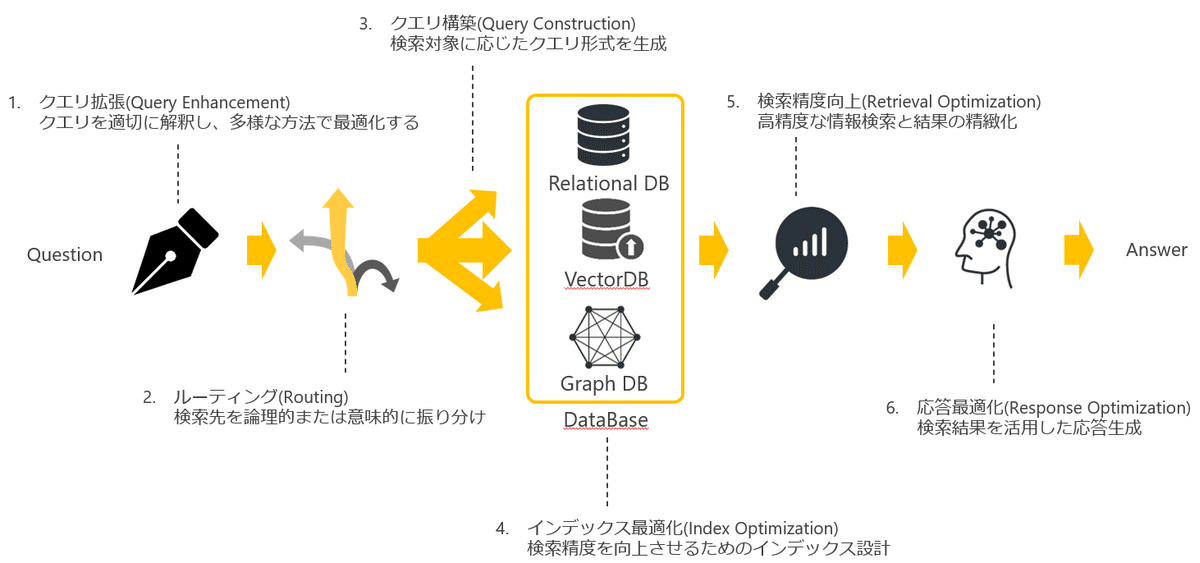
図1はRAGシステムの処理フローを表しています。RAGの改善と一言で言っても様々な要素があり、今回はこの処理フローをベースに質問の受け取りから回答生成までの主要な6つのステップについて、それぞれの改善ポイントをご紹介します。
クエリ拡張 (Query Enhancement): クエリを適切に解釈し、多様な方法で最適化する。
ルーティング (Routing): 検索先を論理的または意味的に振り分け。
クエリ構築 (Query Construction): 検索対象に応じた最適なクエリ形式を生成。
インデックス最適化 (Index Optimization): 検索精度を向上させるためのインデックス設計。
検索精度向上 (Retrieval Optimization): 高精度な情報検索と結果の精緻化。
応答最適化 (Response Optimization): 検索結果を活用した応答生成。
3-1. クエリ拡張(Query Enhancement)
対応目的: 「1. 検索品質」向上
対応原因: 「①曖昧なクエリ」
クエリ拡張は、ユーザーから入力されるクエリを最適な形に変換するプロセスです。これにより、曖昧なクエリを具体化し、関連性の高い情報を取得する可能性を高めることができます。検索の精度を向上させるためには、クエリを適切に補正し、必要な情報を過不足なく抽出することが重要です。主なアプローチとしては、クエリの分解や再構築、多様なクエリ形式の生成、仮説生成に基づく検索などがあります。これにより、検索精度を向上させるとともに、複雑なクエリにも対応可能になります。以下に、代表的なクエリ拡張の手法を紹介します。
Multi-query: クエリを複数の視点から分割し、並行的に処理することで検索精度を向上させます。
RAG-Fusion: 異なる情報源から取得した検索結果を統合し、それらを比較・補完することで、より正確で一貫性のある回答を導き出します。
Decomposition: 複雑なクエリをシンプルなサブクエリに分解します。
Step-back: 一度検索結果をレビューし、再クエリを行う手法です。
HyDE: 仮説を生成し、それを基に追加の情報を検索します。
3-2. ルーティング(Routing)
対応目的: 「1. 検索品質」向上、「3. システムパフォーマンス」改善
対応原因: 「①曖昧なクエリ」、「②インデックスの最適化不足」
簡単に言うと、ルーティングは「クエリの内容に応じて最適な検索経路を選ぶプロセス」です。例えば、「技術的な質問」なら技術文書、「FAQに関する質問」ならFAQデータベース、といった具合に、クエリごとに最適なデータソースを選びます。この仕組みのおかげで、不要な情報を排除しつつ、必要な情報だけを効率よく取得できます。適切なルーティングは、ルーティングを行わないシンプルなRAGの場合と比べ、検索の正確性を高めるとともに、全体の処理速度を向上させます。以下に、代表的なルーティングの手法を紹介します。
Logical routing: 明確なルールに基づいてデータソースを選択します。例えば、クエリの種類(FAQ、技術文書、社内ドキュメントなど)に応じて、検索先を固定的に振り分けます。これにより、不要なデータを検索対象から外し、検索精度と処理速度を向上させます。
Semantic routing: クエリの意味解析に基づいて検索先を決定します。クエリの内容をベクトル化し、意味的に関連性の高いデータソースを選定することで、検索の精度を向上させます。
3-3. クエリ構築(Query Construction)
対応目的: 「1. 検索品質」向上
対応原因: 「①曖昧なクエリ」
クエリ構築は、検索対象データベースに合わせて最適なクエリを生成するプロセスです。例えば、シンプルなRAGでは主にVectorDBが用いられます。これは、埋め込み検索による高精度な情報取得が目的となります。一方で、検索対象の特性によりRDB、GraphDBなどの異なるデータベース形式への対応が求められます。その場合、自然言語クエリをSQLやCypherといった構造化クエリに変換することで、データベースの特性を最大限に活用し、効率的な情報取得を可能にします。以下に、代表的なクエリ構築の手法を紹介します。
VectorDB向け: Self-query retriever: クエリ自体を最適化し、埋め込み空間で高精度な検索を実現します。
RDB向け: Text-to-SQL: 自然言語クエリをSQL形式に変換し、構造化データベース上で効率的に検索します。これにより、非技術者でも高度なSQLクエリを使用可能となります。
GraphDB向け: Text-to-Cypher: 自然言語クエリをCypherクエリに変換し、グラフデータベースの関係性を活用した検索を実現します。これにより、複雑なデータ間の関連性を効率的に抽出できます。
3-4. インデックス最適化(Index Optimization)
対応目的: 「1. 検索品質」向上、「3. システムパフォーマンス」改善
対応原因: 「②インデックスの最適化不足」
インデクス最適化は、検索性能とスケーラビリティを高めるためのデータ構造や戦略の最適化を行うプロセスです。データの分割や表現形式の最適化、専門的な埋め込みの生成などにより、検索精度を向上させます。インデックス設計はRAGの基盤を強化し、大規模データ環境でも高性能を発揮します。以下に、代表的なインデックス最適化の手法を紹介します。
Chunk Optimization: データを意味的に適切な単位で分割することで、検索の精度と効率を向上させます。
Multi-representation indexing: 親ドキュメントや異なるベクトル表現を併用することで、多面的な検索を実現します。
Specialized Embeddings: 埋め込みモデルを微調整や特定タスク向けに最適化することで、より正確な検索を可能にします。
Hierarchical Indexing: データの階層的なインデックス設計により、効率的な検索とリソース使用を最適化します。
3-5. 検索精度向上(Retrieval Optimization)
対応目的: 「1. 検索品質」向上
対応原因: 「①曖昧なクエリ」、「③リランキングの不備」
RAGでは、ユーザーの質問に対して最も関連性の高い情報を検索し、それを基に回答を生成します。そのため、検索精度がRAG全体の性能を左右する重要な要素となります。以下に、代表的な検索精度向上の手法を紹介します。
Ranking: 検索結果の順位付けを再評価し、最適な情報を上位に提示します。Re-RankやRankLLMなど、特にLLMや専用モデルを用いたリランキングは効果的です。
Refinement: 検索結果を洗練し、情報の一貫性と品質を向上させます。取得した文書を「関連」「曖昧」「非関連」などに分類し、それぞれのカテゴリに応じて文書を改善するCRAG(Corrective Retrieval-Augmented Generation)といった手法が知られています。
Active Retrieval: ユーザーのクエリやコンテキストに応じて動的に検索を最適化します。前述のCRAGは文書のカテゴリに応じて動的に検索を行うためActive Retrievalの1つとなります。
3-6. 応答最適化(Response Optimization)
対応目的: 「2. 応答品質」強化
対応原因: 「④応答の一貫性」
RAGの最終ステップである「応答生成」は、検索された情報を基にユーザーに最適な回答を提供する重要なプロセスです。この段階では、検索精度と生成モデルの品質が融合し、正確で文脈に沿った回答が生まれます。特に、自己改善型の生成手法を取り入れることで、さらに一貫性と正確性の高い応答が可能になります。以下に、代表的な応答最適化の手法をご紹介します。
Active Retrieval: 検索プロセスと生成プロセスを統合し、動的かつ適応的な応答生成を可能にします。Active Retrievalの手法の1つであるSelf-RAGではクエリに応じた文書検索の必要性判断や生成品質のチェック機能があり、ハルシネーションの抑制や回答品質の向上が期待できます。
4. まとめ
今回RAGのビジネス適用に向けたパフォーマンス改善をテーマに、改善の目的、原因、改善手法について紹介しました。
既にノーコードでRAGを構築可能なプラットフォームも出てきておりますが、開発したRAGシステムを実際にユーザが利用しその真価を発揮するまでには継続的な改善は必要不可欠であると言えます。今回取り上げた内容を元に、ぜひご自身でも取り組んでいるRAGシステム開発・運用の参考となれば幸いです。