
Agentic RAG Chatbotのアーキテクチャーとコンポーネント

1. RAGの限界とAgentic RAGの必要性
こんにちは。Weights & BiasesのHyunwoo Oh(linkedin)です。従来のRetrieval-Augmented Generation (RAG) は、言語モデル(LLM)が外部データベースから関連情報を検索し、その情報を基に回答を生成する方式であり、一般的なLLMよりも事実性を高め、ハルシネーションを抑制する効果があります。しかし、RAGは単一の検索・生成プロセスに依存するため、複雑な質問に対する深層的な推論が難しく、検索された情報が不足または不正確な場合、自動的に補完することができないです。 特に、検索と生成が一回限りのプロセスとして進行するため、追加の情報探索や多段階推論が必要な場合、ユーザーが手動で検索クエリを修正したり、結果を手作業で組み合わせる必要があるという不便さがあります。
Agentic RAGは、従来のRAGの情報検索および生成機能に、自律的な目標設定と反復的な探索・推論機能を組み合わせた概念であり、より精密なワークフローを可能にすることで、複雑な問題解決を支援します。従来のRAGは、与えられたクエリに対して一度の検索と生成を行うのに対し、Agentic RAGは特定の目標を達成するために必要なサブタスクを自律的に分割し、検索と生成のプロセスを繰り返しながら、中間結果を評価し、適切な意思決定を行う構造を持ちます。このプロセスでは、エージェントが情報の信頼性を検討し、追加の検索が必要かどうかを判断し、タスクの優先順位を調整するなどの役割を果たします。これにより、RAGが持つ単純な情報検索ベースの回答生成モデルを超え、より複雑な思考プロセスが求められる問題においても、効果的な自動化を実現できます。
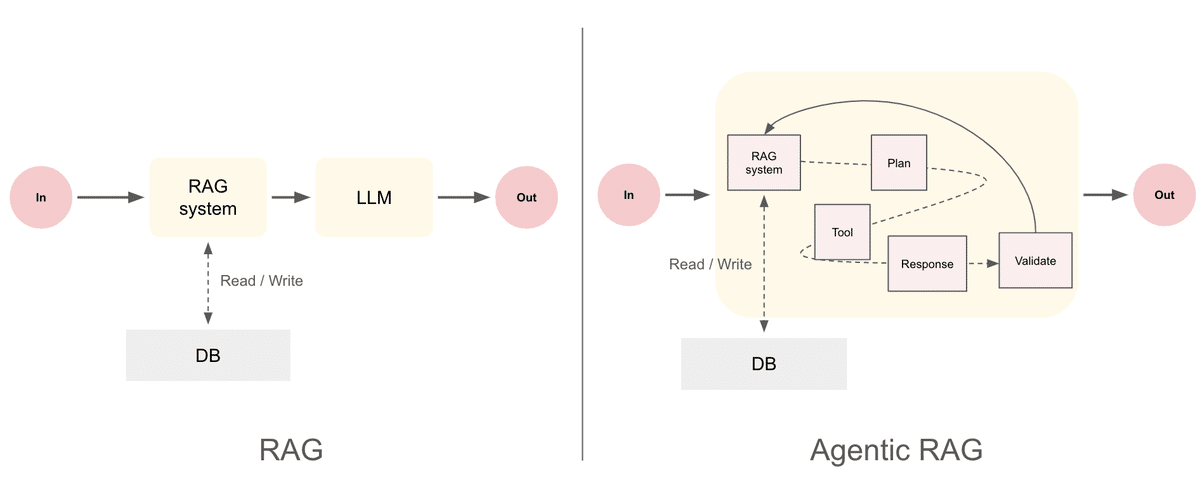
2. Agentic RAG Chatbotの主な考慮事項
Agentic RAGは、従来のRAGに自律的な目標設定と反復的な探索・推論機能を組み合わせることで、より複雑な問題解決を可能にします。しかし、その一方で新たな倫理的・技術的課題が発生します。例えば、検索エラーの蓄積、情報の偏り、機密情報の保護、自動化された検索のセキュリティリスクなど、安全性に関する問題を慎重に考慮する必要があります。また、検索品質の向上、プランニングとオーケストレーションの最適化、コスト・パフォーマンス管理といった技術的な課題も解決しなければなりません。
2.1 検索品質最適化
Agentic RAGの核心は反復検索に基づく意思決定であるため、検索品質がパフォーマンスの重要な決定要素です。ベクトルDBやインデックス技法などの最適化を通じて検索速度と精度をバランスよく維持する必要があり、単純なキーワードマッチングではなく、状況に合わせた動的検索クエリ生成機能が必要です。このため、LLMを活用したquery rewritingを適用し、元のユーザークエリをより精巧に調整できるようにすることが必要です。また、検索された文書の重要度を再調整するdocuments re-rankingを行うと、より有意義な情報を優先的に活用することができます。
反復的な検索-推論構造で発生する可能性のある主な問題の一つは、初期検索エラーの拡散です。初期検索段階で誤った情報が含まれると、その後の過程でこれを事実と仮定し、エラーが累積される危険性があります。したがって、検索された文書の信頼度を評価し、複数のソースを活用して情報の正確性を検証する機能が不可欠です。
2.2 プロンプトエンジニアリング・コンテキストの管理
Agentic RAGは伝統的なRAGよりはるかに複雑な検索/生成過程を経るため、プロンプトエンジニアリングが性能と安定性を決定する重要な要素です。単純な質疑応答モデルではなく、目標達成のための詳細戦略を自動的に設定するエージェントなので、初期プロンプトで役割、目標、実行ルール、検索範囲などを明確に定義する必要があります。また、検索ソースを制限して不要なデータを参照しないように誘導することも重要です。
コンテキスト管理もAgentic RAGの性能を最適化するために重要な要素です。従来のRAGは単発的な検索後に応答を生成しますが、Agentic RAGは複数の段階を経て段階的に情報を拡張し、結果を改善します。このため、長期メモリ(Long-term Memory)と短期メモリ(Short-term Memory)の役割を明確に区別し、情報の維持及び廃棄戦略を設定する必要があります。長期メモリは、セッション終了後に主要な情報を保存し、継続的なコンテキストの保存を可能にし、短期メモリは、特定のセッション内で検索された情報を維持し、自然なコンテキストの流れを保証します。
2.3 モニタリングと評価プロセス
Agentic RAGは単純な検索・生成モデルではなく、反復的な検索と推論を行うシステムであるため、入出力データと実行過程を体系的に記録・分析するモニタリングプロセスが必須である。検索段階でどのようなクエリが生成され、どのような文書が検索され、最終的な回答がどのような根拠に基づいて導き出されたかを追跡できる必要があります。特に、Agentic RAGは検索-生成ループが何度も繰り返される可能性があるため、Trace Loggingを活用して各段階での意思決定経路を記録・分析することが重要です。
また、体系的な評価プロセスを構築することがAgentic RAGモデルのアップグレードの核心要素である。単純な正解・不正解方式の評価ではなく、検索された情報の信頼性、検索および応答の多様性、最終生成結果の品質、モデルの意思決定過程の妥当性などを含む多層的な評価体系を適用する必要があります。例えば、Agentic RAGが特定の情報を検索する過程で過度に多くの検索要求を実行したり、不要な文書を多数参照しながらも精度が向上しない場合は、検索戦略を最適化しなければなりません。逆に、検索クエリが過度に制限的で重要な情報を見逃している場合は、クエリ拡張のための追加的な戦略を導入することができます。
3. Agentic RAG Chatbot
この章では、Agentic RAG Chatbotを実際にどのように実装し、運用できるかをアーキテクチャの観点から見ていきます。前章で説明した検索品質の最適化、プロンプトエンジニアリングとコンテキストの最適化、モニタリングと評価プロセスなどの考慮事項がどのようにシステム構成要素に溶け込むかを具体的に説明し、社内の各種データベース(内部文書、FAQ,報告書など)を対象としたAgentic RAGチャットボットを紹介します。
3. 1 コンポーネント


3. 2 Single Agentic-RAG Chatbot
まず、Single Agentic RAGを活用したチャットボット開発の事例を紹介します。Single Agentic-RAG Chatbotシステムは、単一のエージェントが全体のプロセスと担当し、ユーザーからの問い合わせに応じて必要な情報を収集する仕組みです。社内文書データを用いたSingle Agentic RAGチャットボットでは、1つのエージェントがユーザーからの問い合わせ(Query)を受け取り、必要に応じて複数のツールやデータソース(Vector検索エンジンやWeb検索、メモリストアなど)を呼び出し、結果を集約したうえでLLMに渡して最終回答を生成します。
このような構造の利点は、アーキテクチャがシンプルであることです。単一のエージェントがすべてのロジックを管理するため、開発と運用が比較的容易で、デバッグやロギングも簡単です。一方、すべての複雑さを一人のエージェントが担わなければならないため、タスクの分割や並列処理に制約があり、特定のドメイン別に最適化されたエージェントを別に置くことが難しく、拡張性の面でも限界を感じることがあります。結局、小規模のプロジェクトやドメインが単一の場合はSingle Agentic RAGが有利ではあるものの、多様なデータソースと複雑なタスクを同時に処理しなければならない状況では負担が大きくなる可能性があります。

3. 3 Multi Agentic-RAG Chatbot
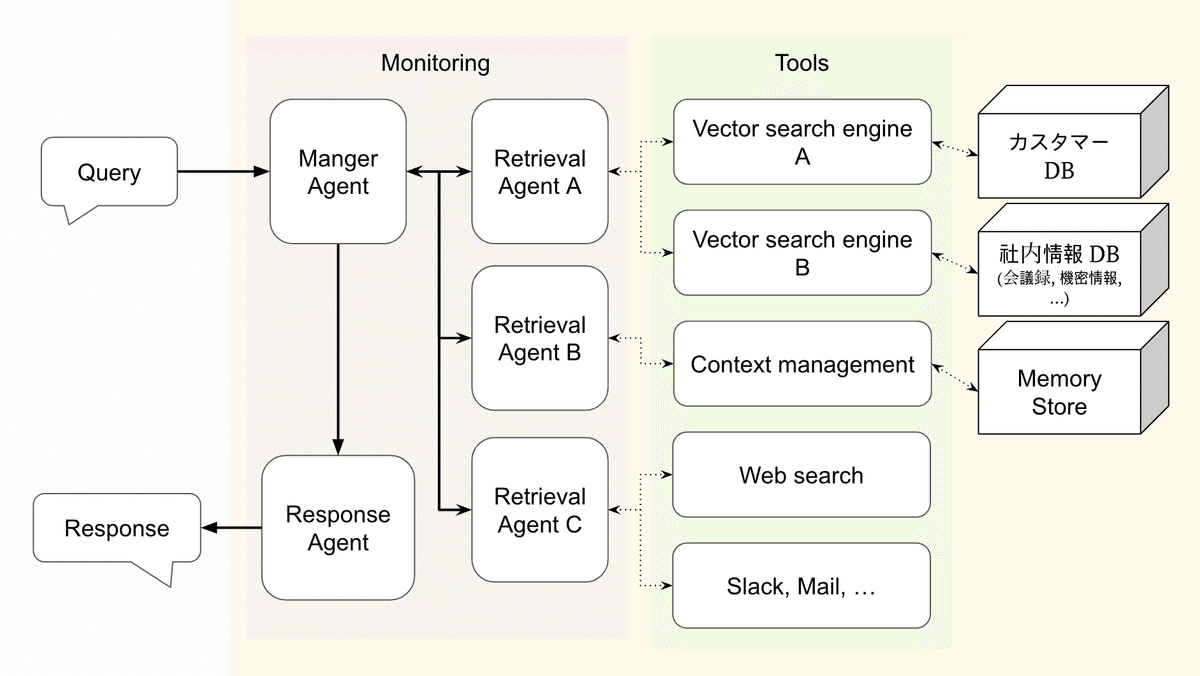
Multi Agentic RAGシステムは、複数のエージェントを並列または分業形態で運営する構造で、ユーザーの問い合わせを受け付けた上位マネージャーがRetrieval Agent A、B、Cなど複数のエージェントにサブタスクを分割します。例えば、Retrieval Agent Aは内部ベクトルDBのカスタマーDB、社内情報DBに特化した検索を担当し、Retrieval Agent Bは今回のセッションの情報を記憶してユーザーの個人化された情報を提供します。また、Retrieval Agent Cは、外部Web Searchを通じてリアルタイムデータを取得し、Slack、Gmailなどと連動して会話履歴やメール内容を収集・分析します。このように役割を明確に分配することができます。各エージェントはLLMと直接・間接的に相互作用し、自分が見つけた情報や中間成果物をLLMに伝えて最終回答に合成されるようにします。
このような分業化された構成は、ドメインの専門性を最大化し、複数のソースを並列に処理することで、検索速度を上げたり、より豊富な情報を得ることができるという利点があります。新しいデータソースやツールが追加された場合でも、その領域だけを担当するエージェントを追加・交換することで拡張が容易です。しかし、エージェントが複数になるにつれて、システム全体の複雑度が大幅に増加し、エージェント間の通信と同期、中央管理の必要性が高くなります。 また、エラーが発生したときにどのエージェントで問題が発生したかを追跡するのが容易ではなく、リソースが分散され、コストやリソース使用量が増加する可能性があるという欠点が存在します。その結果、Multi Agentic RAGシステムは、複数の専門的なエージェントを協業させて大規模なデータを扱わなければならない場合に便利ですが、初期実装と運営が複雑になることを考慮する必要があります。
4. Observability システムの構築と活用
Agentic RAGが複合タスクを多段階で実行するため、システム運用段階でも膨大な量の検索・生成ログとメタデータが蓄積されます。この情報を適切に管理・分析することができなければ、モデル改善、性能安定化、エラー対応策の策定など、高いレベルの洞察を得ることができません。特に、すべての入出力を追跡可能にし、結果的な行動を透明に管理する'Observability'体系を構築することが核心です。
最近、多くの企業がML運営プラットフォームまたはObservability製品(例えば、Weights & Biases Weave)を通じてAgentic RAGの入出力(Trace)と中間意思決定を記録し、これをダッシュボード・レポートの形で視覚化し、開発・運営チームが簡単に分析できるようにしています。このようなソリューションを導入すると、以下のような利点が期待できます。
4.1 システムの透明性確保
Agentic RAGは検索・生成過程を複数回繰り返し、各段階ごとに意思決定が行われます。Observabilityプラットフォームを通じて、Agentic RAGが各段階でどのような検索クエリを発行したのか、どのような文書を検索・分析したのか、そしてどのような理由で生成モジュール(LLM)を呼び出したのかをTraceの形で自動記録すると、エージェントの意思決定の「ブラックボックス」領域が大幅に減少します。これは、モデルの品質と信頼性に対する疑問を迅速に解消し、問題発生時に正確な原因分析を可能にする重要な基盤となります。

4.2 ガードレール(Guardrail)機能による安定性の向上
Agentic RAGは自律的な意思決定を行うため、誤った検索結果を信頼したり、偏ったデータを採用し、回答を歪めるリスクがあります。Observabilityプラットフォームが提供するガードレール機能(事前定義されたルール、ドキュメントフィルタリングポリシー、有害コンテンツ検出など)により、中間段階で「危険信号」を検出し、意思決定をブロックしたり、警告メッセージを表示することができます。

4.3 体系的な評価による自信のあるアップグレード
システムをアップグレードしたり、検索・生成ロジックを変更する前に、運営中のAgentic RAGがどのようなタスクでどの程度の性能とコスト指標を示すかを明確に知ることが重要です。Observabilityプラットフォームを通じて定量的な指標(検索回数、成功率、エラー頻度、APIコストなど)と定性的なフィードバック(ユーザー満足度、専門家レビュー)を体系的に収集・分析することで、「どの部分を改善すれば性能が最も大きく向上するか」または「アップグレード後に実際の性能がどれだけ向上したか」を確認することができます。このような明確な根拠に基づいてモデルを改良することで、運営チームと意思決定者が「安定的にパフォーマンスを向上させることができる」という確信を持つことができます。

最後に
Agentic RAGは、従来の検索・生成方式を超え、複雑な問題解決のための自律的な意思決定能力を備えたインテリジェントシステムです。この記事で見てきたように、反復的な検索-生成ループを通じて、より豊かで洗練された回答を提供し、ガードレールとモニタリング機能を通じてエラーを事前に抑制したり、迅速に対応することができます。また、エージェントマネージャー、検索モジュール、ナレッジベース、生成モジュール、メモリストア、モニタリングおよび評価体系などの構成要素を有機的に組み合わせて設計・運営することで、事実ベースの応答と多段階タスクの実行という2つの課題を同時に解決できる強力なアーキテクチャを実装することができます。
ただし、大規模データベースのシステムが持つ個人情報保護、コスト・性能最適化、バイアス・倫理的な問題は依然として重要な課題として残っている。結局、どれだけ堅固で透明な運営・評価体系を設けるかによって、Agentic RAGが持つ潜在力は最大化され、これにより、企業・研究・サービス現場で以前よりはるかに強力なインテリジェントエージェントを活用する時代が開かれることが期待されます。