
【データ分析日必要な機械学習】スッキリわかる機械学習の練習問題:金融機関のキャンーペーン分析

超わかりやすいスッキリわかる機械学習ですが、一旦ちょうど真ん中くらいにそれまで学習した内容の集約のような形で、練習問題があります。
とある金融商品のおすすめキャンペーンを昨年に続けて、今年もやりたいと言う背景。しかし今年は、効率よくキャンペーンをして、顧客をゲットしたい!
と言う思いで、去年のデータを使って、どのようにしたら良いでしょうか?
という問題。
何をしなさいとか、どのように分析しなさいとは出てきません!!
なんと実践的な内容です!

ここで紹介することは、正解かどうか不明です。
答え合わせはまだなので!
では初めてみます!
まず、csv取り込んで、件数が何件有るか?
import pandas as pd
df.info()
27128件です。nullは何件あるでしょ?
df.isnull().sum()
durationだけが、7044欠損しています。なので埋めてみます。
これはちなみに、接触時の平均時間です。
これを、他の列のデータを使って、機械学習させてdurationを埋めてから、nullがなくなった状態で本番のyを出す学習をさせて答えをだします。
df.head()
このようなデータ。とりあえず、月と日にちが別々なのでまとめてdateの形にしたいと思います。
import datetime
def month(month):
timestamp = datetime.datetime.strptime( month , '%b')
timestamp_format = timestamp.strftime("%m")
return timestamp_format英語の月名称を数字に変換する関数です。
month_int = df["month"].map(month)MAP関数で関数を動作させて変換します。
日にちと、月を合わせたいので日にちもintからstrになります。
df["月"]=month_int
df["day"]=df["day"].astype(str)
df["月日"]="2020"+"-"+df["月"]+"-"+df["day"]
df.head()
月日ができましたがstrなので一応、date方にします。が!後からただのラベルにするので意味がないのですが^^;そして、月と日にちをintにします!が後から消すのですが、、、^^;
df["月日"]=pd.to_datetime(df['月日'])
df["月"]=df[["月","day"]].astype(int)durationをまず、Nanの無いものを使って機械学習しようと思います
後で、モデルを使うので埋めるNanのデータも切り分けておきます。
df_na = df.dropna()
df_null = df[df["duration"].isnull()]不要そうな"id","day","月","month"列を削除。
df_na =df_na.drop(["id","day","月","month"], axis=1)ほか必要そうなのをインポート
from sklearn.preprocessing import LabelBinarizer
from sklearn import preprocessing
import pandas as pd
import numpy as nplightgbmを使いたいのですが、文字やdateは変えないのでラベルエンコーディングします
label = ['job', 'marital',"education","default","default","housing","loan","contact","月日"]
for i in label:
le = LabelEncoder()
encoded = le.fit_transform(df_na[i].values)
df_na[i] = encoded 
分割パターンは1個のみで、交差検証はなしで学習します。
df_na_x = df_na.drop(["duration"], axis=1)
df_na_t = df_na["duration"]from sklearn.model_selection import train_test_split
x_train,x_valid,y_train,y_valid = train_test_split(df_na_x,df_na_t,test_size = 0.2)
x_valid = x_valid.sort_index(ascending=True)
y_valid = y_valid.sort_index(ascending=True)これは、後からプロットするので見やすくソートしてます。
必要であれば
pip install lightgbmと戸惑う可能もありあますので、他検索しlightgbmインストール方法確認してください。
import lightgbm as lgbカテゴリー変数です!とlightgbmにお知らせするため。
categories = ['job', 'marital',"education","default","default","housing","loan","contact"]lgb_train = lgb.Dataset(x_train,y_train,categorical_feature =categories)
lgb_eval = lgb.Dataset(x_valid,y_valid,categorical_feature = categories,reference = lgb_train)そしてパラメータ
lgbm_params = {
"objective":"regression",
"random_seed":123
}最後パラメータの確認するために準備
models = []
rmses = []
oof = np.zeros(len(df_na_x))結果は実数と予測の数値を二乗法の平均でみてみますので
from sklearn.metrics import mean_squared_log_error
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10)
model_lgb.feature_importance()予測に効いた項目をグラフに表示してみたい
importance = pd.DataFrame(model_lgb.feature_importance(),index=x_train.columns,columns=["importance"]).sort_values(by="importance",ascending = True)
importance.plot.barh()
年齢がと最終解答項目のyも効いているみたいな、、、
yを予測するのにy使っても、、、と思ったけれど、durationは大体でもいいし、、、今後これが正しいかダメか学習で分かるはず!!
として、、、
from sklearn.metrics import accuracy_score
y_pred = model_lgb.predict(x_valid,num_iteration=model_lgb.best_iteration)
tmp_rese =np.sqrt(mean_squared_log_error(np.log(y_valid),np.log(y_pred)))
models.append(model_lgb)
rmses.append(tmp_rese)
oof= y_predスコアを確認
sum(rmses)/len(rmses)0.02128098197941121
となりました。300とか400とかの予測の中でそれぞれの差の二乗の平均が0.02ってそこそこ良さそうな、、、
ということでどれだけあっているかグラフでも見てみたい
actual_pred_df = pd.DataFrame({"actual" : y_valid,
"pred" : oof})
actual_pred_df.plot(figsize = (12,5))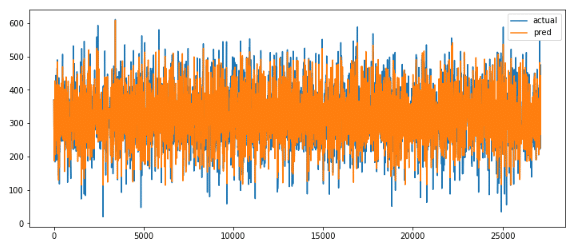
青が答え、橙色が予測。
かなりいい感じで重なっていそう。。。
ということでここまで!
後日続きはがんばります!