
AivisSpeechを有効的に使いたい - 入力データの作成まで

先日、AivisSpeechという日本語音声合成エンジンを試したところ、文字入力した小説の一節を朗読させても、技術記事の読み上げさせても、かなり自然な発音に驚きました。
良い使い道を検討したところ、以下のようなものを作ったら、暮らしに潤いが増すのではと考えました。
ボイスチェンジャー
ニュース記事の朗読
Amazon Audibleのような小説の朗読
AivisSpeechを起動状態するとAivisSpeech EngineからPythonなどで外部から必要な情報を与えますと、音声ファイルを出力できます。このとき必要となる入力は以下の情報です。
話す内容(テキスト)
話し手の感情
そこで今回はAivisSpeechに与えるデータを加工したいと思います。
1.音声情報をテキストに変換する
1-1.Whisperがかなり進化した
AivisSpeechの入力はテキストですので、朗読させたいテキストファイルがあれば良いのですが、朗読させたい内容が音声のときは、これを一度テキストに変換する必要があります。
これには以前も試したOpenAIのWhisperを使います。特に2024年末にリリースされたwhisper-large-v3-turboは解析が速く、正確で、必要なVRAMも少ない(6GB)ということで今回はこちらを採用しています。
今回の開発環境は以下のとおりです。
OS:Windows11(24H2)
Memory:32GB
GPU:Geforce RTX3060Ti(VRAM:8GB)
Python:v3.11.9
CUDA:v12.4
以降は導入手順を紹介したいと思います。
1-2. Pythonコードの実行環境
今回はPython言語で動作するため、パソコンで動く環境を設定する必要があります。この記事ではv3.11.9を使います。
ダウンロードしたインストーラーをダブルクリックしてInstall Nowを押せば良いのですが、以下の部分だけチェックを入れて環境変数PATHを自動登録しておきます。

1-3. PyTorchが使うCUDAバージョンを確認
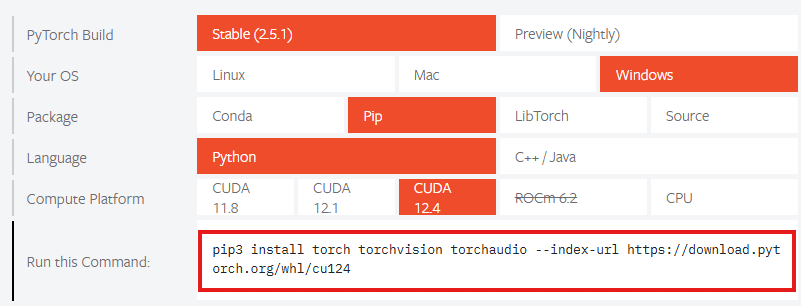
まずPytorchのページに飛び、使っているパソコンに合わせて項目を選択します。Compute Platformに書かれている内容が対応するCUDAのバージョンになりますので、これを控えておきます。
今回はv11.8,12.1,12.4に対応しているということですのでCUDA v12.4を導入したいと思います。
1-4. CUDA+cuDNNを導入
インストールするCUDAのインストールファイルをダウンロードします。対応するバージョンのCUDA Toolkitをクリックしてパソコンに合わせてインストーラーをダウンロードします。今回の環境は「CUDA Toolkit 12.4.0」です。ダウンロードしたCUDA Toolkitはダブルクリックしますとインストールされます。それ以外の設定は不要です。
次にcuDNNをダウンロードします。下記リンクの「Download cuDNN Library」を押してファイルをダウンロードします。
ダウンロードしたcuDNNをダブルクリックしてインストールすれば完了です。
1-5. Pytorchのインストールコマンドを確認
CUDAに対応したPytorchをコマンドプロンプトやWindows Power Shellでインストールします。すでにCUDA用でないPytorchをインストールしているようでしたらPytorchを「pip uninstall torch」でアンインストールします。インストールされたライブラリの確認は「pip list」で行います。
Pytorchのインストールコマンドは下図の赤枠に表示されます。
1-6.Pythonライブラリを導入
今回のPythonプログラムで使用するライブラリを一気に導入します。上で紹介したPytorchのコマンドも含んでいます。
pip install git+https://github.com/openai/whisper.git
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install transformers
pip install protobuf
pip install fugashi
pip install unidic-lite
pip install sentencepiece1-7.FFmpegを導入
音声ファイルをPythonプログラムで読み込むときに参照しますので導入します。
今回セットアップしているWindowsでは、インストールだけでなく、環境変数を手動追加する必要があります。詳細は「FFmpeg インストール windows11」などで検索いただくと、いくつも紹介されていると思います。
2.テキストの感情を解析し、その情報を追加する
テキスト化した文節を基に感情を分類するため、日本語言語モデルである「LINE DistilBERT」をファインチューニングした感情分類器「Japanese to emotions」を使います。
サンプル音声は以下の課題指向対話音声をダウンロードして使いました。
音声ファイルをwhisper-large-v3-turboで文字起こしして、これをJapanese to emotionsで感情分類するPythonプログラムは以下のようになります。
# 必要なライブラリのインポート
import whisper
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
from torch.nn.functional import softmax
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
# CPUかCUDA(GPU)をデバイスとして設定
device = "cuda"
# Whisperモデルの読み込み(高速な'turbo'モデルを使用)
whisper_model = whisper.load_model("turbo")
# 感情分析用のトークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained("koshin2001/Japanese-to-emotions")
model = AutoModelForSequenceClassification.from_pretrained("koshin2001/Japanese-to-emotions").to(device)
# 音声ファイルの文字起こしと分割
segments = whisper_model.transcribe("task-smp.mp3")["segments"]
segments_text = [seg["text"] for seg in segments]
# 分析対象の感情ラベルを定義
emotion_labels = ["喜び", "悲しみ", "期待", "驚き", "怒り", "恐れ", "嫌悪", "信頼"]
def analyze_emotions(texts, tokenizer, model):
"""
テキストの感情分析を行う関数
Args:
texts: 分析対象のテキストのリスト
tokenizer: テキストのトークン化に使用するトークナイザー
model: 感情分析モデル
"""
# テキストをモデル入力形式に変換
inputs = tokenizer(
texts,
padding=True, # テキストの長さを揃える
truncation=True, # 長いテキストを切り詰める
return_tensors="pt" # PyTorch形式で返す
)
# BERTモデル特有のtoken_type_idsを削除(必要ない場合)
if "token_type_ids" in inputs:
del inputs["token_type_ids"]
# デバイスに入力データを移動
inputs = {k: v.to(device) for k, v in inputs.items()}
# モデル推論を行い、感情スコアを取得
with torch.no_grad():
outputs = model(**inputs)
# 感情スコアをソフトマックス関数で確率に変換
probabilities = softmax(outputs.logits, dim=1)
return probabilities.cpu().numpy()
# 音声セグメントごとに感情分析を実行
emotion_scores = analyze_emotions(segments_text, tokenizer, model)
print("音声の感情分析結果:\n")
for i, (text, scores) in enumerate(zip(segments_text, emotion_scores)):
print(f"セグメント {i+1}:")
print(f"テキスト: {text}")
print("検出された感情:")
emotion_pairs = list(zip(emotion_labels, scores))
sorted_emotions = sorted(emotion_pairs, key=lambda x: x[1], reverse=True)
for emotion, score in sorted_emotions:
if score >= 0.05:
print(f" {emotion}: {score:.3f}")
dominant_emotion = emotion_labels[scores.argmax()]
print(f"主要な感情: {dominant_emotion}")
print("-" * 50)これを実行しますと初回起動はwhisper-large-v3-turboとJapanese to emotionsのダウンロードがありますので少し時間がかかりますが以下のように表示されます。
音声の感情分析結果:
セグメント 1:
テキスト: 開けます
検出された感情:
期待: 0.842
喜び: 0.109
主要な感情: 期待
--------------------------------------------------
セグメント 2:
テキスト: 僕の方には写真が入ってる
検出された感情:
喜び: 0.717
驚き: 0.129
主要な感情: 喜び
--------------------------------------------------
セグメント 3:
テキスト: 私の方は名前と一言っていうのが入ってます
検出された感情:
信頼: 0.322
喜び: 0.146
期待: 0.136
悲しみ: 0.109
驚き: 0.098
嫌悪: 0.093
恐れ: 0.069
主要な感情: 信頼
--------------------------------------------------
セグメント 4:
テキスト: 知らない人がいっぱいいるぞ
検出された感情:
驚き: 0.901
主要な感情: 驚き
--------------------------------------------------
セグメント 5:
テキスト: 名前じゃあちょっと読み上げてくるんで
検出された感情:
期待: 0.639
喜び: 0.107
驚き: 0.064
嫌悪: 0.050
主要な感情: 期待
--------------------------------------------------
セグメント 6:
テキスト: 平野レミ
検出された感情:
喜び: 0.388
驚き: 0.200
信頼: 0.123
悲しみ: 0.090
期待: 0.089
嫌悪: 0.074
主要な感情: 喜び
--------------------------------------------------
セグメント 7:
テキスト: お料理研究家の人
検出された感情:
驚き: 0.566
期待: 0.159
信頼: 0.081
嫌悪: 0.062
悲しみ: 0.057
主要な感情: 驚き
--------------------------------------------------
セグメント 8:
テキスト: メガネかけててショートカット
検出された感情:
喜び: 0.664
驚き: 0.215
主要な感情: 喜び
--------------------------------------------------
セグメント 9:
テキスト: 平野平野ノッパラですか
検出された感情:
驚き: 0.513
期待: 0.276
喜び: 0.148
主要な感情: 驚き
--------------------------------------------------
セグメント 10:
テキスト: レミはカタカナです
検出された感情:
驚き: 0.244
期待: 0.189
信頼: 0.165
嫌悪: 0.116
悲しみ: 0.108
喜び: 0.103
恐れ: 0.057
主要な感情: 驚き
--------------------------------------------------
セグメント 11:
テキスト: セルジオエチゴ
検出された感情:
喜び: 0.494
期待: 0.194
悲しみ: 0.076
信頼: 0.073
嫌悪: 0.073
驚き: 0.057
主要な感情: 喜び
--------------------------------------------------
セグメント 12:
テキスト: わかんないセルジオエチゴって誰
検出された感情:
嫌悪: 0.267
驚き: 0.249
悲しみ: 0.232
怒り: 0.117
恐れ: 0.083
主要な感情: 嫌悪
--------------------------------------------------次回はこの文字と感情の情報を基にAivisSpeech Engineに入力したいと思います。対話式の音声は、誰が話しているかも分類しないといけない気がしました。これも次回以降に検討したいと思います。