
Stable Diffusionを試せる4つの方法

こちらの記事を投稿してから約1年経って、紹介しているプログラムも動かなくなっていました。そこで2023/7/6に全面的に書き直しました。
Stable Diffusionを4つの方法で試してみましたので今回記事にしました。結論を先に書きますと、おすすめは3番目のGoogle Colaboratoryだと思います。
4番目のパソコンに設定する方法は対応するパソコンを持っていれば、使い道も広がると思いますが、とにかく手軽な3番目を最初はおすすめします。
1.Stable Diffusion Demoを利用する
ブラウザに作成したい画像のキーワードを入力すると画像を生成してくれるページです。サインイン不要、無料で利用できます。ただし画像生成までに相応の時間が掛かります。
2. Leonardo.Aiを利用する
様々な画像生成サービスのなかでも後発のサービスで、無料プランでも1日あたり150枚の画像を生成できます。
3.Google Colaboratoryを利用する
ご自身で画像生成モデルを選びたいということでしたら、Google Colaboratoryを利用する方法があります。Google ColaboratoryはGoogleが機械学習の教育及び研究用に提供しているインストール不要かつ、すぐにPythonや機械学習・深層学習の環境を整えることが出来るサービスです。こちらを行うためにはGoogleアカウントが必要です。
3-1. Googleアカウント
すでにGmailのメールアドレスを持っていたり、Androidのスマートフォンを使ったことがある方はお持ちだと思います。まずはGoogle Colaboratoryにアクセスします。
3-2.Google Colaboratoryのファイルを作る
Google Colaboratoryをブラウザで開きましたら、ファイル -> ノートブックを新規作成で新しいファイルを作成します。
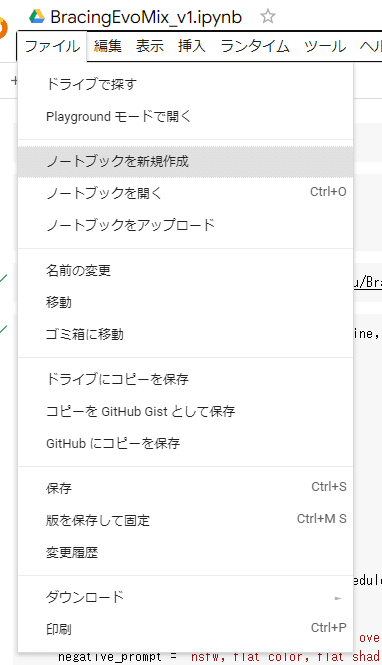
新規作成できましたら編集 -> ノートブックの設定を選択します。
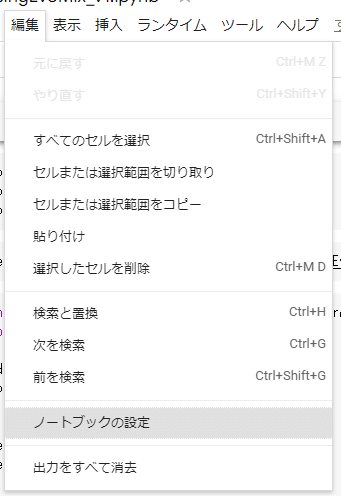
ハードウェア アクセラレーターをGPUに変更します

コードを書いていきます。画像生成のコードだけでなく、環境構築ライブラリの導入も行います。

上の画像のコードは以下の通りです。点線が入っているところを1セルとして設定して順次実行していきます。
!nvidia-smi
--------------------------
!pip install diffusers
!pip install transformers
!pip install omegaconf
--------------------------
!wget https://huggingface.co/sazyou-roukaku/BracingEvoMix/resolve/main/BracingEvoMix_v1.safetensors
--------------------------
from diffusers import StableDiffusionPipeline, EulerAncestralDiscreteScheduler
import torch
from diffusers import StableDiffusionPipeline, EulerAncestralDiscreteScheduler
import torch
model_id = "BracingEvoMix_v1.safetensors"
pipe = StableDiffusionPipeline.from_ckpt(
model_id,
load_safety_checker = False,
extract_ema = True,
torch_dtype = torch.float16)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.load_textual_inversion("sayakpaul/EasyNegative-test",weight_name="EasyNegative.safetensors", token="EasyNegative")
pipe.to("cuda")
---------------------------
prompt = "((masterpiece:1.4, best quality)), ((masterpiece, best quality)), (photo realistic:1.4), woman, female, Beautiful face, happy, smile, bright eyes,"
negative_prompt = "Easy Negative (worst quality:2) (low quality:2) (normal quality:2) lowers normal quality ((monochrome)) ((grayscale)),nsfw, flat color, flat shading,retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text"
generator = torch.Generator(device="cuda").manual_seed(123)
image = pipe(
prompt = prompt,
negative_prompt = negative_prompt,
generator = generator,
num_inference_steps = 35,
guidance_scale = 7.0,
width = 768,height = 768,).images[0]
image
---------------------------
CUDAに対応したnvidia製のGPUを持っていなくても、本格的な環境を無償で試せます。初回の環境設定や学習モデルの導入を行えば画像生成の時間もPCとさほど変わりません。
4.パソコンを利用する
自宅のパソコンのGPUを使って画像を生成します。開発側からはGPU RAMは10GB以上必要と書かれています。手持ちのGPU RAMが8GBでしたので半ば諦めていたのですが、「使用可能なGPU RAMが10GB以下の場合、デフォルトのfloat32精度ではなく、float16精度でStableDiffusionPipelineをロードしてください」と書いてありましたので、こちらもWindows11のパソコンで試すことにしました。
パソコンでStable Diffusionを動かすためには以下の設定の変更と環境作成を行う必要があります。
Windowsを開発者モードを設定
NVIDIAアカウント / NVIDIA Developer Programメンバーシップに登録
Pythonコードの実行環境
PyTorchが使うCUDAバージョンの確認
CUDA+cuDNNの実行環境
Stable Diffusionの実行環境
Google Colaboratoryとパソコンの違いは処理速度と実際の画像生成時間を確認したところ、Google Colaboratoryで17秒かかる画像生成がパソコンでは9秒程度で生成されます。あるプロンプトを連続して画像生成したいということでしたらGoogle Colaboratoryよりもパソコンで環境を作った方が良いと思います。
4-1. Windowsを開発者モードを設定
Stable Diffusionで使う自然言語処理ライブラリのTransformersをインストールするために設定が必要です。Windows11の場合は「設定」 -> 「プライバシーとセキュリティー」-> 「開発者向け」にある「開発者モード」をOnにすればよいです。
4-2. NVIDIAアカウント/ NVIDIA Developer Programメンバーシップに登録
CUDAの拡張ライブラリであるcuDNNをダウンロードするときに登録が必要です。
4-3. Pythonコードの実行環境
Stable DiffusionはPython言語で動作するためパソコンでPython言語を動くように設定する必要があります。v3.11.4を使っています。
ダウンロードしたインストーラーをダブルクリックしてInstall Nowを押せば良いのですが、以下の部分だけチェックを入れて環境変数PATHを自動登録しておきます。

4-4. PyTorchが使うCUDAバージョン確認
まずPytorchのページに飛び、使っているパソコンに合わせて項目を選択します。Compute Platformに書かれている内容が対応するCUDAのバージョンになりますのでこれを控えておきます。今回の場合はv11.7、11.8に対応しているということですのでCUDA v11.8を導入します。

4-5. CUDA+cuDNN実行環境
インストールするCUDAのインストールファイルをダウンロードします。過去バージョンに関しては以下のCUDA Toolkit Archiveから探します。対応するバージョンのCUDA Toolkitをクリックしてパソコンに合わせてインストーラーをダウンロードします。ダウンロードしたCUDA Toolkitはダブルクリックしますとインストールされます。それ以外の設定は不要です。

次にcuDNNをダウンロードします。Download cuDNNを押してライセンスに同意しますとCUDA v12.x用とv11.x用がダウンロードできますのでv11.xをダウンロードします。

ダウンロードしたファイルを解凍し、cuDNN内のcudaフォルダの中身をすべてCUDA Toolkitのインストールフォルダ(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8)にコピーします。
cuDNNはご自身で環境変数PATHを登録する必要がありますので、システム環境変数に新規で変数名「CUDNN_PATH」、値 「C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8」を追加して完了となります。
4-6. Stable Diffusion実行環境
CUDAに対応したPytorchをコマンドプロンプトやWindows Power Shellでインストールします。すでにPytorchをインストールしているようでしたらPytorchを「pip uninstall torch」でアンインストールします。Pytorchのインストールコマンドは、PytorchがどのバージョンのCUDAに対応しているか調べたときに表示されたRun this Commandに表示されたコマンドを実行します。

4-7. BracingEvoMixの導入
Hugging Faceからダウンロードします。いくつかファイルがありますが、BracingEvoMix_v1.safetensorsをダウンロードしました。サイズは2.13GBです。
4-8. ライブラリの導入とファイル配置
Pythonライブラリはdiffusersとtransformersが必要です。なお、ダウンロードしたBracingEvoMix_v1.safetensorsはPythonコードと同じパスに配置します。
pip install diffusers
pip install transformers4-9. BracingEvoMixで画像生成する
コードは以下のようにしました。(1)seedにシード値、(2)stepにステップ数(ノイズ除去を行う回数)、(3)scaleがプロンプトへの準拠度(高ければ高いほどキーワードに忠実)です。
(4)promptには生成したいキーワードを指定し、(5)negative_promptには除外したいキーワードを指定します。
外で作業をするときはドッキリする画像が生成されないようにnegative_promptにnsfwのキーワードを入れておきましょう。
from diffusers import StableDiffusionPipeline, EulerAncestralDiscreteScheduler
import torch
seed = 123
steps = 35
scale = 7.0
model_id = "BracingEvoMix_v1.safetensors"
pipe = StableDiffusionPipeline.from_ckpt(model_id, load_safety_checker = False, extract_ema = True, torch_dtype = torch.float16)
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.load_textual_inversion("sayakpaul/EasyNegative-test",weight_name="EasyNegative.safetensors", token="EasyNegative")
pipe.to("cuda")
prompt = "((masterpiece:1.4, best quality)), ((masterpiece, best quality)), (photo realistic:1.4), woman, female, Beautiful face, happy, smile, bright eyes,"
negative_prompt = "Easy Negative (worst quality:2) (low quality:2) (normal quality:2) lowers normal quality ((monochrome)) ((grayscale)),nsfw, flat color, flat shading,retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text"
generator = torch.Generator(device="cuda").manual_seed(seed)
image = pipe(prompt = prompt, negative_prompt = negative_prompt, generator = generator, num_inference_steps = steps, guidance_scale = scale, width = 768,height = 768,).images[0]
image.save(f"./step{steps}_seed{seed}.png")
引き続き、このコードをベースにGUIを追加し、オプション設定を反映できるよう改造していきたいと思います
パソコンに画像生成環境を作ってしまうため、一度構築すればサービスを無償で利用できます。カスタマイズについても使っているGPUの範囲内では柔軟に対応できますが、nvidia製のCUDAに対応したGPUが載ったパソコンが必要です。
5.まとめ
今回4つの方法で画像を作る方法を紹介してきまたが、Google Colaboratoryが手軽に始めるには良いと思います。使用しているGPUも非常に強力で、Pythonで動作させますので様々なカスタマイズができます。クラウド上で処理しているため操作する端末を選ばないことも魅力です。
今回はパソコンにセットアップしたので今回のコードをカスタマイズする方向で紹介させていただければと考えています。