
DICOM文法:VR

(お知らせ)日本語訳したVR表のリンクは、本解説の末尾に記載しています。
臨床データは、距離の単位はミリメートル、時間の単位は秒、患者名はアルファベットなど、様々なフォーマットで提供されます。
DICOM はこのような多様なフォーマットにどのように対応しているのでしょうか。
PS 3.5 では、あらゆる臨床データをDICOMで表現するために、VR(Value Representation; 値表現)と呼ばれる基本データタイプが定義されています(2023/1の執筆時点では34種類)。
AE;Application Entity
AS;Age String
AT;Attribute Tag
CS;Code String
DA;Date
DS;Decimal String
DT;Date Time
FL;Floating Point Single
FD;Floating Point Double
IS;Integer String
LO;Long String
LT;Long Text
OB;Other Byte
OD;Other Double
OF;Other Float
OL;Other Long
OV;Other 64-bit Very Long
OW;Other Word
PN;Person Name
SH;Short String
SL;Signed Long
SQ;Sequence of Items
SS;Signed Short
ST;Short Text
SV;Signed 64-bit Very Long
TM;Time
UC;Unlimited Characters
UI;Unique Identifier (UID)
UL;Unsigned Long
UN;Unknown
UR;Universal Resource Identifier or Universal Resource Locator (URI/URL)
US;Unsigned Short
UT;Unlimited Text
UV;Unsigned 64-bit Very Long
DICOMとして記録されるものは、このVRのいずれかのタイプに一致させる必要があります。見ての通り、各VRには、2文字の略称があり、この他、何を表すかの定義、データに使用できる文字およびデータ長が設定されています。
このあたりが、やや、難解です。DICOMを複雑だと思わせる要因の一つは、VRかもしれません。
ここから、VRについての重要なことについて説明していきます。
VRで定められているデータサイズ(VR length)
VRはDICOMの中に含まれるデータのデータ型を定義するものですが、データサイズ(VR長, VR length)はこの定義の中で非常に重要な位置を占めています。
DICOMは2つの方法ですべてのデータサイズを記録しています。
第一に、DICOMはデータ値と共にデータサイズを記録しています。これが、DICOMで各データ要素の開始と終了を知る方法です。
第二に、VRの表にあるように、いくつかの VR ではデータ長が固定または制限されています。
VR の定義で定められているデータ長の制限は、医用画像処理ソフトウェアでは見過ごされることがあります(私もよくやります、、反省)。これはDICOMに多少なりとも準拠しているプログラム間で容易に非互換性を生じさせる原因になるでしょう。
(私は、自作プログラムをDICOMに準拠させるために、すべてのVRデータを正しいサイズでフォーマットできること、また他のDICOMアプリケーションから送られてきた不適切なサイズのVRを読み込むことができるようにしたいです。いつになるやら、、大変や、、。)
DICOM ソフトウェアの開発者が VR の長さに注意しなければならないもう一つの理由は、バイナリ数値の VR に関連するものです。
ビッグエンディアンとリトルエンディアンの場合と同様に、コンピュータシステムあるいはソフトウェアごとに、基本的な数値データ型(整数、浮動小数点数など)に異なるサイズが使用されている場合があります。
このように、DICOMのVRによるデータ長の規定は、コンピュータのハードウェアやソフトウェアの設計の違いから DICOM データを保護するものでもあります。
DICOMに含まれるデータが固定長かどうかにかかわらず、すべてのDICOMデータ要素は、偶数文字または偶数バイトで表現されます。
VR が文字列で構成される値は、VR UI を除き、必要に応じて SPACE 文字(Default Character Repertoire の 20H)でパディングを行い、偶数長にします。VRがUIの値は、偶数になるように必要に応じて末尾にNULL(00H)文字を1個付加します。VRがOBである値は、末尾をNULLバイト値(00H)でパディングされなければなりません。
このように、DICOMでは奇数サイズのテキスト文字列にはブランクスペース1文字を追加、奇数サイズのバイナリ文字列(OBなど)にはヌルバイトを追加して長さを偶数にしています。
例えば、John^Doeという名前は、8文字ですのでそのままJohn^DoeでOKです。一方で、"Smith^Joe"という名前は、9文字で奇数ですので、常に"Smith^Joe+半角スペース"として、末尾にスペースが追加され、長さが10に調整されます。
DICOMデータの偶数長パディングは、ある意味では利点とみなすことができます。データの健全性を確認するためのパリティ・チェック(サイズの異なるものを破損していると見なすためのチェック)に使用することができるからです。
多くのDICOMアプリケーションは他のソフトウェアと組み合わせて使用されることが多いため、末尾にパディングされたブランク(トレイリング・ブランク)の無視やトリミング忘れのエラーは気をつけなくてはなりません。
例えば、Smith^Joe としてDICOMに保存されていたものが、"Smith^Joe "(Smith^Joe+半角スペース)として取り出されることになります。
これは、多くの人には同じに見えるかもしれませんが、DICOM の偶数長のパディングを認識していないソフトウェアでは、別の名前または別の患者として簡単に誤解する可能性があります。
DICOMデータをデコードすると同時に、DICOMデータをトリミングするように設定されていれば、このようなことは起こらないというわけです。
文字列
DICOMアプリケーションのユーザーが母国語のDICOMデータを使いたいと思うのはごく自然なことです。これを実現するために、DICOMはローカライゼーション(国際化)をサポートしています。また、VRごとに使用できる文字も、選択する言語によって異なります。
DICOM では、この部分を「文字レパートリー(Character Repertoire)」と呼んでいます。
現在のDICOMデバイスのほとんどはラテンアルファベットを使用しています(ISO IR-6のDICOMデフォルトの文字レパートリーです)。
ISO IR-6は歴史的にみても、標準的に使用された最初の文字レパートリーであり、多くの外国語に適切に利用できることが多いです。
英語圏ではない場合、ラテン語以外の文字セットを実装して利用します(例えば、漢字を使いたいときはISO-IR 87など)。
様々な言語に加え、DICOM の特定の文字は予約された意味を持つので、ルールに従って使用する必要があります。
特に、DICOMでは、テキスト文字列のワイルドカードによるマッチングが可能です。
アスタリスク(*)ワイルドカードは任意の文字列を、クエスチョンマーク(?)ワイルドカードは任意の1文字を、バックスラッシュワイルドカードは "または" を表します。
例えば、過去のCTまたはMR検査を検索する必要がある場合、'CTまたはMR' モダリティを意味する文字列を"CT\MR"として検索できます。
一般に、ワイルドカードは有利に働きます。患者名を完全に覚えていない場合でも、最初の数文字に続けてアスタリスクを入力すると、類似するすべての一致を検索することができます。
DICOMソフトウェアで「Ko*」と入力すると、「Kobayashi」、「Koike」などに一致するはずです。
(しかし、ワイルドカードは正しく用いなければDICOMエラーを招く原因なる可能性があります。例えば、開発者が思いもよらぬ箇所に、ユーザーが誤って「?」マークを入力したDICOMデータを作成したり、バックスラッシュを含めてはいけないDICOMデータエレメントにバックスラッシュを含めてしまうなどが考えられます。)
テキストに対応したVR(略してテキストVR)
テキストVRは、テキストの文字列を保存するためのものなので、簡単です。
必要な処理も少ないです(ただし、他のアプリケーションにエクスポートする際に、最後にある厄介な空白を切り取ることは除きます)。
テキストVRについて唯一重要なことは、データ長の制限を知ることです。
例えば、CS VRが 16文字までしか保持できない場合、この制限を1文字でも超えると、小さなソフトウェアエラーを引き起こす可能性があります。
データ長のチェックは DICOMソフトウェアで行われるのが望ましいでしょう。制限を超える文字列はトリミングされるか、より長い VRタイプで扱うことです。
時間に対応したVR
DA、TM、DTのVRは、日付と時刻をテキスト文字列の形式で保存します。
これらについて最も重要なことは、日付または時刻の構成要素の正しい順序を知ることです。
また、古いACR-NEMAのバージョンでは、ピリオドとコロンで区切られた若干異なる日付と時刻のフォーマットを使用しています。例えば、時刻の文字列で、現在のDICOMバージョンでは183200と書きますが、ACR-NEMAでは18:32:00と記述します。後方互換、ちょっと気にした方がよさそうですね。
DAとTMタイプは使い分けに悩むことがあります。本当にDTタイプであるべき属性が、ときにDAとTMの属性に分割されてしまうなどが、設計上、起こりえます。
例えば、患者の誕生日属性はDAタイプ、患者の出生時間属性はTMタイプによって扱われるなどです。実際、これは患者の生年月日属性(DT VR)として、年月日と時刻を1つの属性に保存した方がスマートです。
1つの情報を複数の属性に分割すると、属性の同期という問題が生じます。一方を変更すると、もう一方も更新しなければならない状況が起こりうるわけです。
次に、タイムゾーンについてです。
2008年以降、DT VRでは、タイムゾーン情報を&ZZXXのコンポーネントとしてサポートするようになりました。
例えば、米国東部標準時のオフセットを-0500、日本標準時のオフセットを+0900と表現します。
タイムゾーンに関しては、ゾーンレスなローカルエリアシステムで、同じ病院内の2、3のモダリティで運用されるケースでは問題にならないのですが、遠隔画像診断が複数の国や大陸にまたがるようになり、場合によって、タイムゾーンの取り扱いについて注意すべきシーンも増えています。
DT VRは、DICOMユニットと世界標準時刻を同期させてることにも役立ちます。
また、DICOMの生真面目さにちょっとクスッとすることを紹介します。
不思議なVRがあります。AS VRです。
なぜDICOM VRにASが必要なのかと聞かれれば、実はよくわからないのです。
5000以上ある現在のDICOM属性のうち、AS VRを使用しているのは2つだけです(患者年齢と、あまり見かけない専門的なタグ(0072,005F) Selector AS Value)。
患者の年齢を知るには、患者の生年月日属性(DAタイプ)で十分です。ほとんどのPACSは、患者の検査時点の年齢や現在の年齢を知るために、生年月日を利用しています。
数値のVR
ISおよびDS VRは、数値(整数および浮動小数点)をテキスト文字列として保存します。
なぜわざわざそうするかというと、テキスト形式の数値はDICOMで頻繁に使用されるためです。
バイナリ形式よりも便利な理由は、
まず第一に、フォーマットされた数値は、ビッグエンディアンやリトルエンディアンのバイトオーダーに依存しません。
第二に、読みやすく、どのようなインターフェースでも「そのまま」表示することができます。
このような理由から、テキスト形式の数値は、人間が入力し解釈する「実世界」から記録されるデータに対してよく使われます。
患者の身長や体重を記録するのが良い例です。
バイナリ形式のVR
基本的には先述のISやDSのテキスト型と同じ数値を扱いますが、文字ではなく、バイナリ形式で扱います。なので、VRテーブルの文字レパートリーは「Not applicable」となっています。
SS、US、SL、UL、FL、FDなどは単一の数字を表すのに使われます。
OB, OW, OF, ODは長い数値の保存に使われます。画像ピクセルの列などです。
画像ピクセルの場合、ピクセル単位の各数値は同じバイトサイズ(OB, OW, OF, ODそれぞれ1,2,4,8バイト)であり、それらはすべて長いバイナリ系列として連結されることで表現されます。
OBが1バイト、OWは2バイト、OFは4バイト、ODは8バイトですから、OW、OF、ODはビッグエンディアンやリトルエンディアンのバイトオーダーに影響されます。
ついでに、ATも確認しておきます。
ATは2バイトの数値のペアを格納するためのVRです。
ATは、すべてのDICOM属性の(グループ、エレメント)タグに対応します。したがって、ATは、他のバイナリ数値型VRとは異なり、DICOMデータの属性を列挙するためのみに使用されます。
PN -Person's Name-
PN VRは人名を符号化するためのVRです。
名前全体(ファースト、ラスト、ミドルなど)が1つのPN VRに対応する属性に記録されます。
記録の際、ある程度のルールが必要です。
John ManjiroなのかManjiro Johnなのか、これは重要な違いです。表記する上で間違いなく問題が発生します。
そこで、DICOMでは、人名の構成要素(コンポーネント)に、次のような順番を規定しています。
姓コンポーネント^ 名コンポーネント^ ミドルネームコンポーネント^ 名前の接頭辞コンポーネント^ 名前の接尾辞コンポーネント
すべてのコンポーネントは、キャレット(^)文字で区切られます。
しかし、多面的な医療環境では、この順番が乱れることが多く、情報の永続的な損失や患者の誤認識が発生することがあります。
日本語や中国語のような表意文字で書かれた外国語の名前には、ラテン語の表音文字が含まれることがあります。
この場合、異なる名前の転写、つまり異なるコンポーネントグループは、等号(=)文字で区切られます。John^Manjiro=ジョン^万次郎のように。
名前を用いた検索方法は自由度が高いため、DICOMはソフトウェアの実装に任せています。
アプリケーション・エンティティ:AE
AE VRは、DICOMアプリケーション・エンティティを表すためのフォーマットです。
AEは、基本的にDICOM機器やプログラムを一意に識別するための名前です(PACSネットワーク内のモダリティやソフトウェアを区別するために用いられるため、同一ネットワーク内に、同じAE値を持つ複数のモダリティを設定できません)。
このため、AE は DICOM ネットワークやPACSにとって重要なVRの1つとなっています。
DICOMは、AEの命名に厳密な要件を設けていませんが、アプリケーション・エンティティは通常、数字と大文字のみで表し、その他の、スペース、句読点、文字は使用しません。
これにより、大文字・小文字を区別する名前を使用することが避けられるようになっています。MazingerZとMAZINGERZの違いを区別することができます。
AE名の選択は自由ですが、アプリケーション・エンティティとして役割をもつDICOM機器の機能や場所に合わせて、明示的でわかりやすいタイトルがつけられることが多いと思われます(64列CTなら、CT64、または、1階にあるMRIならMR1FLOORなど)。
UI - Unique identifiers
UI VRは、主にDICOMデータ(オブジェクト)の特定のインスタンスを識別するために使用される一意の識別子を符号化するためのフォーマットです。
先に述べたAEでは、ローカルネットワーク内のみで一意であることが必要ですが、DICOMユニーク識別子(UIまたはUID)は、いつ、どこで使用されてもグローバルに一意である必要があります(世界に一つであるということです)。
例えば、DICOMデータをあるDICOMユニットAから別のユニットBにコピーする場合、ユニットBは、同じ検査の別のインスタンスを扱っていることを強調するためにStudy UID属性値を変更する必要があります。
このようにすることで、ユニットB内へコピーされたインスタンスの何かを変更しても、元の検査データの変更と混同されることはありません。
UI名は、ピリオドで区切られた数字のグループ("コンポーネント")で表現されます。
DICOMには、UI名の表記について、不思議な規則があります。UIの各構成要素の最初の桁は、その構成要素が1桁でない限り、0であってはならないというものです(なあんだってええええ!岸部〇伴)。
例えば、UI=1.2.804.114118.2.0909は不正です。最後のコンポーネント0909が0から始まっていて、かつ、4桁あるためです(マナー違反ですヨ。マナーが大事なんです。マナーマナー。はい、すみません。岸部〇伴にノリ過ぎました)。
UI=1.2.804.114118.2.0はOKです。最後は0ですが、一桁なので。
SQ - Sequencing Data
SQ VRは、データセットのSequence(シーケンス)をエンコードするためのVRです。シーケンスに含まれるセットは複数のデータ属性を含むことができます。
このVRは、最も複雑なDICOM構造と言ってもいいです。なぜなら、DICOMデータに階層という構造をもたらすからです。属性を属性の中に入れ込むことが可能です。
この機能は、類似した要素をまとめるというよりも、意味のある複数の属性を1つのデータブロックにまとめたい場合に使います。
DICOM標準規格では、シーケンシングの有無は、大なり記号(>)で示されます。
例えば、次のような DICOMデータに遭遇したとします。
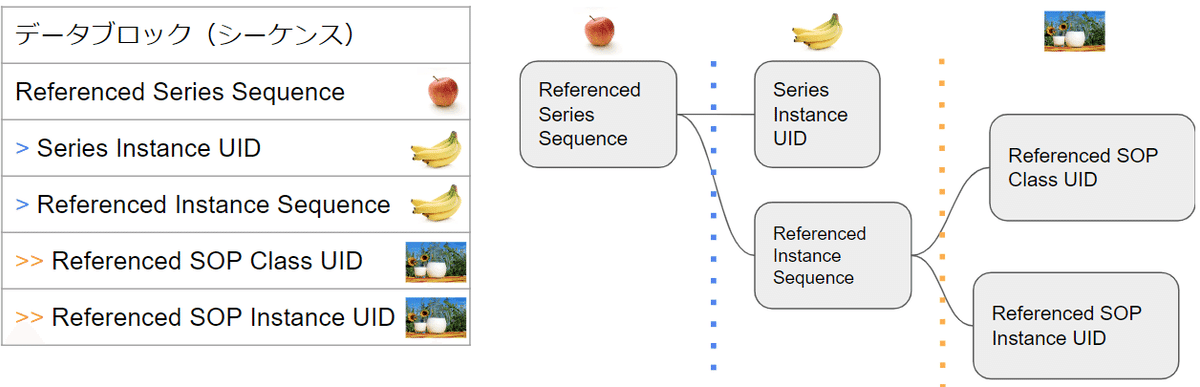
この例では、最初のReferenced Series Sequence属性の後に、大なり記号(>)を持つ2つの属性が続いていることがわかります。これはReferenced Series Sequence属性がSQ VRであるため、シーケンス属性として、Series Instance UID属性とReferenced Instance Sequence属性を含んでいることを意味しています(バナナの階層)。
さらに、Referenced Instance Sequence属性の後に、二重の大なり記号(>>)を持つ2つの属性が続いています。これはどういうことかというと、Referenced Instance Sequence属性も同様にシーケンス属性であり、後に続く2つの属性、Referenced SOP Class UID属性とReferenced SOP Instance UID属性の2つの属性を含んでいるといわけです(ミルクの階層)。
このように、Referenced Series Sequence属性は、自身の第1レベル(リンゴの階層)のシーケンスから、そのサブシーケンスを含めて、全部で4つのサブ要素を含んでいます。
このように、SQ VRでフォーマットされるシークエンス属性は、いくつかの属性が、そのルートとなる属性から分岐するために利用され、複雑なDICOMデータツリーを形成することを助けます。
このようにSQでツリー状に属性をネストする場合は、SQ属性のVRデータ長が適切に計算される必要があります。
例えば、この例でのルート属性であるReferenced Series SequenceのVRデータ長は、ネストした属性のデータをすべて含むように計算されます。この計算方法などは別の機会に解説します。
UN - 未知の値を表現する
UN VRは、未知の値を符号化するためのフォーマットです。UNは、他のVRに当てはまらないものに使用されます。
最も一般的には、UNはメーカー固有の(プロプライエタリ)データのために予約されており、「標準的に」は、解釈できるものではありません(メーカが分かればいいもので、みんなが分かる必要がないもの)。
DICOMアプリケーションの開発者は、おそらく、可能な限りUN VRは使用していないと思われます。
第一に、他のVRは(おそらく)すべてのデータ型を表現します。
第二に、属性タイプをUnknownとすることは、データタイプを定義するためのVRという構造的アプローチとしては、目的地から遠ざかっているように思えます。
例えば、ビッグエンディアンとリトルエンディアンのバイトの並べ替えを考えてみます。
UNな属性では、データがバイナリかテキストか、あるいは並べ替えが必要なのかどうかが分からず、本当はこのような処理が必要な場合でも、適切な処理を行うことはできません。
まとめ
さて、ここまで書いて、私は悟りました。
VRの文法を隅々まで記憶するようなスポンジのような頭脳や写真的な記憶力は私にはなかったと(おそらく、今の記憶も、Beerによって薄れていくでしょう)。
しかし、基本的なことは覚えておけるかなと、楽観的に考えられることもありますけれど。
VRは、DICOMのデジタル世界と、現実世界とをつなぐために、DICOMデータの構造化において最も重要な役割を担っています。
VRは我々とDICOMが、会話するための言葉のようなものです。
言葉を学ぶには、まずは語彙力が必要です。我々の現実世界のデータ項目をどのように属性に変換するのでしょうか。
次回!DICOMデータ辞書の登場です(MC、じゃじゃーん!って効果音であってる?)。
VR Table(日本語訳済み)のリンク
Stay Visionary