
CODEFUSION: A Pre-trained Diffusion Model for Code Generation

代官山のカフェについて
先日、勉強しようと夕方一人で代官山のカフェ「Ivy Place」に行ってきました。
メニューも素晴らしいし綺麗なところですが、カップルが多く店内も薄暗くしてムードを出していて、とても反実仮想機械学習の勉強をするPlaceでは無いなと感じました。
筆者も彼女と一緒に行きたいですね。
まずは彼女を作るところから頑張りましょう。
概要
CODEFUSION: A Pre-trained Diffusion Model for Code Generation
written by Mukul Singh, José Cambronero, Sumit Gulwani, Vu Le, Carina Negreanu, Gust Verbruggen
published on Wed, 1 Nov 2023(v3)
[Abstract]
Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do not easily allow reconsidering earlier tokens generated. We introduce CodeFusion, a pre-trained diffusion code generation model that addresses this limitation by iteratively denoising a complete program conditioned on the encoded natural language. We evaluate CodeFusion on the task of natural language to code generation for Bash, Python, and Microsoft Excel conditional formatting (CF) rules. Experiments show that CodeFusion (75M parameters) performs on par with state-of-the-art auto-regressive systems (350M-175B parameters) in top-1 accuracy and outperforms them in top-3 and top-5 accuracy due to its better balance in diversity versus quality.
[Abstract(翻訳)]
コードを書く際に最後の1行しか修正できない開発者がいたとして、その関数を正確に仕上げるために最初から書き直す頻度はどのくらいになるだろうか。自然言語からコードを生成する自己回帰型モデルには、すでに生成されたトークンを容易に再評価できないという似たような制約がある。この課題に対処するために、我々はCODEFUSIONを提案する。このモデルは、エンコードされた自然言語に基づいて、完全なプログラムを繰り返しノイズ除去することで動作する事前学習済みの拡散モデルである。CODEFUSIONを用いて、Bash、Python、Microsoft Excelの条件付き書式(CF)ルールといった自然言語からコードへの生成タスクを評価する。その結果、CODEFUSION(75Mパラメータ)は最先端の自己回帰型システム(350M〜175Bパラメータ)と同等のトップ1精度を達成し、トップ3およびトップ5精度ではこれらを上回る性能を示した。これは、CODEFUSIONが多様性と品質のバランスに優れているためである。
コンテンツ
自己回帰型コード生成モデルと拡散モデル
自己回帰型のコード生成モデルでは、テキストやコードの生成過程において既に生成されたトークンを後から再評価するのが難しいという制約がある。
一方で、画像生成において成功を収めてきた拡散モデルは近年ではテキスト生成にも応用されている。
しかし、コード生成のようにトークン間に強い構文的・意味的な制約がある場合は無効なプログラムを生成しやすくなってしまうという問題がある。
本研究では、自然言語からコードへの生成を目的とした拡散モデルである"CODEFUSION"を提案する。
このモデルは、「自然言語を連続的な表現に変換するエンコーダ」、「連続的な埋め込み表現にガウスノイズを加え、条件付きで段階的にノイズ除去を行う拡散過程」、「ノイズ除去後の埋め込みを用いて構文的に正しいコードを生成するデコーダ」の3つで構成される。
このモデルをPython、Bash、およびMicrosoft Excelの条件付き書式ルールといった多様な言語を対象に評価する。
アーキテクチャ
CODEFUSIONの主要コンポーネントは「エンコーダ」、「デノイザ」、「デコーダ」、そしてデコーダから得られる隠れ表現を離散的なコードトークンに変換する「分類ヘッド」の4つになる。
入力は自然言語の発話 $${\bm{s} = \{ s_1, s_2, \cdots, s_k \}}$$ であり、これをエンコーダでベクトル表現 $${E_{\bm{s}} = \{ e_1, e_2, \cdots, e_n \}}$$ に変換する。
そして、ノイズのかかったプログラム埋め込み $${\bm{x}^t}$$ と $${E_{\bm{s}}}$$ のクロスアテンション、 $${\bm{x}^t}$$ 全体のセルフアテンションを用いて $${\bm{x}^t}$$ からノイズを予測・除去し、プログラム埋め込み $${\hat{\bm{x}}^0}$$ を生成する。
このノイズ除去された $${\hat{\bm{x}}^0}$$ と $${E_{\bm{s}}}$$ を用いてコードトークンの隠れ表現 $${D_{\bm{s}} = \{ d_1, d_2, \cdots, d_n \}}$$ 計算する。
ここでは全ての隠れ次元が他の次元の情報を完全に利用できるようにセルフアテンションが適用される。
最後に、分類ヘッドでデコーダから得られる隠れ表現 $${D_{\bm{s}}}$$ を離散的なコードトークンに変換し、コードスニペット $${\hat{\bm{y}} = \{ \hat{y}_1, \hat{y}_2, \cdots, \hat{y}_n \}}$$ を出力する。

学習過程
CODEFUSIONの学習は、「教師なし学習として拡散過程におけるデノイザとデコーダを事前学習」と「教師あり学習としてエンコーダ、デノイザ、デコーダを自然言語とコードのペアでファインチューニング」の2つのフェーズに分かれている。
損失関数は次の式で表せる。
$${\mathcal{L}_t = || \hat{\epsilon}_t - \epsilon_t || + || D_{\bm{s}} - L(\bm{y})|| - \log p(\bm{y} | D_{\bm{s}})}$$
ここで、 $${\hat{\epsilon}_t}$$ は予測ノイズ、 $${\epsilon_t}$$ は実際のノイズ、 $${L(\bm{y})}$$ は元のコード埋め込み、 $${- \log p(\bm{y} | D_{\bm{s}})}$$ は予測コードトークン $${\hat{\bm{y}} = D_{\bm{s}}}$$ と正解コードトークン $${\bm{y}}$$ の交差エントロピー損失である。
推論
プログラム埋め込み $${\bm{x}^t}$$ をランダムなガウスノイズで初期化する。
続いて拡散過程を逆にたどりながらステップごとにノイズを除去していく。
ノイズ除去完了後、デコーダで最終的なコードトークンを生成する。
後処理として、生成されたトークン列をパディングトークンまで切り取ることで最終的なコードスニペットを完成させる。
ベンチマーク
CODEFUSIONの性能評価のために、自然言語からコード生成を行う3つの異なる言語タスクを選定した。
Python
StackOverflowから収集された複雑なマルチステートメントのコードスニペットと対応する自然言語の質問で構成されており、多段階のコード生成を必要とする高い複雑性を持つ。Bash
シングルラインのBashコマンドと対応する自然言語の説明で構成されており、コードが単一行であるためPythonよりも単純だが、シンタックスの厳密さが要求される。Microsoft Excelの条件付き書式ルール
Excelの条件付き書式ルールと対応する自然言語の説明で構成されており、コード生成の難易度は低いものの明確な構文ルールが必要である。
これらのベンチマークは、事前学習用のデータも含めて公開されている。
学習
モデルの構成としては、以下の通りである。
エンコーダ: 事前学習済みのCodeT5エンコーダ(埋め込み次元は512)
デノイザ: 10層のTransformerブロック
デコーダ: 6層のTransformerデコーダ
分類ヘッド: 1層の全結合層
学習のハイパーパラメータは以下の通りである。
ノイズスケジュール: 平方根スケジュール、拡散ステップ数は1200
トークナイザと語彙: CodeT5のトークナイザを使用
最大コード長: 128トークン
最適化器: AdamW(重み減衰無し)
学習率: $${5.0 \times 10^{-4}}$$
ベースラインと評価指標
CODEFUSIONの性能評価のため、複数の既存モデルをベースラインとして使用した。
TransformerベースのモデルとしてT5、CodeT5、GPT-3、ChatGPT、StarCoder、CodeGenを、拡散モデルとしてDiffusion-LM、GENIEを使った。
Python、Bash、Microsoft Excelの条件付き書式ルールそれぞれで評価指標を与え、「nグラムの多様性」、「埋め込みの類似度」、「文字列の編集距離」で評価を行った。
パフォーマンスと多様性
CODEFUSIONはトップ1精度においてGPT-3を除き、全てのベースラインモデルと同等以上のパフォーマンスを発揮した。
トップ3及びトップ5精度においては、全てのベースラインモデルを上回り、他のモデルよりも多様な候補を生成できることを示した。

多様性の観点からも、CODEFUSIONの生成結果は他のベースラインモデルよりも高いことが確認された。

また、CODEFUSIONは他の拡散モデルと比較しても、より有効なプログラムの候補の生成が可能であることが示された。
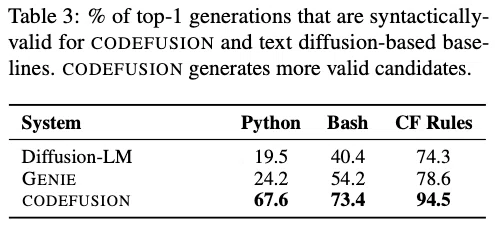
アブレーション分析
CODEFUSIONの異なる構成によって、パフォーマンスに影響があるかを調べる実験を実施した。
事前学習タスクを除去することで、Python、Bash、およびMicrosoft Excelの条件付き書式ルールの全てにおいて平均的な精度が低下したため、コード生成タスクと段階的なノイズ除去タスクがCODEFUSIONの性能向上に貢献していることがわかった。
また、デコーダや分類ヘッドをグラウンディング(最終的なノイズ除去ステップで最も近いトークンを選択する)やクランピング(各ノイズ除去ステップで最も近いトークンを選択する)といった簡易的な手法に置き換えても精度が低下することがわかった。

漸進的な改良過程の確認
CODEFUSIONがノイズ除去を通じてどのように最終コードを生成するかを、各タイムステップでノイズ除去を止めてコード生成をして計測した。
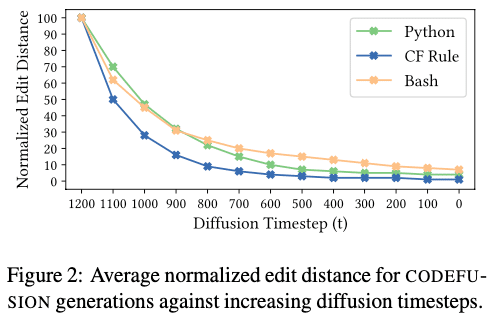
拡散ステップ数が増加するにつれて編集距離が減少し、生成結果が最終的なコードに近づいていることが確認できた。
また、Pythonタスクの例を用いて、ステップごとの生成コードを視覚化した結果、CODEFUSIONが徐々にノイズを取り除き、最終的に目標のコードに到達する過程が示された。

結論と制限
CODEFUSIONは自然言語をコードに変換する初の拡散モデルとして提案できた。
これは最新鋭のコード生成Transformerモデルと競うことのできる有用なモデルだと考えられる。
一方で、現在の制限として入力言語が英語に限られていることや、自然言語の入力が曖昧になると生成結果の品質低下を招く。
さらに、他の複雑なプログラミング言語やフレームワークに適用すると性能が低下する可能性もある。
また、長いコードスニペットの生成性能の向上や、推論速度と効率性を最適化が必要だと考えられる。
感想
初めての非量子分野での論文まとめでした。
コード生成を拡散モデルでやるっていうのは、まあわからんでもない、といった感じですが、今までこのような結果が出てきていないということはどういうことなのか…。
まあとりあえずやってみるっていうのは大事ですけどね。