
世界バレースライド作成の裏側①

こんにちは!お久しぶりです。ぱんだ(@vball_panda)です。
世界バレー盛り上がってましたね~~この各チームのバレオタが一堂に会す感じは祭りって感じでたまりませんね。
私も世界バレー期間中はスペースに参加させていただいたり、ちまちまTweetしたりして、かなりEnjoyさせていただきました。
ご存じの方もいらっしゃるかと思いますが、私のアカウントでは毎試合終了後に日本人選手の個人スタッツを投稿しておりまして、それなりに多くの反響をいただきました!ありがたい!!
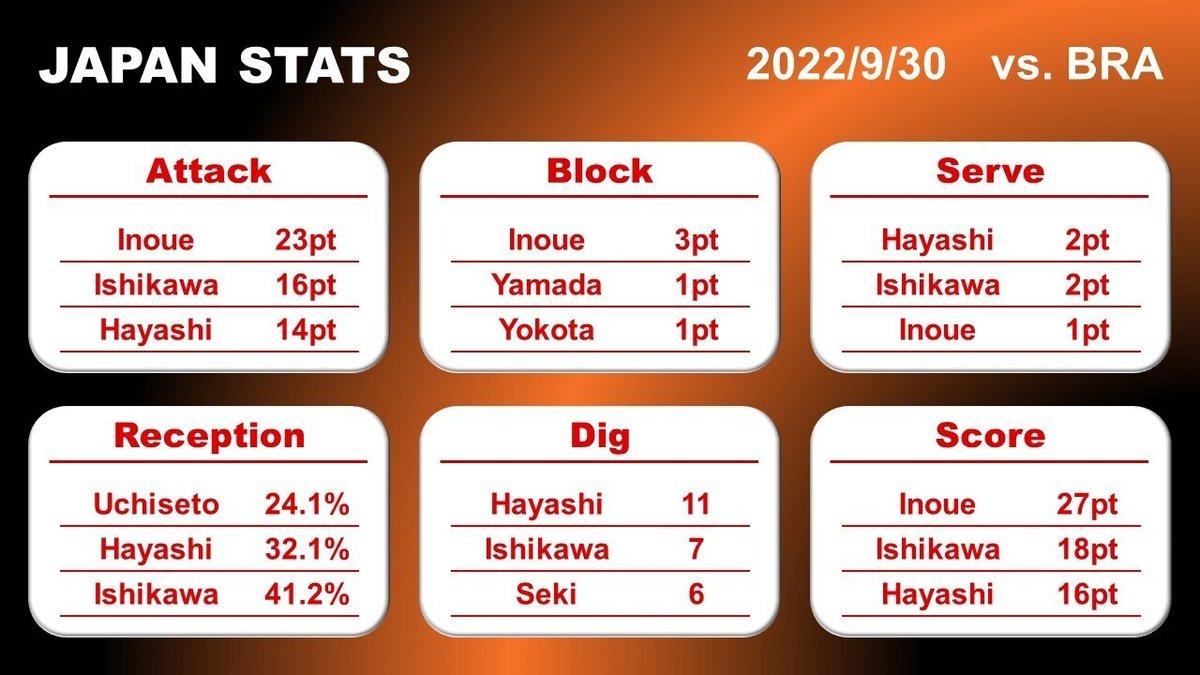
これはいつも通りプログラミングであーだこーだして作っているのですが、「いったいどうやって作ってるの?」と思われる方も1人くらいはいらっしゃるかもしれません。
というわけで今回は、バレオタ界にPythonの波が来ることを祈りつつ、個人スタッツスライド制作の過程を述べたいと思います!
(最初は一気に書こうと思ったのですが、いつも通り長くなったので全3回でお届けする予定です)
0.プログラミングとは?
そもそもプログラミングって何やねん!と思われた方。めちゃくちゃその気持ちよくわかります。
プログラミングの肝は、手動でやったら面倒な作業を、あらかじめ命令しておいた通りに自動でやってもらうことです。(もちろんできることは他にも無限にありますが!)
例えば、毎日の株価変動をExcelにまとめるみたいな仕事があった時に、毎日同じサイトで複数銘柄の株価チェックして、それをExcelに1個ずつ打ち込んで…って超面倒です。
「毎日指定した銘柄の株価をチェックする」のも「Excelに入力する」のも単純作業なので、人より機械の方が得意そうですよね。そのための命令を書く作業が、プログラミングだと私は解釈しています。
プログラミングの言語は有名どころだとJavaとかC++とかいろいろありますが、上でも述べた通り、私はPythonという言語を使っております。
プログラミング言語って何やねん!って思われた方、ここでは機械に命令するのに日本語を使うか英語を使うかみたいなイメージでよろしいかと。このPythonは最近流行りの言語でして、初心者にもとっつきやすいのが特徴!
もう一つ、「どこに命令を書いて、どこで実行する?」という問題もあります。さすがにPCのメモ帳にコード書いてEnter押したらOK、というわけにはいきません。
でも世の中には、とりあえずコード書いてEnter押したら実行してくれる、みたいな夢のような場所もあるんですね~~。私はそのような環境としてJupyter Notebookを使用しておりまして、1回インストールしたらその後は簡単にプログラミングができます。
ソフトのインストールさえ面倒という方はGoogle Colaboratoryという環境もありまして、こちらはGoogleアカウントさえ持っていればすぐに始めることもできます!
1.スライド作成の概要
少し長い前置きになりましたが、ここからが本題です。どうやってスライドを作っているのでしょうか?
まずは実際の流れを説明する前に、あのスライドを手作業で作ることを想像してください。
①FIVBのサイトに行ってスタッツを調べる
②パワポのスライドに選手名と数字を入力する
おおよそ、こんな流れではないでしょうか。
今回の肝は、①スタッツの取得 と②スライドへの転記 を自動化することです。これに関しては、コピー&ペーストのイメージで考えていただければと思います。
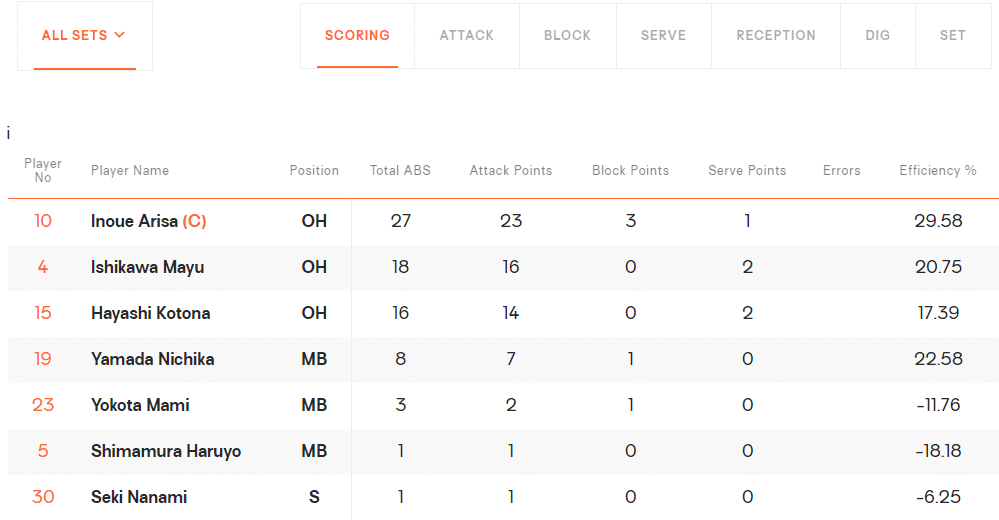
まず①ですが、スライドを作るために見るべき場所は毎回決まっていますね。「Box Score」の表の所です。要は表の内容を、まるでコピーするみたいに吸い上げればいいわけです。
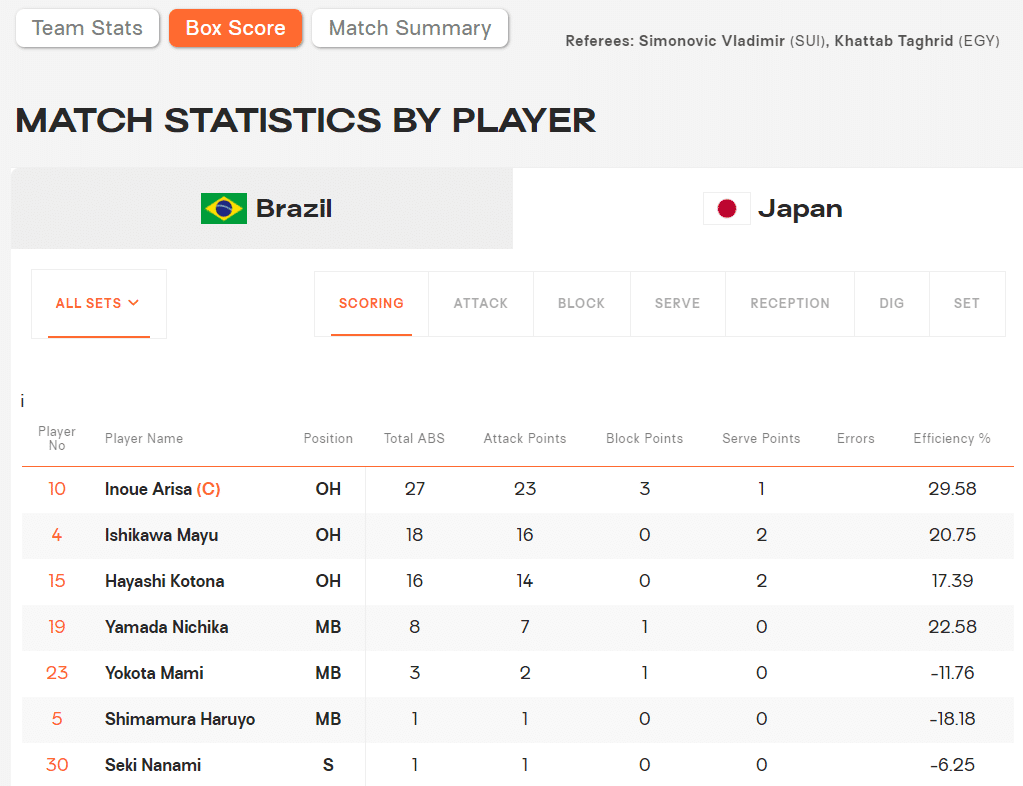
出典:FIVB
次に②ですが、要は先ほどコピーした内容を自動でペーストしたいということです。これもどこに貼り付けるか指定してあげれば、何とかなりそうですね。
ただし、ここで一つ問題があります。
FIVBのサイトで見たスタッツの表には、得点一つとっても「Attack」や「Block」など様々な項目があります。選手名もフルネームなので長いです。そもそも、どう考えても全員分はスライドに入らないですよね……
なのでここでは、上手いことスライドに入れるために、項目を減らしたり選手数を絞ったりして、データを整形しています。
というわけで、個人スタッツスライド作成のためには
①FIVBのサイトからスタッツ取得
②パワポのスライドに入るようにデータ整形
③整形したデータをパワポに転記
という3つの手順を踏む必要があります。
2.スタッツの取得
2-1.スクレイピングとは?
本章では、スライド作成の第一関門として、「外部サイトからのスタッツ取得」について説明します。ここでの目標は上でも触れましたが、Box Scoreの表の内容をコピペするみたいに全取得することです。
プログラミングでは割と鉄板のネタなんですが、ホームページの中身を取得することをスクレイピングと呼びます。英語の「scrape」は「剥がす、引っ掻く」という意味がありますが、文字通りホームページの中身を掠め取る(ハッキングではないですよ!)イメージですね。
ここでサラッと「ホームページの中身」と言いましたが、皆さん、ホームページの中身って見たことあるでしょうか。
Google Chromeをお使いの方は、右クリック→「検証」でページの中身を見ることができます。ホームページの文字の大きさ、配置、内容などは全部右のようなコード(HTMLといいます)で指定されています。
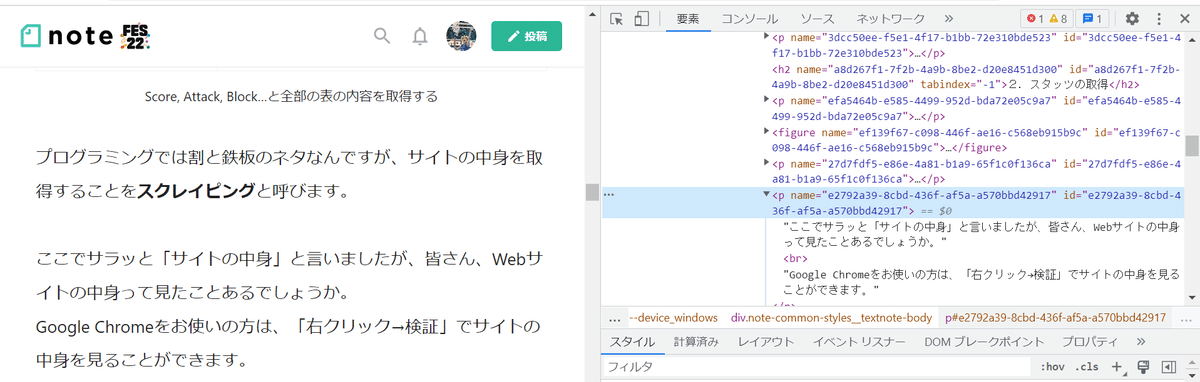
ページの右側に出てくるHTMLを見てみると、ほとんどは<>(タグと言います)で囲まれている部分で内容がないようですが(笑うとこです!)、よくよく目を凝らすと、黒文字で書かれてる箇所がわかりますかね?これがnoteに実際に表示される本文です。
ここまでホームページの中身について説明してきましたが、次に浮かぶ疑問は「スクレイピングでどこを取得するのか?」ではないでしょうか。
残念ながら答えは全部です。タグの部分も黒字の部分も全部。
ただほとんどの場合、ホームページの中でも本当に欲しい部分は限られています。見出しだけでいいとか、本文だけでいいとか。そもそもタグはいりませんね。
というわけで、スクレイピングするときには一回全部の情報を取得するのですが、その後に必要な所だけに絞り込む作業を行います。
ちなみに、前者の全部の情報を取得するときに使うのがSelenium、後者の必要な情報だけに絞り込むときに使うのがBeautiful Soupというライブラリです。
ここでライブラリって何?って思われた方のために説明しますと、例えば裁縫するためには裁縫道具が必要ですし、料理をするためには包丁がいりますよね。Pythonも同じで、サイトからデータを取得するための道具があると思っていただければOKです。
ちなみにこの後、表形式のデータを扱うライブラリ(pandas)やパワポ操作のためのライブラリ(Python-pptx)などいろいろ出てきます。
スクレイピングの概要的な説明はこれくらいにしますが、スクレイピングについてもっと詳しく知りたい方は、「Python スクレイピング」とかでググれば無限に出てくると思います。定番ネタとしてはヤフーニュースの見出しを取得したりしてますね。
2-2.実際の作業
今までプログラミングの概念的な話をしてきましたが、ここからはFIVBのサイトからスタッツを取得するための実際の作業について見ていきます。
上でも少し述べましたが、スクレイピング(ホームページ情報の取得)には大きく分けて2つのステップが必要です。
①最初に、目的のサイト全体の情報を取得する
②必要な情報だけに絞り込む
ではまず①から。
ここでは、PythonでスクレイピングをするためのライブラリであるSeleniumを使用します。このSeleniumは一言でいうと、遠隔でブラウザを制御できるライブラリです。
私の過去ツイを見た方はお気づきかもしれませんが、途中何回か、FIVBのサイトがいきなり立ち上がったのが見えますかね?(私が超スピードで検索したわけではありません)これをやってくれるのがSeleniumです。
https://t.co/oROhmEAb4s
— ぱんだ (@vball_panda) September 25, 2022
実はこのスタッツのやつは半自動化しました
日付とチーム名さえ入れれば、あとはFIVBのサイトからスタッツ取得→パワポの表に入れられるようにデータ整形→パワポに書き込み、までワンクリックでやってくれます
(自動化までに何時間かかったかはさておき...) pic.twitter.com/tAsE7DPEPu
それでは、Pythonのコードの方をちらっと見てみましょう。
#事前に必要なライブラリはimportしておく
#スクレイピングのメソッド定義
def getAllStats(home,away,URL):
#Selniumを起動
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
driver = webdriver.Chrome(service=chrome_service)
driver.get(URL)(以下、行数カウントはコードの部分だけ。コメント、行間は除外)
2行目~4行目がブラウザを立ち上げるためのコードです。
まず、SeleniumでGoogle Chromeを操作するためには、Pythonとは別にChrome Driverというツールをダウンロードする必要があります。詳しくはこちらのサイトに全部書いてありますが、Pythonのコード中では先ほど保存したChrome Driverのパスを指定します(2行目)。
ここまででChromeブラウザを立ち上げる準備ができたので、あとは実際にGoogle検索する時と同じように、ホームページのURLを渡してあげます(4行目)。
ここまで実行すれば、遠隔で制御できるブラウザが立ち上がるはずです!
Seleniumで立ち上げるとこうなります。
出典:FIVB
余談ですが、Pythonに詳しい方なら「何でrequestsじゃなくてSelenium使ってるの?」という疑問を持たれたかもしれません。鋭いですね。
実は、このFIVBのサイトはスクレイピング泣かせの仕様で、requestsだと上手く情報を拾ってくれないのです。
どういうことかと言いますと、このサイトによくアクセスされる方ならご存じかもしれませんが、ここの画面で「Team Stats」「Box Score」「Match Summary」を行き来するときって、画面全体が切り替わらずに表の所だけが遷移するんですね。
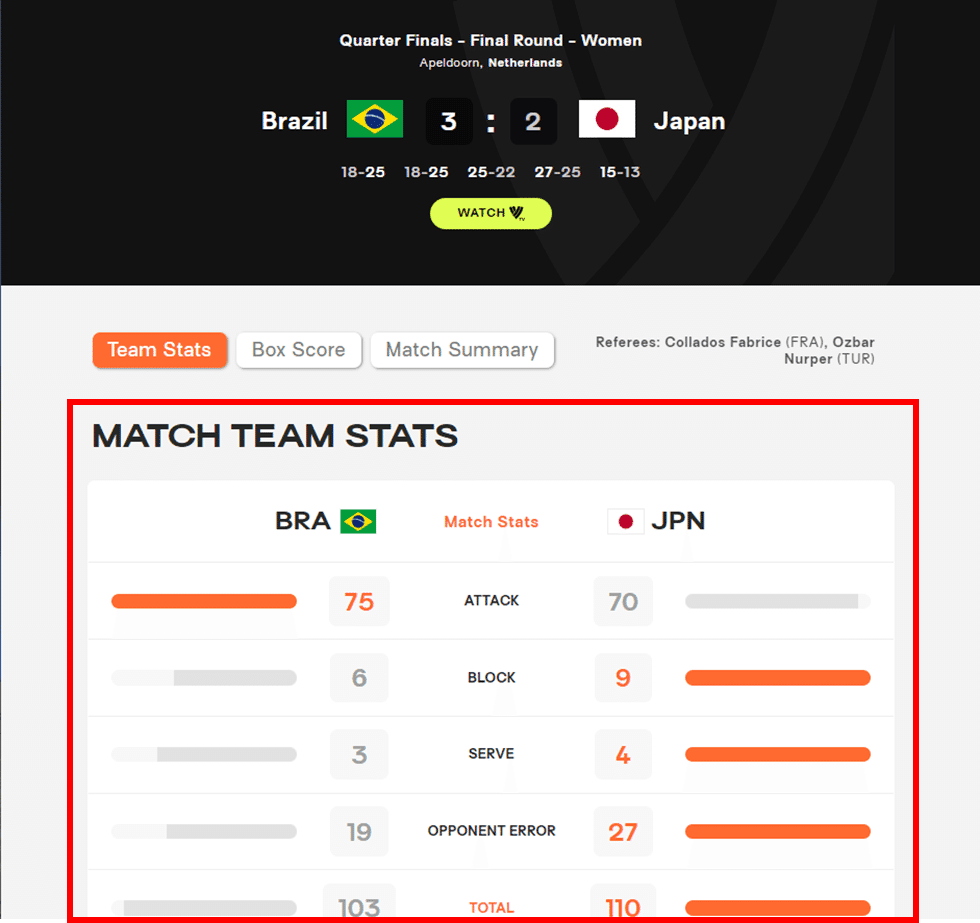
こういう、画面の一部だけが切り替わるようにする仕組みをajaxというんですが、このajaxとrequestsは致命的に相性が悪いんです。requestsだと、切り替わった先の情報を拾ってくれないんですね……
なので今回は、Seleniumで直接ブラウザを立ち上げて全部の情報を取得できるようにしています。
さてさて、ここまでで無事にSeleniumでサイトを立ち上げることができたので、最初に申し上げた手順通り、一旦サイト全体の情報を取得していきましょう。
ここでまたコードが出てきます。
#上の続き(getAllStatsメソッドの中身)
driver.implicitly_wait(10)
driver.find_element(By.CLASS_NAME,'tab-team-teamstats').click
text=driver.page_sourceブラウザを立ち上げて最初にやるのは、実は待つことです。
上で「Team Stats」「Box Score」の所だけが独立して切り替わるというように述べましたが、実はあの部分はサイトにアクセスしてから表示されるまでに、微妙に時間差があるんですね。
なので、ブラウザを立ち上げた瞬間にHTMLを取得してしまうと、先頭の黒い部分しか読み込んでくれない……なんてことが起きるわけです。
それを防ぐために、ブラウザを立ち上げてから最大10秒待って(1行目)、さらに保険として「Team Stats」ボタンを押す(2行目)という操作を入れています。「Team Stats」ボタンが押せれば、その時にはもう下の表がちゃんと表示されているはずなので。
ここまで準備をして、次にやるのがやっとこさサイト全体の情報の取得です。3行目のコードで、HTMLを上から下まで全部取得してあげます。

これで無事にサイト全体の情報が取得できたので、1stステップは終了です。
では次に、②の「必要な情報だけに絞り込む」ところに移りましょう。
ここで使うのがBeautiful Soupというライブラリです。このBeautiful Soupは何をしてくれるかというと、上で取得した延々と続くHTMLから、タグ(<>で囲まれた目印)を手がかりに欲しい部分だけを探してくれます。
とはいえ、上のHTMLから必要な箇所を探すのは、かなり一苦労……というか無理ゲーです。というわけで、一旦FIVBのサイトを確認してみましょう。
先ほど、Chromeで右クリック→「検証」でHTMLが見れるということをお伝えしましたが、実は他にもめちゃくちゃ優れた機能があります。サイトの任意の場所で右クリックすると、その部分のHTMLにピンポイントで飛んでくれるのです!この機能があるおかげで、あの長ったらしい情報を全部読まなくても済むんですね。
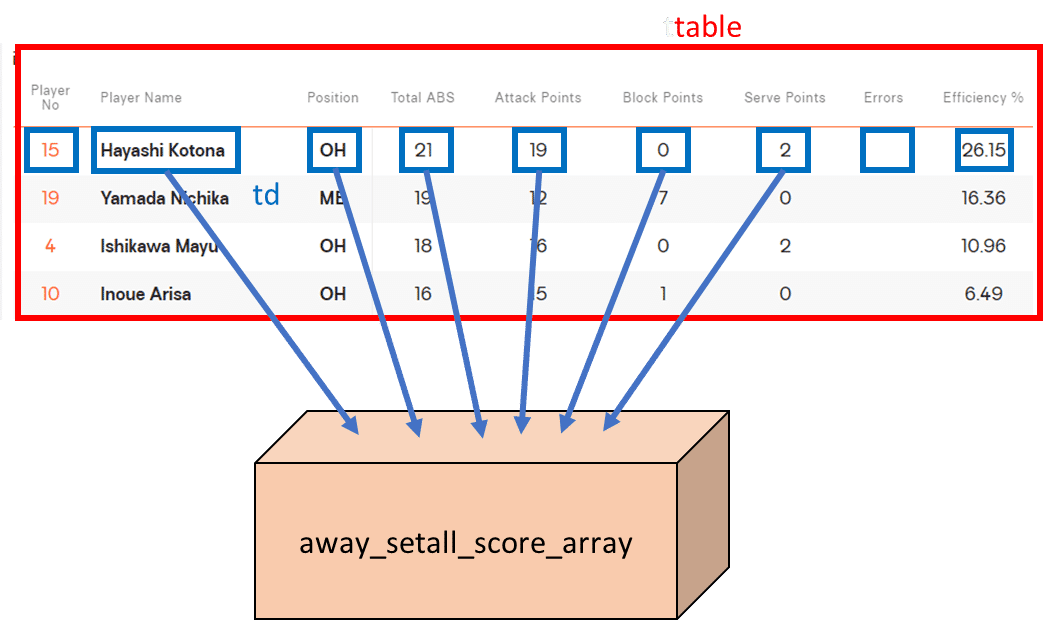
復習ですが、今回取得したいのは「Box Score」の表の部分です。というわけで、個人スタッツ表の上で右クリックすると……
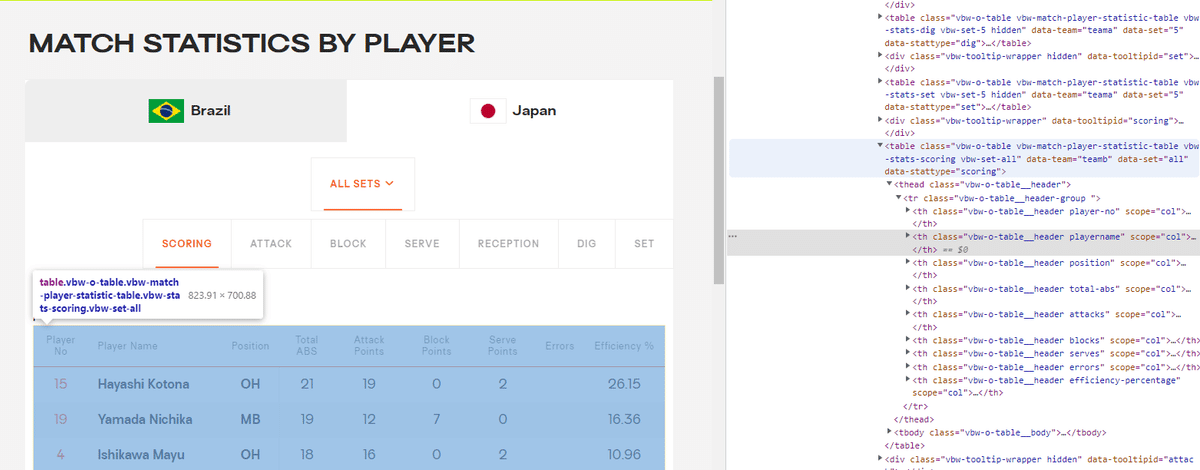
なんか吹き出しみたいなのが出てきてますね。中身を見るとtableと書いてあります。まさしくこれが表のことです。
だいぶ正解に近づいてきましたが、本当に欲しいのはこの表の中でも背番号、選手名、成績などの実際のデータです。なのでもう一度、同じようにHTMLを見てあげると……
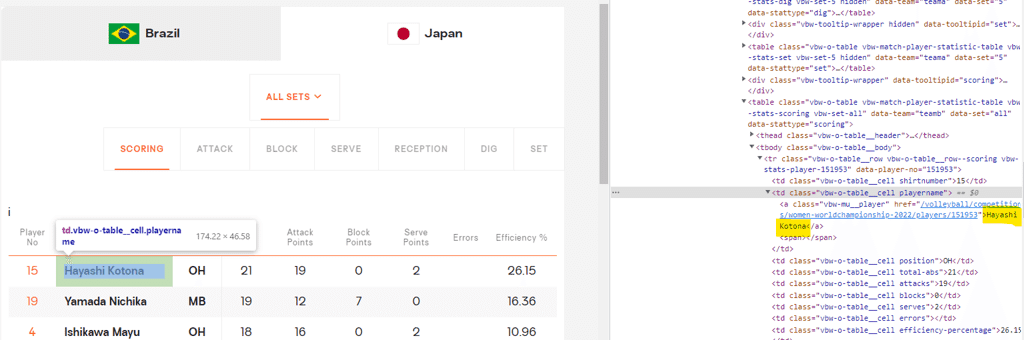
ついに選手名にたどり着きました!
また、このHTMLにはもう一つ重要な情報があります。ちょうど"Hayashi Kotona"の周りをよく見て欲しいのですが、
<td class="vbw-o-table__cell playername"><a class="vbw-mu__player" href="/volleyball/competitions/women-worldchampionship-2022/players/151953">Hayashi Kotona</a> <span></span></td>
<td class="vbw-o-table__cell position">OH</td>
<td class="vbw-o-table__cell total-abs">21</td>
<td class="vbw-o-table__cell attacks">19</td>
<td class="vbw-o-table__cell blocks">0</td>
<td class="vbw-o-table__cell serves">2</td>
<td class="vbw-o-table__cell errors"></td>
<td class="vbw-o-table__cell efficiency-percentage">26.15</td>とこのように、タグの先頭が全てtdで始まっているのがおわかりでしょうか。(たぶんtable dataのこと)
これはどういうことかというと、表全体のタグがtableで、その中身は全てtdという名前がついているということなんですね。
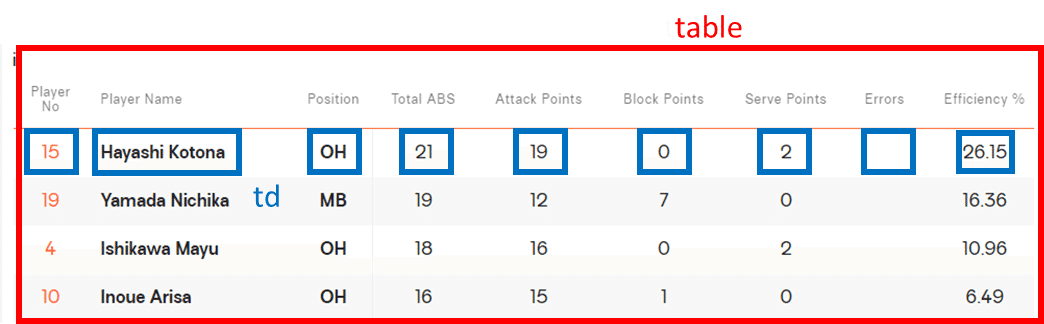
ここまでの調査の結果、取得するべき場所がだいぶ絞られてきたのではないでしょうか。
ホームページ全体のHTMLの中から個人スタッツ表を表すtableというタグを探して、その中でもデータを表すtdという要素を取得すれば、必要なデータが揃いそうです!
というわけで、ソースコードを見てみましょう。
#上の続き(getAllStatsメソッド+getScoreStatsメソッド)
soup=BeautifulSoup(text,'html.parser')
away_setall_score_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-scoring.vbw-set-all")[1]
away_setall_score_array=[]
for element in away_setall_score_soup.find_all('td'):
away_setall_score_array.append(element.text)まず1行目で、上で取得したサイト全体のHTMLをBeautiful Soupに渡してあげます。これはお作法みたいなもんです。
次の2行目が大事!ここでは、先ほど申し上げた通り個人スタッツの表(table)をHTMLの中から探してあげるわけですね。
さっきのHTMLをもう一度よく見てあげると、table.の続きに"match-player-statistic-table.vbw-stats-scoring.vbw-set-all"と書いてあるのがお分かりでしょうか。これが表の種類です。
"match-player-statistic"なので個人スタッツ、さらには"scoring.vbw-set-all"なので、この表が表すのは全セットの得点ということです。
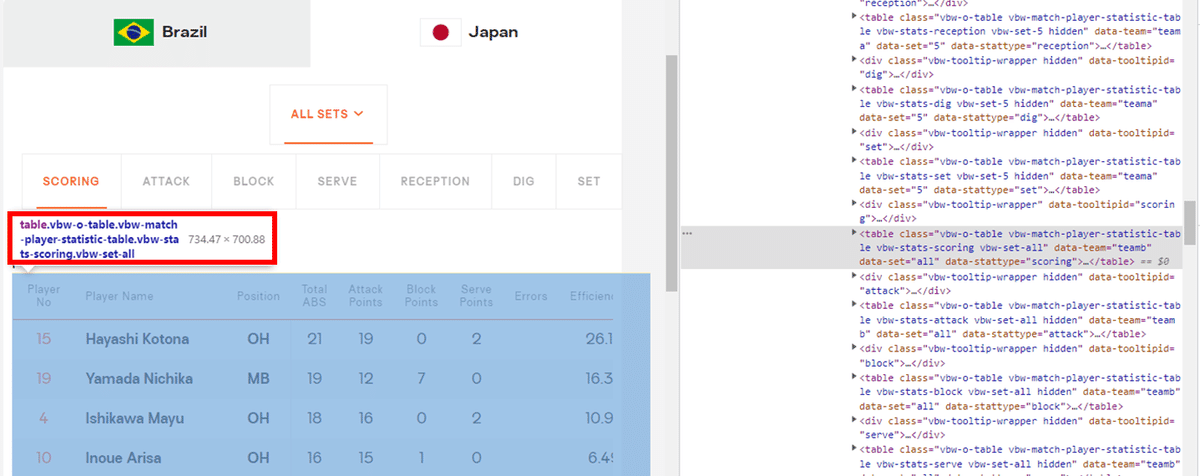
ここでもう一度2行目のコードを見ると、
soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-scoring.vbw-set-all")[1]となっています。()の中は先ほど言った表の種類、最後の[1]は同じ表が2チーム分あるので、後に出てくる方を取得するということです(カウントは基本0始まり)。お察しかもしれませんが、わざわざawayにしたのはこの試合で先に出てくるのがブラジルだからです……これでだいぶ範囲が絞れました。
ここまでで表だけに絞り込めたので、3~5行目でいよいよ表の中身のデータ(td)を取得します。
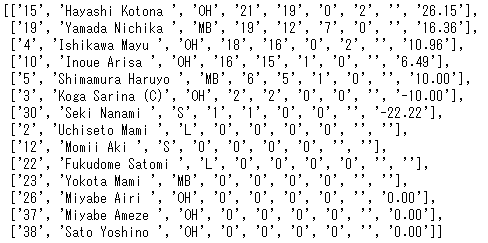
まず取得した結果を格納するための箱を作って(3行目)、4~5行目で表の中にあるtdを箱の中にひたすら放り込んでいくわけです。
こんな感じでひたすら表の中身を取得していくと……

最初が林選手の背番号"15"で始まり、最後が佐藤選手の効果率"0.00"で終わっています。これで表の中身の取得ができました!
非常に長くなりましたが、これで②必要な部分だけに絞り込む もできたので、スクレイピングは完了です!
ここで終わりでもいいのですが、今回は後の工程のことを考えて、取得した結果を少し編集します。
#getScoreStatsメソッドの続き
away_setall_score_array=[away_setall_score_array[i:i+9] for i in range(0,len(away_setall_score_array),9)]
for i in range(len(away_setall_score_array)):
away_setall_score_array[i][0:0]=[away,home]まず、先ほどお見せした箱(away_setall_score_array)は、表のデータ(td)を順番に並べただけなので、行の切れ目がどこかわかりにくいんですね。
なので、表でいう1行ごとに区切ってあげましょう。1行の要素数は9個なので、9個ずつ小分けにしていきます(1行目)。
あとは、これだけだとチーム名がわからないので、各行の先頭に自チームと対戦相手の名前を入れてあげます(2~3行目)。実は、ここに出てくるhomeとawayは、最初にホームページのURLと一緒に渡しているんですね。ここではhomeが"BRA"、awayが"JPN"です。
というわけで、チーム名を入れる処理を行うと……

こんな感じでチーム名も入りました!
無事に取得結果を見やすく整えることができたので、全体の手順①「FIVBのサイトからスタッツ取得」は終了です!続きは次回!
おまけ ソースコード
「とりあえずソースコード教えろ!」という方のために、貼っておきます。長いです。無駄が多いのはご愛敬。
このコードをこのまま実行しても動かないので注意。ところどころ設定が必要です。
#ライブラリのインストール
#python-pptx関係
!pip install python-pptx
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE # 図形の定義がされているクラス
from pptx.dml.color import RGBColor # 色を管理するクラス
from pptx.util import Cm,Pt
from pptx.enum.text import PP_ALIGN # テキストフレームの位置調整のためのクラス
from pptx.enum.shapes import MSO_CONNECTOR
#スクレイピング関係
!pip install selenium
!pip install webdriver_manager
!pip install chromedriver_binary
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import Select
from selenium.webdriver.chrome import service as fs
from telnetlib import EC
import chromedriver_binary
from selenium.webdriver.common.by import By
!pip install beautifulsoup4
from bs4 import BeautifulSoup
import time
#df関係
import pandas as pd
import numpy as np
#定数の定義
#python-pptx関係
TEMPLATE_FILE='Japan_Stats_Template.pptx' #PowerPointのファイル名
MAIN_TITLE='JAPAN STATS'
#パワポ内の長さ設定
ORIGIN_BEGIN_X=1.7
ORIGIN_BEGIN_Y=6.1
TABLE_WIDTH=Cm(8.44)
TABLE_HEIGHT=Cm(3.81)
TABLE_HEIGHT_4=Cm(4.23)
CELL_WIDTH=Cm(5.43)
CELL_HEIGHT=Cm(1.27)
CELL_HEIGHT_4=Cm(1.06)
MARGIN_WIDTH=0.86+10.17
MARGIN_HEIGHT=0.96+6.5
MARGIN_ADJUST_4=Cm(-0.21)
STYLE_ID= '{2D5ABB26-0587-4C30-8999-92F81FD0307C}' #書式なしスタイル
#スクレイピング関係
CHROMEDRIVER='PASS'#ChromeDriverのパス
#df関係
SCORE_COLUMNS=['Team','Opp.','No.','Player','Pos.','Total','Attack','Block','Serve','Errors','Eff']
ATTACK_COLUMNS=['Team','Opp.','No.','Player','Pos.','Point','Errors','Attempts','Total','Eff']
BLOCK_COLUMNS=['Team','Opp.','No.','Player','Pos.','Point','Errors','Touches','Total','Eff']
SERVE_COLUMNS=['Team','Opp.','No.','Player','Pos.','Point','Errors','Attempts','Total','Eff']
RECEPTION_COLUMNS=['Team','Opp.','No.','Player','Pos.','Success','Errors','Attempts','Total','Eff']
DIG_COLUMNS=['Team','Opp.','No.','Player','Pos.','Digs','Errors','Total','Eff']
#選手名の変換
JPN_PLAYERS={'Uchiseto Mami ':'Uchiseto','Koga Sarina (C)':'Koga','Ishikawa Mayu ':'Ishikawa',
'Shimamura Haruyo ':'Shimamura','Inoue Arisa ':'Inoue', 'Momii Aki ':'Momii',
'Hayashi Kotona ':'Hayashi', 'Yamada Nichika ':'Yamada', 'Fukudome Satomi ':'Fukudome',
'Yokota Mami ':'Yokota','Miyabe Airi ':'Airi', 'Seki Nanami ':'Seki',
'Miyabe Ameze' :'Ameze', 'Sato Yoshino ':'Sato'}
#スクレイピングのメソッド定義
def getAllStats(home,away,URL):
#Selniumを起動
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
driver = webdriver.Chrome(service=chrome_service)
driver.get(URL)
driver.implicitly_wait(10)
driver.find_element(By.CLASS_NAME,'tab-team-teamstats').click
text=driver.page_source
soup=BeautifulSoup(text,'html.parser')
#Score
scoreStats=getScoreStats(home,away,soup)
#Attack
attackStats=getAttackStats(home,away,soup)
#Block
blockStats=getBlockStats(home,away,soup)
#Serve
serveStats=getServeStats(home,away,soup)
#Reception
receptionStats=getReceptionStats(home,away,soup)
#Dig
digStats=getDigStats(home,away,soup)
return scoreStats,attackStats,blockStats,serveStats,receptionStats,digStats
def getScoreStats(home,away,soup):
#homeのsoupを取得
home_setall_score_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-scoring.vbw-set-all")[0]
home_setall_score_array=[]
for element in home_setall_score_soup.find_all('td'):
home_setall_score_array.append(element.text)
home_setall_score_array=[home_setall_score_array[i:i+9] for i in range(0,len(home_setall_score_array),9)]
for i in range(len(home_setall_score_array)):
home_setall_score_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_score_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-scoring.vbw-set-all")[1]
away_setall_score_array=[]
for element in away_setall_score_soup.find_all('td'):
away_setall_score_array.append(element.text)
away_setall_score_array=[away_setall_score_array[i:i+9] for i in range(0,len(away_setall_score_array),9)]
for i in range(len(away_setall_score_array)):
away_setall_score_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_score_array.extend(away_setall_score_array)
return home_setall_score_array
def getAttackStats(home,away,soup):
#homeのsoupを取得
home_setall_attack_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-attack.vbw-set-all")[0]
home_setall_attack_array=[]
for element in home_setall_attack_soup.find_all('td'):
home_setall_attack_array.append(element.text)
home_setall_attack_array=[home_setall_attack_array[i:i+8] for i in range(0,len(home_setall_attack_array),8)]
for i in range(len(home_setall_attack_array)):
home_setall_attack_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_attack_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-attack.vbw-set-all")[1]
away_setall_attack_array=[]
for element in away_setall_attack_soup.find_all('td'):
away_setall_attack_array.append(element.text)
away_setall_attack_array=[away_setall_attack_array[i:i+8] for i in range(0,len(away_setall_attack_array),8)]
for i in range(len(away_setall_attack_array)):
away_setall_attack_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_attack_array.extend(away_setall_attack_array)
return home_setall_attack_array
def getBlockStats(home,away,soup):
#homeのsoupを取得
home_setall_block_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-block.vbw-set-all")[0]
home_setall_block_array=[]
for element in home_setall_block_soup.find_all('td'):
home_setall_block_array.append(element.text)
home_setall_block_array=[home_setall_block_array[i:i+8] for i in range(0,len(home_setall_block_array),8)]
for i in range(len(home_setall_block_array)):
home_setall_block_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_block_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-block.vbw-set-all")[1]
away_setall_block_array=[]
for element in away_setall_block_soup.find_all('td'):
away_setall_block_array.append(element.text)
away_setall_block_array=[away_setall_block_array[i:i+8] for i in range(0,len(away_setall_block_array),8)]
for i in range(len(away_setall_block_array)):
away_setall_block_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_block_array.extend(away_setall_block_array)
return home_setall_block_array
def getServeStats(home,away,soup):
#homeのsoupを取得
home_setall_serve_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-serve.vbw-set-all")[0]
home_setall_serve_array=[]
for element in home_setall_serve_soup.find_all('td'):
home_setall_serve_array.append(element.text)
home_setall_serve_array=[home_setall_serve_array[i:i+8] for i in range(0,len(home_setall_serve_array),8)]
for i in range(len(home_setall_serve_array)):
home_setall_serve_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_serve_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-serve.vbw-set-all")[1]
away_setall_serve_array=[]
for element in away_setall_serve_soup.find_all('td'):
away_setall_serve_array.append(element.text)
away_setall_serve_array=[away_setall_serve_array[i:i+8] for i in range(0,len(away_setall_serve_array),8)]
for i in range(len(away_setall_serve_array)):
away_setall_serve_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_serve_array.extend(away_setall_serve_array)
return home_setall_serve_array
def getReceptionStats(home,away,soup):
#homeのsoupを取得
home_setall_reception_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-reception.vbw-set-all")[0]
home_setall_reception_array=[]
for element in home_setall_reception_soup.find_all('td'):
home_setall_reception_array.append(element.text)
home_setall_reception_array=[home_setall_reception_array[i:i+8] for i in range(0,len(home_setall_reception_array),8)]
for i in range(len(home_setall_reception_array)):
home_setall_reception_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_reception_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-reception.vbw-set-all")[1]
away_setall_reception_array=[]
for element in away_setall_reception_soup.find_all('td'):
away_setall_reception_array.append(element.text)
away_setall_reception_array=[away_setall_reception_array[i:i+8] for i in range(0,len(away_setall_reception_array),8)]
for i in range(len(away_setall_reception_array)):
away_setall_reception_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_reception_array.extend(away_setall_reception_array)
return home_setall_reception_array
def getDigStats(home,away,soup):
#homeのsoupを取得
home_setall_dig_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-dig.vbw-set-all")[0]
home_setall_dig_array=[]
for element in home_setall_dig_soup.find_all('td'):
home_setall_dig_array.append(element.text)
home_setall_dig_array=[home_setall_dig_array[i:i+7] for i in range(0,len(home_setall_dig_array),7)]
for i in range(len(home_setall_dig_array)):
home_setall_dig_array[i][0:0]=[home,away]
#awayのsoupを取得
away_setall_dig_soup=soup.select(".vbw-o-table.vbw-match-player-statistic-table.vbw-stats-dig.vbw-set-all")[1]
away_setall_dig_array=[]
for element in away_setall_dig_soup.find_all('td'):
away_setall_dig_array.append(element.text)
away_setall_dig_array=[away_setall_dig_array[i:i+7] for i in range(0,len(away_setall_dig_array),7)]
for i in range(len(away_setall_dig_array)):
away_setall_dig_array[i][0:0]=[away,home]
#両チームのsoupを結合
home_setall_dig_array.extend(away_setall_dig_array)
return home_setall_dig_array
#取得したスタッツの整形用メソッド(不要項目の削除等)
def getScoreDf(scoreArray):
#df化
scoreDf=pd.DataFrame(scoreArray,columns=SCORE_COLUMNS)
#日本の成績だけ抽出
scoreDf=scoreDf[scoreDf['Team']=='JPN']
#ランク付け
scoreDf['Total'] =scoreDf['Total'].astype(int)
ranking=scoreDf['Total'].rank(method='min',ascending=False)
scoreDf['rank'] = ranking
#並び替え
scoreDf=scoreDf.sort_values(by=['rank','Attack'], ascending=[True,False]).reset_index(drop=True)
#カラム落とす
scoreDf=scoreDf[['Player','Total','rank']]
#文字列に変換
scoreDf['Total'] =scoreDf['Total'].astype(str)
return scoreDf
def getAttackDf(attackArray):
#df化
attackDf=pd.DataFrame(attackArray,columns=ATTACK_COLUMNS)
#日本の成績だけ抽出
attackDf=attackDf[attackDf['Team']=='JPN']
#ランク付け
attackDf['Point'] =attackDf['Point'].astype(int)
ranking=attackDf['Point'].rank(method='min',ascending=False)
attackDf['rank'] = ranking
#並び替え
attackDf=attackDf.sort_values(by=['rank','Eff'], ascending=[True,False]).reset_index(drop=True)
#カラム落とす
attackDf=attackDf[['Player','Point','rank']]
#文字列に変換
attackDf['Point'] =attackDf['Point'].astype(str)
return attackDf
def getBlockDf(blockArray):
#df化
blockDf=pd.DataFrame(blockArray,columns=BLOCK_COLUMNS)
#日本の成績だけ抽出
blockDf=blockDf[blockDf['Team']=='JPN']
#ランク付け
blockDf['Point'] =blockDf['Point'].astype(int)
ranking=blockDf['Point'].rank(method='min',ascending=False)
blockDf['rank'] = ranking
#並び替え
blockDf=blockDf.sort_values(by=['rank','Eff'], ascending=[True,False]).reset_index(drop=True)
#カラム落とす
blockDf=blockDf[['Player','Point','rank']]
#文字列に変換
blockDf['Point'] =blockDf['Point'].astype(str)
return blockDf
def getServeDf(serveArray):
#df化
serveDf=pd.DataFrame(serveArray,columns=SERVE_COLUMNS)
#日本の成績だけ抽出
serveDf=serveDf[serveDf['Team']=='JPN']
#ランク付け
serveDf['Point'] =serveDf['Point'].astype(int)
ranking=serveDf['Point'].rank(method='min',ascending=False)
serveDf['rank'] = ranking
#並び替え
serveDf=serveDf.sort_values(by=['rank','Total'], ascending=True).reset_index(drop=True)
#カラム落とす
serveDf=serveDf[['Player','Point','rank']]
#文字列に変換
serveDf['Point'] =serveDf['Point'].astype(str)
return serveDf
def getReceptionDf(receptionArray):
#df化
receptionDf=pd.DataFrame(receptionArray,columns=RECEPTION_COLUMNS)
#日本の成績だけ抽出
receptionDf=receptionDf[receptionDf['Team']=='JPN']
#ランク付け
receptionDf['Total'] =receptionDf['Total'].astype(int)
ranking=receptionDf['Total'].rank(method='min',ascending=False)
receptionDf['rank'] = ranking
#効果率の処理
receptionDf.replace('',0,inplace=True)
receptionDf['Eff'] =receptionDf['Eff'].astype(float)
#並び替え
receptionDf=receptionDf.sort_values(by=['rank','Eff'], ascending=[True,False]).reset_index(drop=True)
#カラム落とす
receptionDf=receptionDf[['Player','Eff','rank']]
#効果率四捨五入
receptionDf=receptionDf.round({'Eff': 1})
#文字列に変換
receptionDf['Eff'] =receptionDf['Eff'].astype(str)
return receptionDf
def getDigDf(digArray):
#df化
digDf=pd.DataFrame(digArray,columns=DIG_COLUMNS)
#日本の成績だけ抽出
digDf=digDf[digDf['Team']=='JPN']
#ランク付け
digDf['Digs'] =digDf['Digs'].astype(int)
ranking=digDf['Digs'].rank(method='min',ascending=False)
digDf['rank'] = ranking
#並び替え
digDf=digDf.sort_values(by=['rank','Total'], ascending=True).reset_index(drop=True)
#カラム落とす
digDf=digDf[['Player','Digs','rank']]
#文字列に変換
digDf['Digs'] =digDf['Digs'].astype(str)
return digDf
def getTableArray(df):
#3位以上が4人以上いるか確認
if len(df[df['rank']<=3])<=4:
#rankを削除
tableDf=df[df['rank']<=3].drop('rank',axis=1)
tableDf.replace(JPN_PLAYERS,inplace=True)
#リスト化
tableArray=tableDf.values.tolist()
else:
tableDf=df.head(4).drop('rank',axis=1)
tableDf.replace(JPN_PLAYERS,inplace=True)
tableArray=tableDf.values.tolist()
return tableArray
def addPt(array):
for i in range(len(array)):
array[i][1]+='pt'
return array
def addPercent(array):
for i in range(len(array)):
array[i][1]+='%'
return array
#Python-pptxの操作用メソッド
def addSlide(prs):
slide_layout=prs.slide_layouts[11]
slide=prs.slides.add_slide(slide_layout)
return slide
def setTitles(slide, subTitle):
#PlaceHolderのインデックス取得
indexList=[p.placeholder_format.idx for p in slide.placeholders]
#メインタイトル設定
mainTitleBox=slide.placeholders[indexList[0]]
mainTitleBox.text=MAIN_TITLE
#サブタイトル設定
subTitleBox=slide.placeholders[indexList[1]]
subTitleBox.text=subTitle
def addTable(slide, tableArray, left, top):
#変数処理
tableData = np.array(tableArray)
width = TABLE_WIDTH
shapes = slide.shapes
#3行のとき
if len(tableArray)==3:
height=TABLE_HEIGHT
table = shapes.add_table(3, 2, left, top, width, height).table
#列の幅設定
table.columns[0].width = CELL_WIDTH
table.columns[1].width = width-CELL_WIDTH
#値の設定
for row in range(3):
for column in range(2):
cell = table.cell(row,column)
cell.text =str(tableData[row][column])
#線の追加
for i in range(3):
#線引き終わるごとにスタート地点移動
lineTop=top+(CELL_HEIGHT*(i+1))
#線の追加
line0=slide.shapes.add_connector(MSO_CONNECTOR.STRAIGHT, left, lineTop, left+width, lineTop)
#線の書式設定
#線の色
line0.line.color.rgb=RGBColor(226,0,0)
#線の太さ
line0.line.width=Pt(1.4)
#セル内の書式設定
for row in range(3):# テーブルの行数の取得
for column in range(2):
cell = table.cell(row, column)
pg = cell.text_frame.paragraphs[0] # paragraph(段落)オブジェクトの取得
pg.font.size = Pt(24) # 段落のフォントの大きさの設定
pg.font.color.rgb = RGBColor(226, 0, 0) # 段落のフォントの色の設定
pg.font.bold = True #太字
pg.alignment = PP_ALIGN.CENTER #中央揃え
#4行のとき
if len(tableArray)==4:
height=TABLE_HEIGHT_4
newTop=top+MARGIN_ADJUST_4
table = shapes.add_table(4, 2, left, newTop, width, height).table
#列の幅設定
table.columns[0].width = CELL_WIDTH
table.columns[1].width = width-CELL_WIDTH
#値の設定
for row in range(4):
for column in range(2):
cell = table.cell(row,column)
cell.text =str(tableData[row][column])
#線の追加
for i in range(4):
#線引き終わるごとにスタート地点移動
lineTop=newTop+(CELL_HEIGHT_4*(i+1))
#線の追加
line0=slide.shapes.add_connector(MSO_CONNECTOR.STRAIGHT, left, lineTop, left+width, lineTop)
#線の書式設定
#線の色
line0.line.color.rgb=RGBColor(226,0,0)
#線の太さ
line0.line.width=Pt(1.4)
#セル内の書式設定
for row in range(4):# テーブルの行数の取得
for column in range(2):
cell = table.cell(row, column)
pg = cell.text_frame.paragraphs[0] # paragraph(段落)オブジェクトの取得
pg.font.size = Pt(19) # 段落のフォントの大きさの設定
pg.font.color.rgb = RGBColor(226, 0, 0) # 段落のフォントの色の設定
pg.font.bold = True #太字
pg.alignment = PP_ALIGN.CENTER #中央揃え
#テーブルスタイルの設定
tbl = table._graphic_frame.element.graphic.graphicData.tbl
style_id = '{2D5ABB26-0587-4C30-8999-92F81FD0307C}' #書式なしスタイル
tbl[0][-1].text = style_id
def setTable(slide,array1,array2,array3,array4,array5,array6):
#アタック
left1=Cm(ORIGIN_BEGIN_X)
top1= Cm(ORIGIN_BEGIN_Y)
addTable(slide, array1, left1, top1)
#ブロック
left2=Cm(ORIGIN_BEGIN_X+MARGIN_WIDTH)
addTable(slide, array2, left2, top1)
#サーブ
left3=Cm(ORIGIN_BEGIN_X+MARGIN_WIDTH*2)
addTable(slide, array3, left3, top1)
#サーブレシーブ
top2=Cm(ORIGIN_BEGIN_Y+MARGIN_HEIGHT)
addTable(slide, array4, left1, top2)
#ディグ
addTable(slide, array5, left2, top2)
#スコア
addTable(slide, array6, left3, top2)
#ここから実行!!
#スクレイピング
home='home'#ホームチームの名前
away='away'#アウェイチームの名前
URL='URL'#試合のURL
scoreArray,attackArray,blockArray,serveArray,receptionArray,digArray=getAllStats(home,away,URL)
scoreDf=getScoreDf(scoreArray)
scoreTableArray=getTableArray(scoreDf)
scoreTableArray=addPt(scoreTableArray)
attackDf=getAttackDf(attackArray)
attackTableArray=getTableArray(attackDf)
attackTableArray=addPt(attackTableArray)
blockDf=getBlockDf(blockArray)
blockTableArray=getTableArray(blockDf)
blockTableArray=addPt(blockTableArray)
serveDf=getServeDf(serveArray)
serveTableArray=getTableArray(serveDf)
serveTableArray=addPt(serveTableArray)
receptionDf=getReceptionDf(receptionArray)
receptionTableArray=getTableArray(receptionDf)
receptionTableArray=addPercent(receptionTableArray)
digDf=getDigDf(digArray)
digTableArray=getTableArray(digDf)
#python-pptx
prs=Presentation('Japan_Stats_Template.pptx')
slide=addSlide(prs)
setTitles(slide,'スライドのsubtitle')
setTable(slide,attackTableArray,blockTableArray,serveTableArray,receptionTableArray,digTableArray,scoreTableArray)
prs.save('Japan_Stats_Template.pptx')