
MJ+漢字どないな

MJ+という文字集合が、デジタル庁より作成、公表される予定です。
地方公共団体の基幹業務システムの統一・標準化に関する共通機能等技術要件検討会(第2回)|デジタル庁 (digital.go.jp)
現在どんな日本語コンピュータ環境でも全く同じように文字を扱える訳ではないので、画面に表示された文字の形を構成する部品、部首を見たら、学校で習った形、住民票や戸籍の記載とも形が違う、意図通り表示されず文書の内容を再現できない、といったことが起こります。それらを回避/解決し、情報交換を容易に行えるようにすることがMJ+の主な目的です。
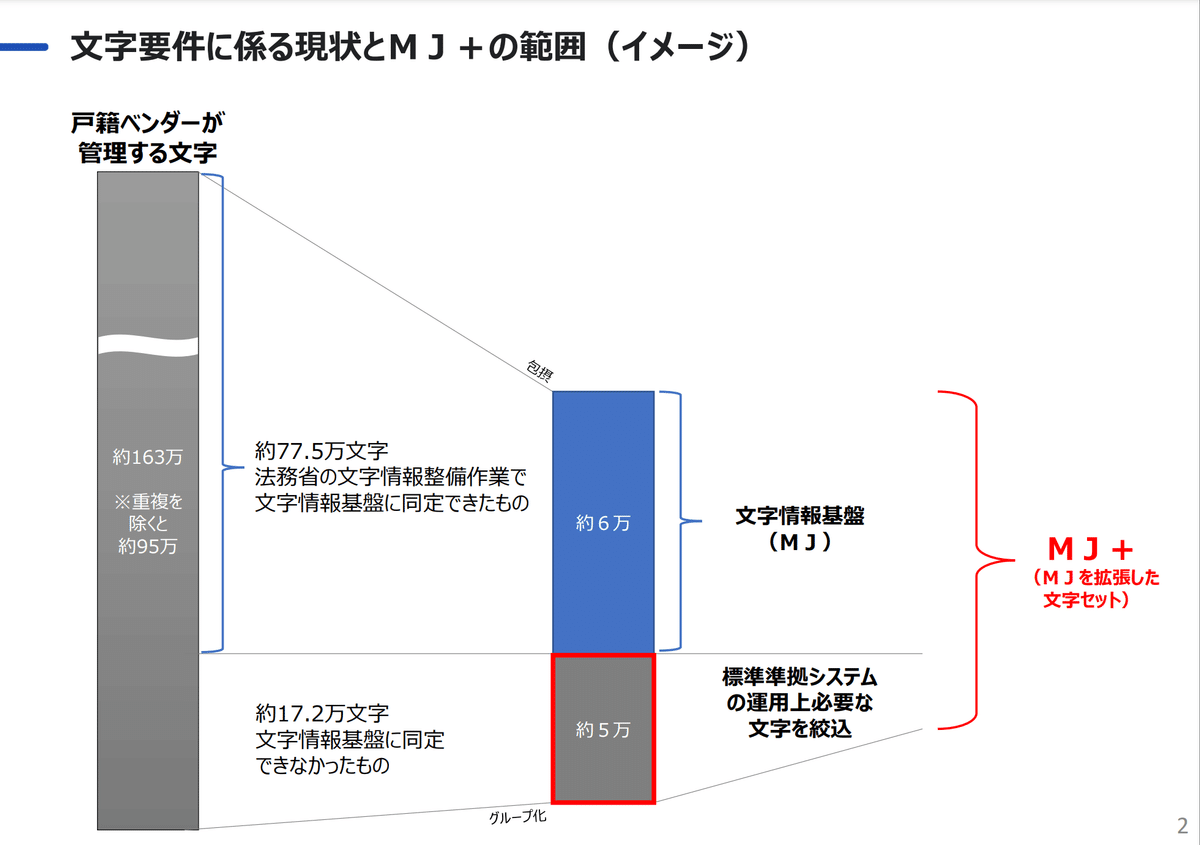
163万字というのは戸籍ベンダーが管理する文字の和集合らしいのですが、
同じ文字を纏めても(同定しても)、多くの文字があります。
日本の行政では、これら多くの文字の形を扱っているものの、各省庁や自治体のシステムで共通して使える文字の標準は、明確に定められていないのが現状です。
字形の識別
東京都葛飾区と奈良県葛城市、各行政ホームページで「葛」という文字の形を見比べると違いがあります。
これらは共に同一の意味を持つ正式な文字の形で、異体字と呼ばれます。
多くのアプリ環境では「くず」と入力して変換キーを押しても葛飾区で使われる字形(「人」の形)だけ候補に出てくると思います。(JIS改定で1983-2004年の間は葛城市で使われる字形(「ヒ」の形))
類似形でも同意味で通じるなら差し支え無いこともありますが、正確な形を識別し使い分けすることが求められることもあります。
アイデンティティ
特に、氏名や住所(地名)表記、固有名詞に含まれる文字はアイデンティティへ直結したり、字の上手/下手やデザイン的な形状を超えた抽象的、記号的な形に対しての思い入れもあるのではないでしょうか。象形文字で高度な表意文字でもある漢字は、尚更かもしれません。
自分が何者かを証明する公的文書では、正確な(少なくとも自身ではそう思っている)表記であってほしいとの要望があり、都度文字の追加が行われていたことは、なんとなく頷けます。
仮に、ずっと名前表記に使っていた字形のルーツが、うっかり者のご祖先様が点を一つ多く付けていたり、2つ並んだ字が重なり1文字とされた可能性があっても、それに文字としての意味は求めず自分を表すマークとして使い続けたいという方はいるかもしれません。
コンピュータと漢字の問題
日本語の表記にも用いられる漢字は、その総数を精査し切れない、人類史上最も数が多いと言われる文字体系です。
コンピュータで文字を扱うには、総数すらわからない全ての漢字を、異なる環境間で同じように表示し情報交換することは無理があるため、何らかの集合規則が設けられます。それら文字集合(と符号化方式)は幾つか混在しており、総数不明の漢字はどの形を同じと見做し何が正しいか判断が困難なことから任意字形を外字として追加登録し、ローカルで表示できるよう許容され続けたことが、コンピュータの文字問題の原因ともなっています。
コンピュータ以前の活版印刷でも字形の標本はありますが、そこに存在しない形を厳密に表現したい場合は活字を追加したり、手書で文字を追加することで局所的に解決され、文字情報が広範囲でやりとりされることもなかったことから、多くの人を巻き込むような問題はさほど起こらなかったと思います。
日本語文字集合の漢字数
幾つかの日本語の文字集合を、扱えるおよその漢字の数から並べてみると、
~約6,000字
JIS第2水準漢字まで(JIS X 0208)。小学校で1,026字、中学校で1,006字習う日本語の常用漢字を全て含み、殆どの日本語対応アプリで問題無く扱える範囲と思います。
~約11,000字
JIS第4水準まで(JIS X 0213:2004)。WindowsOSでは、Vista(NT6) 以降で標準サポートされています。
Unicodeでは、UTF-16で符号化する場合、全ての文字を扱うためにはサロゲートペアを用いる必要があります。
Shift_JISの上位互換としてShift_JIS-2004という符号化方式が用意されています。このあたりでShift_JIS符号化方式の2byteコードで符号化できる数(0x8080シフト、((47 + 13)×188)に達してしまいます。
~約15,000字
アドビ社が日本語DTP用に開発した文字集合規格である、Adobe-Japan1-6には、23,058字形の中に、漢字が14,663字あります。(葛城市の字形も識別できます。)
~約2万字
総務省の住基ネット(住民基本台帳ネットワークシステム)で使われる文字集合。住基統一文字。
~約5万字
法務省の戸籍システムで使われる文字集合。戸籍統一文字。
住基や戸籍では、名前や住所の表記のためJIS第4水準までに含まれない漢字も多く集められています。それら全ての文字形は、普段使うフォントでは表現できないと思います。
~約6万字
MJ文字集合。住基統一文字と戸籍統一文字を対象に整備。
これを拡張して、MJ+が作成されることになっています。

異体字の識別
UnicodeではIVD(Ideographic Variation Database)で定められた、ある文字重合の異体字を、文字列シーケンス上でIVS(Ideographic Variation Selector)というコードにより選択することができ、それに対応したフォントを使えば表示字形を切り替えることができます。異体字でも「高」に対する「髙」(はしご高)は、Windows31JやUnicodeで別々のコードへ符号化されているため、IVSは使わずに比較的古いPCでも別々の文字として識別できます。
フォントの字形数
現在広く利用されているフォントフォーマットのPostScript系(Type1やCID、CFF)とTrueType系(及びそれら字形データ形式をcff or glyf/locaテーブルとして引き継ぎ統合したOpenType)では、フォント内の字形(と合字字形構成パーツ)の2D情報を符号無16bit値"グリフID"で識別するため、1フォントで扱える字形数には約6.5万という上限があります。
もし16bit制限のない独自フォーマットのフォントを作っても、それが広まらないと限られた所で使えるだけで突然使えなくなる恐れもあります。漢字を用いない言語の字形識別は16bitもあれば十分なので、フォントの基本容量が増えたり仕様が煩雑になるデメリットを鑑みると、世界規模で広がることはあまり期待できそうにありません。
ある文字集合が1フォント内で完結していると、その文字集合を様々な環境で共通して扱うのもフォントファイルのコピーで済むので、広く利用されるフォントフォーマットに対応した既存システムでの導入も容易になります。漢字と非漢字を合わせて6万字をゆうに超える文字集合を扱うには、システムで複数のフォントを組み合わせたり、何かしらの文字集合に外字を併用することになると思います。
でどうなるのか
MJ+は、MJの拡張とされていますが、未だ、収録文字の確定はしていません。MJ+準拠システム導入前に地方自治体が独自に作成した外字はMJ+と同定した文字を利用することで、外字は利用しない方向のようです。
もし行政窓口で未知の字形に遭遇した場合、誰でもMJ+文字集合から字形を探し同定を行うことが可能な状態を実現できれば、扱うべき文字の増加は食い止められそうな気もします。
多くの漢字表記を用いる日本語は、厳格な文字集合が定まらない先進国唯一(最後の)言語とも言われます。一方、漢字発祥の地でもある中国では、GB 18030という国家標準の文字集合が定められ、その規格対応フォントの利用まで義務付けられています。強制の賛否はさておき、日本国内で扱われるべき明確な文字集合が存在することでコンピュータで文字を扱う際の悩みは少なくなるのでは、と思うこともあります。
漢字かどうかに関わらず、現在使われることが殆ど無くなった消滅の危機にある文字の形も文化として残ってほしいと思います。
ただ歴史や文字の研究以外では、数十年に一度だけ扱われる様な文字への考慮や管理が、行政の運用負荷になり続けるのはどうかとも思います。税金へ跳ね返ってくるのも困りますし。
MJ+の文字は増えるべき? 増やしたらダメ?減らすべき?誤字は正す?コストや多数のメリットvs.少数の個や文化…何を重視し基準を決めていくのか? 大ナタを振るわないと、なかなか決まらないことなのかもしれません。