
Dify v0.8.3 とQwen2.5 on Ollama

はじめに
Difyが、先週の日本時間で9月20日に、v0.8.3をリリースしています。v0.8.2のアナウンスが9月13日でしたから、その1週間後ということになります。最近、一層リリースのピッチが上がっています。
Githubのv0.8.3のリリースには次のように記載されています。
" このリリースのハイライトは、Aliyun Bailianとシームレスに同期されたQwen 2.5シリーズモデルの統合です。"
なお、 " Aliyun Bailian (阿里云百炼)とは、阿里雲(Alibaba Cloud)が提供する企業向け大規模モデル開発プラットフォーム" のことです。
今回は、このリリースのおさらい(既に約1週間経過ですので、、)とQwen2.5をDifyで使えるようにする方法などについてのメモなどとなります。
Dify v0.8.3について
今回も、Githubからの引用です。
以下は、上記の内容のコピペ編集となります。
🚀 主な機能のハイライト
Qwen 2.5シリーズモデル:このリリースのハイライトは、Aliyun Bailianとシームレスに同期されたQwen 2.5シリーズモデルの統合です。このメジャー アップデートにより、モデルの提供が大幅に拡張され、プロジェクトの機能が強化され、柔軟性が向上します。AI 駆動型ワークフローで作業する場合でも、モデル集約型タスクで作業する場合でも、Qwen 2.5 シリーズは比類のないパフォーマンスと汎用性を提供します。
🛠️ 追加機能と改善点
強力な Qwen モデルに加えて、ユーザーエクスペリエンスを最適化するために、いくつかの改善と修正も行いました。
新しいツール:
安定した拡散のためのComfyUI:ComfyUIの統合により画像生成機能が強化されました。
Siliconflow Image-Genツール:flux開発スイートの一部であるこのツールは、クリエイティブ ツールキットがさらに拡張されます。
タイムアウト設定: 環境変数を介してテキスト生成とワークフローのタイムアウトを完全に制御できるようになり、プロセス実行時間をより柔軟に管理できるようになりました。
⚙️ 機能強化と修正
全体的な安定性を向上させるために、さまざまな最適化とバグ修正にも取り組みました。
画像プレビューの最適化: SVGレンダリングと画像プレビューが強化され、よりスムーズなユーザーエクスペリエンスが実現しました。
ワークフローの改善: 結果処理の改善とデータセットのマルチ取得の改善が含まれます。
バグ修正: 認証、トークンの使用、ベクトル検索方法にわたる多数の修正により、よりスムーズな操作が実現します。
このリリースは、Qwen 2.5 シリーズ モデルで最先端の機能を提供し、追加のツールと修正でプラットフォームを改良することを目的としています。このバージョンを実現してくれた素晴らしい貢献者に心から感謝します! 🚀
補記
上記関連でいくつか補填します。
・Qwen2.5
Qwen2.5はアリババクラウドが提供する新しいLLMです。前のモデルは、Qwen2です。アリババクラウドには、次のような記載があります。
ここで、Tongyiというのがキーワードです。Difyのモデルプロバイダーの中にそれがあります。下記の赤枠の部分です。

・ComfyUI
Stable Diffusion用のUIとして有名なComfyUIですが、最近はFlux用としても散見されます。Dify上では、ツールとして提供されています。ただし、現時点では、認証方法のリンク先が設定されておらず、Difyでは調査できません。別途調べる必要がありそうです。
Siliconflow Image-Genツール
前回ご紹介したSilicon Flowの画像生成ツールで、Flux用ツールのモデルが2つから選択できるようになりました。
Flux.1-schnel, Flux.1-devの2つです。
Silicon Flowの画像生成ツールについては、前回、他と比較しましたが、SD3などの使いこなしは、今ひとつという印象でした。
ただ、実質的にDifyで使えるFluxのツールとしては、現時点では、同社のツールにほぼ絞られます。
このように、新たなモデルをすぐにリリースしてきたのは、やる気も感じます。SD3も含め、別途検討したいと思います。

DifyとQwen2.5
このように、Difyで使用可能となったらしいアリババの最新LLMのQwen2.5ですが、どのようにすれば、Dify で使えるようになるのか、説明がありません。ツールとかではなさそうですし、ちょっと困惑していました。
ちなみに、上記のTongyiに気付かされたのは、下記の情報によるものです。
Qwen2.5をDifyで使うための設定
この使い方については、経知 神草さんによる次のUdemy講座で説明がありました。
同講座は、オリジナルの講座内容に加え、Dify の新しい機能が追加されると、サービスレクチャーといいますか、レクチャーが次々と追加されています。
v0.8.3については、なんと、公開された9月20日にその説明が追記されていました。フォローが素晴らしいと思います。
Qwen2.5を使えるようにする方法は、少なくも2つあるようです。
1.Difyのモデルプロバイダーの、Tongyiを使う
2.同じくモデルプロバイダーの、Ollamaを使う
1の方法は、アリババですので、本流に思われます。ただ、経知さんも述べられていますが、無料の設定で、APIの入手まではなんとかできるのですが、使おうとするとエラーが出ます。入金、もしくは、少なくも入金方法のエントリーが必須なようです。
一方、Ollamaについては、これまで全く使ったことがなかったのですが、どうやら、LLMを無償でダウンロードして、on PCでLLMを動かす、という方法を提供しているようです。Macでも設定ができます。
docker上でon PCで動かしているDifyと同じということです。
つまり、ネット接続なしでも、自分のPC上でLLMとDifyが使える環境を設定できる、ということです。
内部メモリーが24GBで、内蔵SSDが1TBのM2 MacBookAirにはちょっと酷かもしれませんが、一度試してみたいようにも思います。
ということで、2の方式でトライしてみました。
Qwen2.5 on Ollama v0.3.2
Ollamaの最新は、v0.3.2です。
Qwen2.5は、v0.3.1から使えるようになりました。
また、v0.3.2では、llama3.2やQwen2.5-coderなどが追加されています。
Ollamaのインストール方法
OllamaのMacへのインストール方法の記事は、たくさんありますので、そちらをご覧いただく方が早いかと思います。
例えば、このような記事などがあります。
要は、Ollamaのサイトに行って、Mac用のアプリをダウンロードしてクリックすると、アプリフォルダーへの移動しますかと聞かれます。OKして、移動後Runさせると、、、一見、何もおこりません、、。
どうやらこのアプリは、ターミナル環境でのOllama用のコマンドラインをインストールするのが目的のようです。
Ollamaは基本、ターミナルでアクセスします。
各LLM等のインストール方法
LLM等をインストールするには、ターミナルに行き、次のコマンドをrunさせます。
例えば、llarma3.2の場合はこのように入力します。
ollama run llama3.2
今回の目的のQwen2.5の場合は、こうです。
ollama run qwen2.5
このコマンド " ollama run xxxx " は、初めての場合は、インストールが自動的に始まります。また、既にインストールされている場合は、runします。
qwen2.5-coderの場合とllama3.2の場合の例を示します。

この2つの例のそれぞれの最後の行にあるように、
>>> と示された状態になります。
この状態で、LLMに訪ねたいことを直接入力すると、応えてくれます。
/? と入力すると、コマンドのリストが出ます。
/bye と入力すると、runが終了します。
上記では、それぞれ、約4.7GBと2GB程度の量となっています。on PCですので、あまり大きな容量のモデルは提供していないようです。
Difyの設定
先ほどまでの設定で、Mac上に、ターミナル用のOllamaのコマンドがインストールされ、また、使いたいLLM等が、既にMacにインストール済となりました。
この状態で、Ollamaを、Difyのモデルプロバイダーとして設定することで、各モデルがLLMノードで選択できるようになります。次の手順です。
Difyの基本画面の右上にあるユーザー名をクリックしメニューをプルダウンします。
表示されたメニューの、設定をクリックします。
新たに表示された画面の右側にある " モデルプロバイダー " をクリックします。
Ollamaにカーソルを持っていき、+モデルを追加、をクリックします。
次に設定画面が表示されます
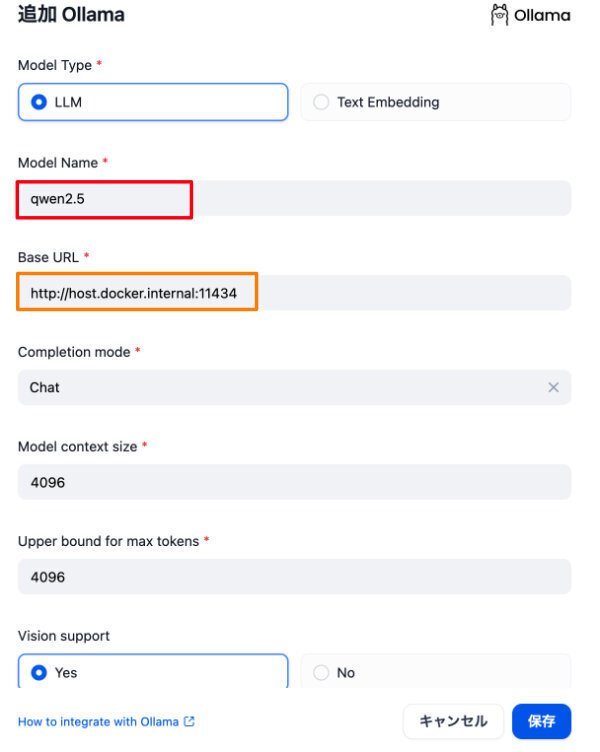
実はこの画面は、モデルの追加用ですが、初期設定も同様です。
この設定の詳細については、下記をご覧ください。
ポイントは、赤枠で囲んだモデル名と、オレンジ枠で囲んだBaseURLです。
後者は、http://host.docker.internal:11434 となります。
ちなみに、複数モデルを追加した場合、例えば次のような表記になります。
上記のモデル名は、下図の記載などを参照ください。
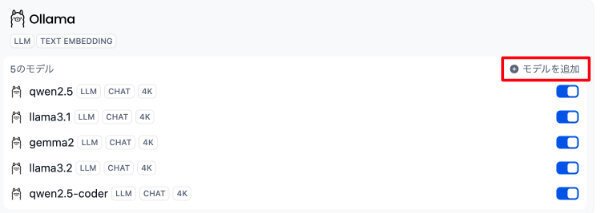
なお、赤枠で囲んだ " モデルを追加 " をクリックすることで、先程の画面が表示されモデルを追加エントリーすることができます。
逆に言えば、ターミナルでモデルをollama runして追加しても、上記の操作をしないとDifyで使うことはできません。
なお、各モデルの説明等は、Ollamaにエントリー後、こちらで見ることができます。
以上で、DifyでQwen2.5を使えるようにする設定のメモを終わります。
補記: Dify+Llama3.2について
最新のLlama3.2は、自分のPCのクローズドな世界でのLLM応用には、結構いいんじゃないか?と感じ始めました。
プチなLLMだからこそ、セキュリティーの観点などで、使えるシーンもあるのでは?、ということです。
ちなみに、Llama3.2は、3種類あります。
” Llama 3.2には、小規模(11B)、中規模(90B)のテキストおよび画像認識可能なビジョンLLMと、エッジ/モバイル向けの軽量でテキストのみのモデル (1B、3B)が含まれており、それぞれ事前トレーニング済み、および命令調整済みバージョンが用意されている。" とのことです。
今回、Ollamaでインストールができるのは、軽量モデルとなりますが、これについてMetaはこう述べています。
”Llama 3.2では、初めての軽量Llamaモデルとなる1Bと3Bをリリースしました。これらのモデルは、開発者が個人化されたオンデバイスのエージェントアプリケーションを構築することを可能にし、要約、ツールの使用、RAG(検索拡張生成)などの機能を備えており、データがデバイスから離れることはありません。”
なお、これらのモデルはQualcomm およびMediaTekハードウェアで利用可能で、ARMプロセッサ用に最適化されている。とのことです。
M2はOK、ということですね。
Mac用の高速レスポンスLLM内蔵のスタンドアローン生成AIシステムが、Dify+llama3.2(1B,3B) で構築できる、ということのように感じます。
これは、これで、面白いかも。
最後に、、
ちなみに、トップ画像は、AI Tuber Kit用に、VRoid Studioで作成した3Dモデル、白魔女のフィオナです。背景画像は、別途、Leonardo.AIでつくりました。
声は、今のところ、VOICEVOXです。
で、とりあえず、思考部分のエンジンをDifyでつくってます。
でも、単純に、GPT4oとか単一のLLMでも使えます。
つまり、フィオナは、人の声を聞いて理解して、質問を考えて??、プロンプト次第ですが、、答えることができます。あ、もちろん喋りにあわせて口パクとかも、します。
正直なところ、あまりに簡単に動いたので、びっくりです。
フィオナとベラドンナ、今はレッスン中です。
今回は、以上です。