
DifyとJinaでRAG on v0.9.1 --ナレッジの作成

はじめに
前回、v0.9.1をベースに、v0.9.0のバージョンアップ内容を中心にメモしました。
このバージョンアップで、Jinaのナレッジ作成用のJina Readerや関連のモデルを使うことで、ウェブを検索して目的の情報を抽出し、それに基づいて生成AIが回答を生成するRAGをDifyで構築することができます。
それに伴い、Difyのヘルプも改定されています。
上記から冒頭の一部を引用します。
Dify ナレッジベースは、 Jina ReaderやFirecrawlなどのサードパーティ ツールを使用してパブリック Web ページからコンテンツをクロールし、それを Markdown コンテンツに解析してナレッジベースにインポートすることをサポートしています。
ちなみに、上記の記載は、10/4/2024現在、Difyの日本語版では、でてきません。日本語版では、古いバージョンの記載であるFireCrawlのみの記述となっています。
ヘルプは、英語版にして、翻訳ツールで日本語化したほうが、いいかもしれません。
このように、従来は、ネット情報をクロールしてナレッジにすることができるのは、v0.6.13 で導入されたFireCrawlのみでしたが、v0.9.0からナレッジ作成用にJina Readerが追加されています。それに伴い、jina-embeddings-v3モデルもJinaに追加されています。これは、マルチリンガルなモデルです。
もっとも、Jina Readerを使う際に、エンベディングモデルとしてJinaのモデルに限定されているわけではありませんので、有名なCohereやOpenAI等、また、最近急速に扱うモデルを増やしているSiliconFlow経由で、BAAI/bge-m3なども使うことができます。
BAAI/bge-m3については、npakaさんがnoteに投稿されています。
この状況は、rerankerモデルにおいても同様です。なお、リランカーモデルとしては、Jinaでは、jina-reranker-v2-base-multilingual などがあります。もちろんDifyのJina経由で使えます。
ということで、今回は、Jinaのナレッジ用のJina Readerを使ったナレッジの作り方をメモしておきたいと思います。これにより、Difyでネット情報ベースのRAGシステムを構築することができます。
なお、以下の記載は、先程ご紹介したDifyのHelpの内容とダブルのですが、ここでの記載が、例によってわかりにくかったので、実際画面の図などを加えて、補記しとこうと思いました。忘れやすい自分のためです。
なお、FireCrawlを使ったナレッジの作成とRAGアプリの例については、以前こちらで記載しています。
準備
以下の説明にあたり、できましたら、前回の記事(冒頭で紹介)にもある、にゃんたさんのYouTube動画を御覧ください。
ここに、RAGとその関連のリランカーモデルやエンベディングモデルの設定の考え方なども説明されています。
実によくできた教育ツールだと思います。
Jina Readerの設定
まず、ナレッジ用のJina Readerを使えるように設定します。
Dify の基本画面を表示します。その右上の各自の登録名称をプルダウンします。
この画面です。この右上の赤枠で囲んだ部分です。
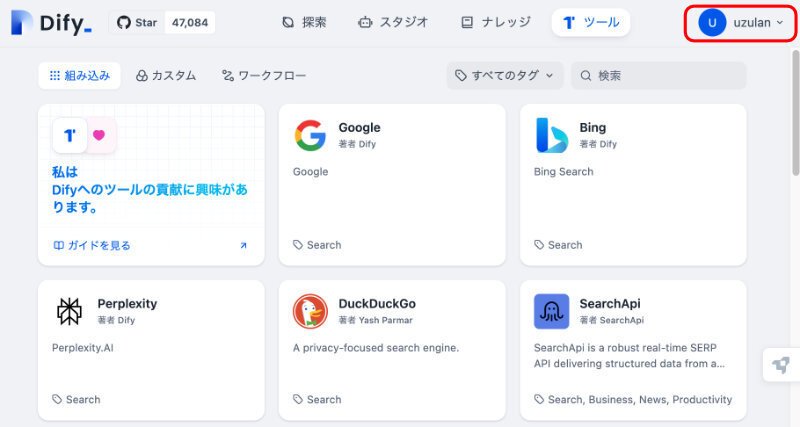
クリックするとメニューがプルダウンします。

上図で、赤枠の先のオレンジの枠の" 設定 " をクリックします。

この画面が、Helpにある最初の画面です。左側のメニューで、赤枠で囲んだ、データソースを選ぶと、左側の画面になります。
ここで、オレンジ枠のところに、Jina,があります。ここの黄緑で囲んだ、設定をクリックします。
ちなみに、その下には、FireCrawlがあります。ここでは、既に使えるようになっています。
Jina Reader Web サイトにログインし、登録を完了して API キーを取得し、それを入力して保存します。
API入力して保存をクリックすると、先程の画面は、このようになります。

以上で、Jina Readerが使えるようになりました。
ナレッジの作成
Jina Readerで情報源のサイトを設定
次にJina Readerを使って、ウェブをクロールして、ナレッジ(Knowledge)を作ります。まず、情報源のアドレス入力まで行います。
下図の基本画面で、上で横に並んだメニューの赤枠で囲んだ " ナレッジ " をクリックします。するとオレンジの枠で囲んだ "ナレッジを作成 "が表示されます。この黄緑の"+"をクリックします。

すると、次の画面が出ます。
ここで、赤枠で囲んだ "ウェブサイトから同期 " を選択します。
私の設定画面では、既にFireCrawlも設定済みなのですが、そのため、先に設定していたオレンジ枠で囲んだFireCrawlの表示が優先されるようです。
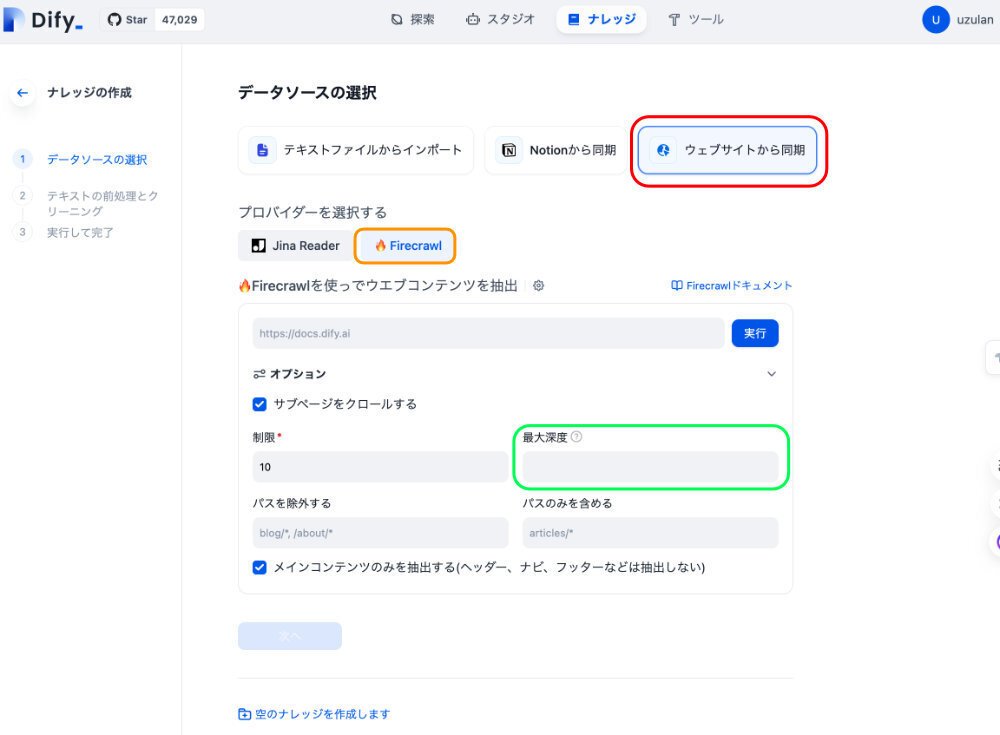
ちなみに、FireCrawlと次に設定するJinaReaderとは少し、設定項目が異なります。特に、緑枠で囲んだ最大震度というのがFireCrawlにはありますが、JinaReaderにはありません。これにより、FireCrawlでは第1層、第2層というように、ウェブサイトの層構造にも対応しています。
今回は、Jina Readerですので、下図のように、左のJina Readerをクリックします。

オプションの項目は、初期値が2つともチェックが入った状態です。
今回はこのまま使います。

サイトマップを使用するの項目に?があるので、それをクリックすると、上図のような説明があります。これについては、理解していませんので、このまま使います。
また、オレンジ枠で囲んだ、制限の数値は、これから一度に読み込むサイト数を示します。色々試したところ、最大値が、100のようです。
また、仮に100と設定して、実際には70のサイト数とすると、そこで単純に読み込みが止まるようです。
次に、情報源としたいサイトのアドレスを入力して実行します。

赤枠のところに、サイトのアドレスを入力します。ここでは、DifyのHelpの日本語版のアドレスをいれました。ちなみに、Difyでは、各言語によって、Helpの内容が異なります。英語版が最新情報のようです。
アドレスを入力したら、右側のオレンジ枠で囲んだ実行をクリックします。
すると、下記のように、スクレイピングされます。ここでは、100と設定しました。50.2秒で、100ページのスクレイピングができているようです。

最下段を示します。
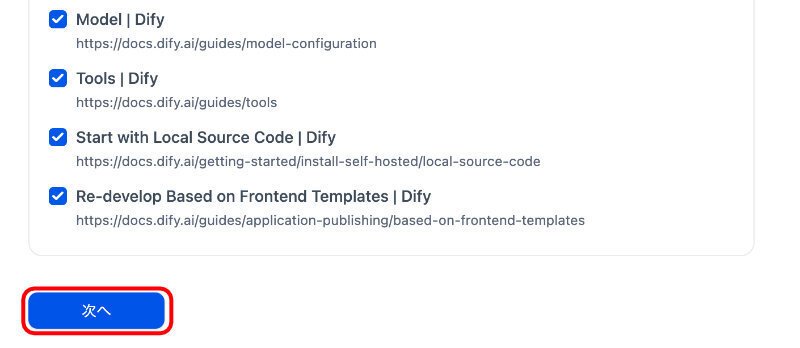
赤枠の次へをクリックします。
テキストの前処理とクリーニング
次へをクリックすると、下図のように、テキストの前処理とクリーニングの画面に遷移します。
チャンク設定

まず、最初のチャンク設定を行います。
この画面以降は、にゃんたさんのYoutube動画に沿って設定していきます。
このチャンク設定では、初期画面として、自動、が選択されています。にゃんたさんのレクチャーに沿って、カスタムを選びます。
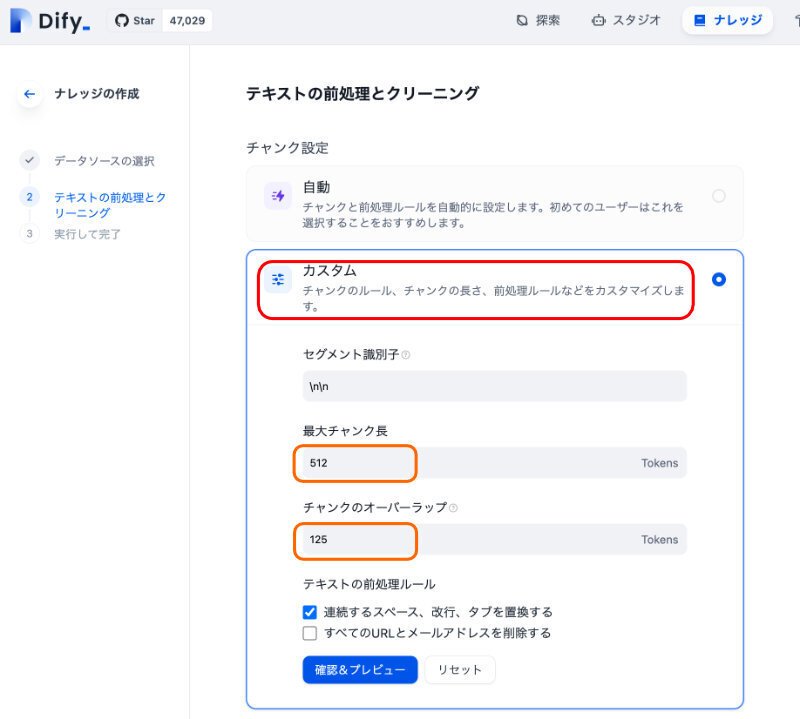
最大チャンク長:512、オーバーラップ:125、と設定します。
ちなみに、自動では、500/50のようです。オーバーラップを増やすことで、精度が向上するのを期待します。
インデックスモードと埋込みモデル
下図のようにしました。
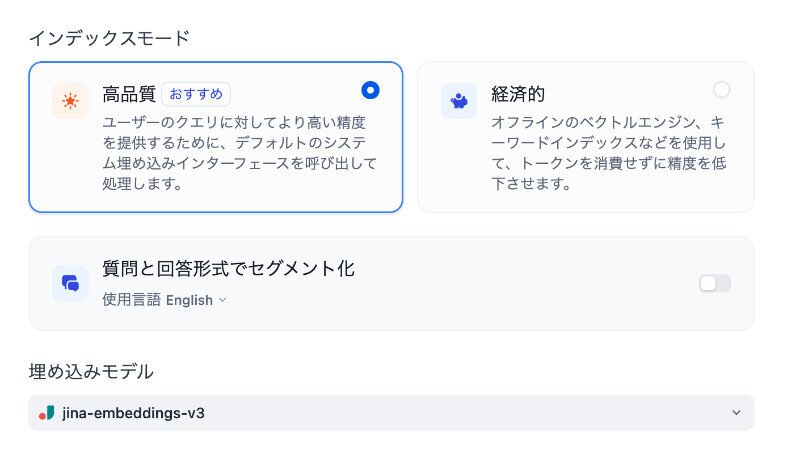
まず、インデックスモードは、高品質にします。また、埋め込みモデルは、ここでは、あえて、Jinaの最新のv3(マルチリンガル)にしてみました。
これまでは、cohereの、embed-multilingual-v3.0にしていました。どちらがいいのかは、現時点ではわかりません。
ただし、留意点として、どちらも無料枠には制限があるようです。
これについては、後述します。
なお、質問と回答形式でセグメント化、は今回は無効にしています。使用言語は、英語、中国語に加え、大幅に増えています。日本語もあります。

検索設定
次のように設定してみました。

ハイブリッド検索を選び、モデルは、Jina-reranker-v2-base-multilingualとしました。
リランカーモデルは、Difyでは、これまでcohere一択でしたが、v0.9.0では、例えば、下記などのようにJinaやSiliconFlowなど選択範囲が増えています。

注意;各モデルの無料使用の制限
次に、一つ上の図の最下段にある "保存して処理" ボタンをクリックすると、埋め込み処理を開始します。順調に進行している例を示します。
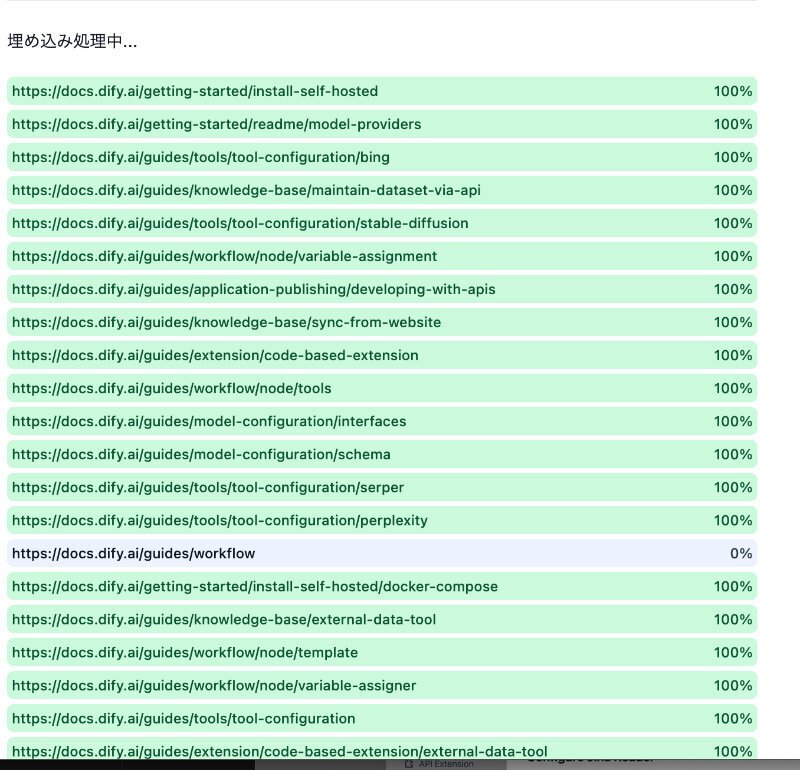
最初は、このように順調だったのですが、何回かトライアルで、ナレッジ作成を行っていくと、エラーが出るようになりました。

エラーの?をクリックすると次のような表示がでてきました。
[jinal Bad Request Error, Your API key has run out of its token-quota. Please top up your key or provide another one with sufficient balance.
[jina] 不正なリクエストエラー。APIキーのトークン割り当てが使い切られました。 キーをチャージするか、十分な残高のある別のキーを提供してください。
また、cohereの場合も同様で、次のメッセージがでました。
[cohere] Rate Limit Error, status_code: 429, b ody: {'message': "You are using a Trial key, w hich is limited to 100 API calls / minute. You c an continue to use the Trial key for free or up grade to a Production key with higher rate lim its at 'https://dashboard.cohere.com/api-key s'. Contact us on 'https://discord.gg/XW44jPf YJu' or email us at support@cohere.com with any questions"}
[cohere] レート制限エラー、ステータスコード:429、本文:{'message': "あなたは試用版キーを使用しています。これは1分間に100回のAPI呼び出しに制限されています。無料で試用版キーの使用を続けるか、より高いレート制限を持つ本番用キーにアップグレードできます。アップグレードは 'https://dashboard.cohere.com/api-keys' で行えます。ご質問がある場合は、'https://discord.gg/XW44jPfYJu' でお問い合わせいただくか、support@cohere.com までメールでご連絡ください"}
とのことで、それぞれ試用版の制限にひっかかったようです。新たに登録し直せば、使えるようになる、と思われます。未確認ですが。
ナレッジの作成
今回は、Silicon Flow経由で新たに登場したBAA/bgeのモデルを使ってみました。

なお、下図のように、再試行、とか …マークをプルダウンで、表示される同期などをトライしましたが、そもそも制限に引っかかっているという事情のためか、基本的に復活は難しいようです。

URLの追加
なお、上図の赤枠の隣にある青いボタンの、+URLを追加、をクリックすると、スクレイピングを追加できます。
Difyのヘルプの場合、100以上あるので、この追加機能で、付け足します。
ナレッジの確認;名称変更
以上で、作成は終了です。
メインメニューに戻ると、新たなナレッジが追加されています。

ナレッジの名称は、後で変更できます。たとえば、オレンジ枠のナレッジをクリックして、左側のメニューの設定を選ぶと下記の画面となります。

赤枠で、囲んだ名称をここで編集できます。
最後にこの画面の一番下にある、保存、をクリックします。(ここでは、表示されてません)
以上で、Jina Readerを使って、ウェブをクロールしてナレッジにする方法のメモを終わります。