
DIfy最新版(v0.7.3)でチャットフローを使い画像生成ツールを比較してみました ---その1

0.はじめに
Difyは、マルチモーダル等の生成AIの様々な実験環境の設定を比較的簡単に設定できて色々とトライアルができる場、と感じています。
一方、ビジネスと言う観点からは、現状は、扱えるデータ量など、ややキャパ的に劣り、実用上の観点からはこれからというのが実際のところでしょうか。ただ、とても進歩が早く機能がどんどん増えています。
何より、自分のPC上でDifyを展開して試用する分には、お試しが各社のAPIの料金だけでほぼ済み、コスト的にかなり気軽に各社の生成AI関連の技術を比較できるのが最大の長所です。
そのDifyのバージョンが、9/3に、0.7.3になっています。8/26に0.7.2、8/19に0.7.1、8/14に0.7.0と、約1週間に一度のバージョンアップです。今回も、予想通り9月第1週にv. Upしました。
さらに9月中に、RAG関連で大バージョンアップがあるかも、と期待しています。
ところで、前回初めて試用したAI Tuber Kitは、音声入力、音声出力をオリジナルの3Dモデルに実行させることが容易にできました。コアの生成AI部分をDifyで作成し、そのAPIでAI Tuber Kitに接続できています。
なお、トップの画像は、AI Tuber Kit用にV Roid Studioで作成したオリジナルキャラとLeonardo.AIで作成した背景を合成した画像です。
このキャラが、音声を認識して、音声で応えてくれます。
このAI Tuber Kitも、進歩が早く、当時v.1.33.0だったのが、現在は、v.1.40.0となっています。ニケちゃん様、すごいです。当面、こちら関連、たとえば、合成音声ツールなども含め追っていきたいと思います。
一方、マルチモーダルという観点では、画像関連の取り扱いがあります。
別途、Leonardo.AIなどの動向も見ているのですが、最近のSD3の動きやFluxなども気になります。一般的には、静止画については、どうもMidjourney優勢な印象も受けますが。
そして進化速度が顕著なのが動画化の動向です。Runwayが40秒生成をリリースしました、とか。
さて、ということで、今回そして次回以降メモする話題は、次の3点を考えています。
1.Difyのバージョンアップの概要、関連のnoteの記事等のメモ等
2.Dify環境のチャットフローベースでの画像生成AIツール関連のメモと試用結果
→→→ これについては、やや長くなったので、2回にわけて公開します。
そして、次回?以降、、
3.前回試用したAI Tuber Kit関連の話題。オリジナル画像の作成やYouTube Data API関連等とバージョンアップ内容と関連ツール等
と、続く、、つもりです。
1.Difyの新機能等
アップデート状況(v0.7.0 - v0.7.3)
下記は、githubにあるDifyのリリースにリンクしています。
v0.7.0
下記、関連のnoteの記事を引用します。こちはら、いつもいち早くDifyの最新版の概要について説明して頂いてます。
このリリースで注目されるのは、下記githubのコピペの冒頭にある会話変数の導入です。それにともなって新しいノードの変数割当ノード(Variable Assigner Node)が導入されています。これらについては、Difyの関連ブログに詳しい説明があります。
また、新モデルとしてOpenAIのGPT-4o-2024-08-06等が使えるようになりました。
Silicon FlowのLLMも同社として初登場しています。
なお、この後で、このバージョンの後に追加されたSilicon FlowのText to Imageツールもご紹介します。
以下、githubオリジナルの各冒頭にある新機能、モデル、ツールなどの日本語訳をコピペしました。
🚀 新機能
会話変数と変数割り当てノード
もっと詳しく知る:
🧠 モデル
GPT-4o-2024-08-06モデル
GLM-4-Longモデル
Zhipu埋め込み3モデル
Wenxin Yi-34b-チャットモデル
HuggingFace TEIテキスト埋め込みと再ランク付けモデル
Siliconflow LLMとテキスト埋め込みモデル
360-Zhinaoプロバイダー
🛠️ ツール
D-IDツール
GitLabツール
⚙️ 機能強化
Elasticsearchベクターデータベースのサポート
出力でのEChartsによる描画のサポート
ワークフローインタラクションの改善
実行ID付きワークフローログのフィルター
DOCX文書のハイパーリンク解析
他のVectorDB用のベクトルフィールド
詩のリクエストタイムアウト
データセット埋め込みモデルの更新
JSONプロセスツールにデコードオプションを追加する
エクスポートされたDSLファイル内の英語以外の文字のサポート
NEXT_TELEMETRY_DISABLEDのサポート
v0.7.1
本リリースで、アプリのアイコンがカスタマイズできるようになりました。
例えば、こんな風に作ることができます。

アプリが溜まってくると、これによる視認性の向上が結構大事なのを実感します。もちろん、オリジナリティー向上には、重要だと思います。
モデルとして、Chat-GPT-Latest等が使えるようになりました。
また、JinaのTokenizer Toolが追加されています。これは、" テキストをトークン化し、長いテキストをチャンクに分割する無料API "とのことです。RAG関連と思われます。
以下、Githubからの引用です。
🚀 新機能
カスタムアプリアイコン:カスタムアイコンでアプリをカスタマイズしましょう
OpenAI構造化出力のサポート:OpenAIの構造化出力をサポートするようになりました。
Dify Sandbox v0.2.6 : 必要なPythonパッケージをインストールします
🧠 モデルの更新
ChatGPT-4o-Latest : ChatGPT-4o-Latestモデルを追加しました
🛠️ 新しいツール
Jina Tokenizer Tool : 新しいトークナイザーツールを追加しました
GitLabツール: GitLabツールの統合
⚙️ 機能強化
Xinference 認証システム: @ethan-fly による#7369での Xinference の認証システムのサポートが強化されました。
Ruff Formatter : より良いコードフォーマットのためにRuff Formatterを導入しました。
Ruffアップデート: Ruffを0.5.xから0.6.xにアップデートしました
API Python依存関係の再編成
v0.7.2
チャットフローのダイアログカウント(何回目のチャットかのカウント数)が使えるようになりました。これにより、例えば、5ターン目の会話(チャット)で、そろそろ疲れたので、コーヒータイムにしましょう、と言わせる、、なんてことができる、ということでしょうか。今後試してみたいと思います。
新ツールとして今回ご紹介するSiliconFlowのtext2img(テキストから画像を生成するツール)等が追加されました。
その他、UI/UXの改善、バックエンドの改善が行われました。
🚀 新機能
チャットフローのダイアログカウントのサポートを追加しました
MoonshotモデルのJSONモードのサポートを追加しました
Qwen text-embedding-v3のサポートを追加しました
siliconflow text2imgツールのサポートを追加しました
OneBotプロトコルツールのサポートを追加しました
Wenxin BGE-LargeおよびTao埋め込みモデルのサポート
⚙️ 機能強化
UI/UXの改善:
改行をサポートするツールチップコンテンツの改善
アサインノード追加モード記述の著作権を改善しました。
メニュー折りたたみの読みやすさを改善しました
テーマ関連のCSS変数値を更新しました
Langfuseビューボタンを追加しました
「タグ削除」確認モーダルを更新しました
バックエンドの改善:
さまざまなAPIコンポーネントにRuffの再フォーマットを適用しました。
CODE_MAX_PRECISIONのサポート
ワークフローの最大ステップ数を50に増加
LLMノード出力にfinish_reasonを追加しました
pgvector全文検索設定のサポートを追加しました
会話をupdated_at descで並べ替えるサポートを追加しました
S3バケットが存在しない場合は作成する
ストレージタイプとGoogleストレージ設定をワーカーに追加しました
v0.7.3
9月には、大バージョンアップかと期待していましたが、今回のはそうでもないようです。
目玉は、メッセージ数の監視ページ設定など、今後の大規模化やコマーシャル化等に備えた管理ツールの強化のようです。
さて、やっと、Perplexityがツールとして導入されました。
具体的に見てみると、現時点で使える内部のLLMは、metaのLlama3.1-sonarのみです。3種類あります。本ツールのmodelメニューの画像をアップします。

ただし、max Tokensが4096です。Perplexityの強みを果たして活かせるのか、現時点ではちょっとわかりません。
その他、株価検索ツール等の導入や、様々な機能強化がなされています。
それぞれ、今後、具体的な確認をしていきたいと思います。
以下、Githubのコピペです。
🚀 新機能
メッセージ数: 監視ページからメッセージの使用状況を直接監視できるようになりました。
Azure AI Studioプロバイダー: Azure AI Studioをプロバイダーとして追加しました。
Perplexity検索ツール:パープレキシティベースの技術を利用して検索機能を強化する新しい検索ツールを導入しました。
株価検索ツール:Alpha Vantageから株価を検索する
⚙️ 機能強化
Langfuse View Button : 新しいView Buttonによるユーザーインターフェースの改善
GLMモデルの価格と最大トークン数: GLMモデルの価格と最大トークン数が修正されました。
アプリアイコンを回答アイコンとして使用: アプリアイコンを回答アイコンとして使用できるようになりました。
変数リスト内の配列型: 使用可能な変数リスト内の配列型のサポート
質問分類プロンプト最適化:プロンプトの精度を向上
コード実行設定:コード実行リクエストの設定のサポートを追加しました。
以上、v0.7.0-v0.7.3までの新機能等の概要でした。
2.Difyの画像生成ツール
2-1. 画像生成用のツールについて
Difyには、9/2/2024現在、複数の画像生成用ツールが提供されています。
たとえば、下記の4社からのツールがあります。各番号の次の表記が各ツールのタイトル名となっています。
各タイトルの下に、場合によっては複数のツールが記載されています。
これらはそれぞれ、従来の基本形とワークフロー形式それぞれで用いることができます。ただ、ワークフロー形式での適用事例は、あまりみかけないようです。
後半では、ワークロー形式で用いる場合の各パラメータの設定事例などをメモしておきたいと思います。(次回の予定)
まず、4社のそれぞれのツールについてピックアップして、概要と特徴等を説明します。
2-1-1.Dall-E (by OpenAI) @v0.5.0?-
・Dall-E3
・Dall-E2

Open AIによる有名なツールです。Dify用の画像生成用ツールとしては、かなり前(v0.5.0?)から使用可能で、Difyの画像生成機能の紹介事例は、ほぼこのツールが使われています。
ツールは2種類用意されています。各ツール名と同じ名称のモデルが用いられています。
2-1-2.Stabillity @v0.5.0?-
・Stable Diffusion
i. core
ii. Stable Diffusion 3
iii.Stable Diffusion 3 turbo


これも、Dall-Eと同様、画像生成用ツールとしては、以前から使用可能でした。ただ、公開されている使用例は少ないようです。
使われているモデルは、変わってきているようです。この画面は、現時点での最新版です。
今回実際使ってみて始めて知ったのですが、ツール名は1つですが、モデルは、3種から選択できて、SD3が2種とcoreです。
これらは、いずれも、v2beta(ベータ)という新しい世代のREST APIと思われます。
v2betaには、次の3種類があります。また、その中のSD3は、さらに3種類あります。本ツールでは、太字にしたモデルが採用されていると思われます。つまり、同社の最先端の技術です。
1. Stable Image Ultra
2. Stable Image Core
3. Stable Difusion 3
・SD3 Medium - the 2 billion parameter model
・SD3 Large - the 8 billion parameter model
・SD3 Large Turbo - the 8 billion parameter model with a faster inference time
ちなみに、有名なSDXL等は、現在、v(version) 1という括りとなっています。DIfyの本ツールには、採用されていません。
v1には、SDXL 1.0,SD 1.6、SD Beta の3種類があります。SD Betaは、エンジンのIDとして、stable-diffusion-xl-beta-v2-2-2、とありますので、SDXL系の最新ベータ版という位置づけのようです。
なお、v1は、今後も提供されますが、新規開発は、終了とのことです。
SDv1ベースの画像生成AIアプリ各社は、結構大変な状況かもしれません。
SD3が追加されたのは、リリースの記載からの推定ですが、v0.6.4からと思われます。
2-1-3.Novita AI @v0.6.12-
・Novita AI Text to Image
Models
i. Flux 1種類のみ
ii. SD系 多数を網羅(3M;1種類, XL系, +LoRA, +VAE 等)


Novita.AIのLLM等は、以前から使用できていましたが、画像生成ツールは、v0.6.12から追加されています。上の図の赤枠のツールとなります。
このツールは設定のパラメータが非常に多く、また、モデルもかなり多数用意されています。
例えば、SDXL系を例にとると次のようなモデルの種類があります。
"protovisionXLHighFidelity3D_release0630Bakedvae_154359.safetensors" "protovisionXLHighFidelity3D_beta0520Bakedvae_106612.safetensors" "crystalClearXL_ccxl_97637.safetensors" "protovisionXLHighFidelity3D_releaseV660Bakedvae_207131.safetensors" "protovisionXLHighFidelity3D_release0620Bakedvae_131308.safetensors" "juggernautXL_version2_113240.safetensors" "leosamsHelloworldSDXL_helloworldSDXL50_268813.safetensors" "juggernautXL_version6Rundiffusion_151968.safetensors"
ただし、Dify用の設定についての説明がなく、とてもわかりにくい、という印象を受けます。
そもそもモデル名が選択ではなく下の図の赤枠のように空欄で、上記に示したモデル名を自分で入力する必要がありますが、Dify関連のヘルプにはモデル名が記載されていません。
オレンジの丸枠で囲んだ小さな字の?に記載されているNovita.AIのHPを探すことになるのですが、わかりにくいです。さらにモデル名以下のパラメータが18もあります。そのうちで、8個が入力必須の項目です。
エラーがでても、何が悪くて画像生成できないのかデバッグしてもよくわかりません。
そもそもモデル名が間違っている?、と疑念を抱き、ここで、一旦ギブアップしました。なお、最終的には、画像生成ができました。
使いこなすのは、初心者にはかなり困難と思われます。
ただ、これらのパラメータを変数にして、Difyで入力するように設定すれば、ちょっとした画像生成AIアプリが組める可能性を感じます。LoRAや、VAE、さらにrefinerの設定もできます。
使いこなす中で、各モデルの特徴と使い方もわかってくるでしょう。
ただし、現時点でのDifyでは、変数への入力が開始ノードのみですので、UI/UXの観点から、使い勝手のいいアプリ構築は、難しいかもしれません。
とはいえ、API料金のみで色々試せる、という点は評価できると思います。
有名な6本指問題などの不具合は、v1系の場合、Refinerでほぼ修正が可能です。また、クオリティーも相当向上します。画風の変更もLoRA等で容易に可能です。現時点は、v1系の方がv2betaよりもむしろ安心して使えるといえるかもしれません。課題は生成速度です。
なお、前提としては、SDの技術への理解が必須なように思います。
2-1-4.Silicon Flow @v0.7.2
・Stable Diffusion
i. Stable Diffusion 3
ii.Stable Diffusion XL
・Flux
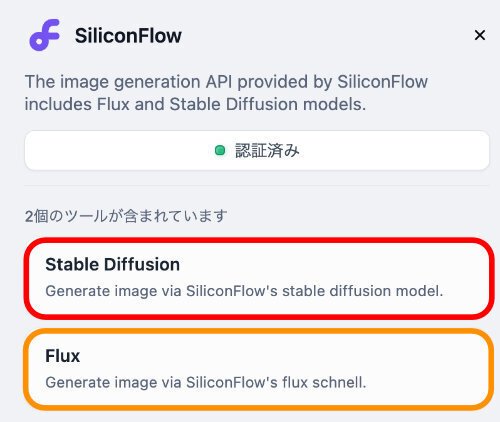

Silicon Flowは、中国の会社で、API入手に必要な最初のHPへの登録には、電話番号の入力が必須です。なお、APIは、無料です。カード情報の入力等は不要です。
Silicon Flowの本ツールは、今回のv0.7.2から使えるようになりました。まずは、最近話題のSD3系とFluxが簡易的に使えるというのが本ツールの特徴です。
ツールは上の図で示すように2種類用意されています。SD系とFluxです。
またSD系は、下のツールの図のようにSD-3とSD-XLの2種類のモデルから選べます。SD-3は、登場時期からSD3 Mediumと推定されます。
ただし、それぞれのパラメータ調整は、全体へのプロンプトの効果の調整であるイメージガイダンス程度です。Novita AIとは対称的に極めてシンプルです。
逆に言えば、本当にそれぞれのモデルの特徴が引き出せるのかは、よくわかりません。
これは、Fluxも同様です。
Silicon Flowのツールは、いずれもシンプル設定、かつ無料で、使用できます。
各ツールの概要は、以上です。
少し長くなったので、一旦ここで区切ります。
以下、次回予定している内容の項目(予定)です。