
DIfy最新版(v0.7.3)でチャットフローを使い画像生成ツールを比較してみました ---その2

はじめに
今回は、下記に続いて、Difyのチャットフローで、画像生成ツールを実際に使ってみます。
ちなみに、Difyで画像生成をするケースを検索してみたのですが、エージェントの基本形で、Dall-Eを使った例の紹介がほとんどでした。
また、次のnoteの記事が、ワークフロー形式でStable DiffusionのAPIを使って画像生成するアプリ、としてありました。7/27/2024のリリースです。
こちらで紹介されているのは、HTTPリクエストノードを使って、Stability AIにDifyからAPIを送信して、画像を得る、という方法です。
原理的に、画像生成用のモデルの指定や各パラメータを細かく設定できますから、本来のStable Diffusionの性能を引き出すポテンシャルがあると思われます。
ただ、それらの指定は結構手間なので、突っ込んだ使い方をするにはSDをかなり理解していないと難しい方法ではあります。
今回のDifyツールを使う方法は、ほとんどのツールが、細かい指定ができません。例えばモデル指定も大雑把です。そのかわり比較的簡単に画像を得ることができます。
細かな指定のできるツールという点では、いまのところ唯一の例外がNovita.AIのText to Imageツールです。
Difyでの画像生成では、用途と目的によって各方法やツールを使い分けるということだろうと思います。
では、実際にワークフローに画像生成ツールを組み込んで画像を生成してみたいと思います。
2.Difyの画像生成ツール
ここでは、チャットフローに各ツールを組み込んでみます。
2-2. 画像生成ツール用ワークフローの動作確認
2-2-1. 画像生成ツール用ワークフローの最小構成例
画像生成だけであれば、フローは極めて単純です。
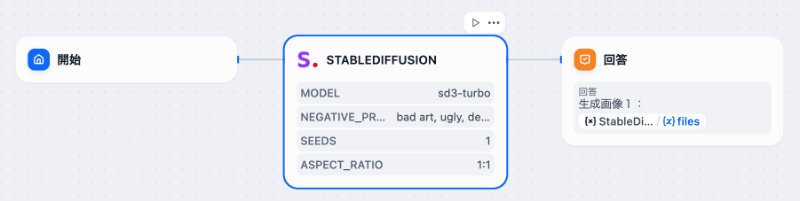
開始ノード → 画像生成ツール → 回答ノード
という構成です。
例えば、Stability AIのStable Diffusionツールの場合は、こうです。
なお、他の画像生成ツールでも基本構成は同じで画像を得ることができます。
これを使った画像生成の例がこちらです。当ブログの主役の一人、白魔女のフィオナさんです。実写風ではなく、イラスト風ででてきました。描写は結構細かいです。月が2つある世界のようですね。

プロンプトの入力は、チャットフローの開始ノードに標準の(x)sys query を使います。
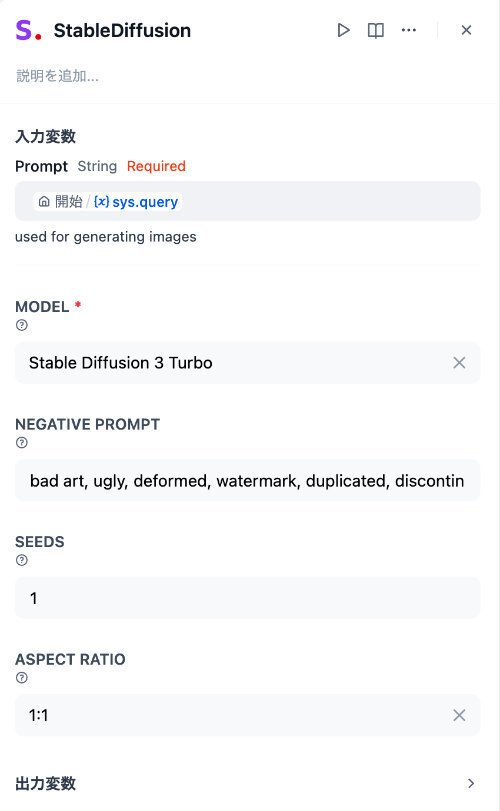
ポイントとなるStable Diffusionツールの設定は、例えば、このようにします。これの各パラメータの内容については、後述します。
最後の回答ノードの設定を示します。
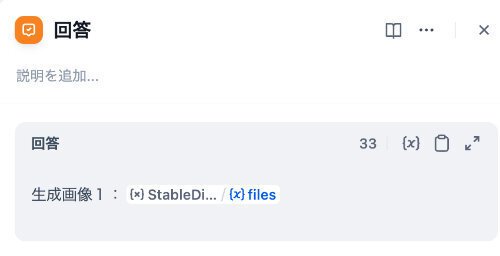
ここでの注意点は、出力に(x)filesを選ぶ、ということです。
ちなみに、さきほどの画像は、プレビュー機能でデバッグした結果です。Difyの右端にこのように表示されます。
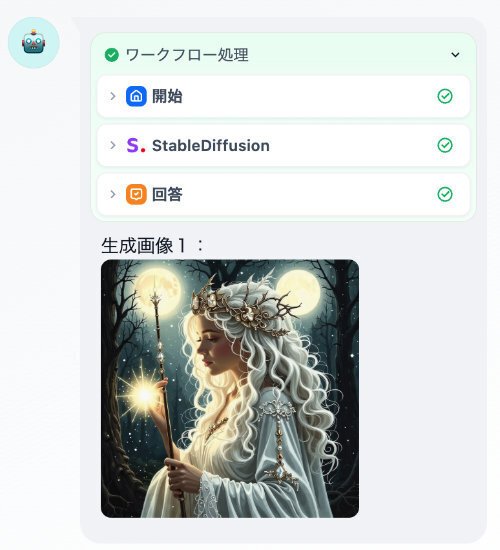
この画層を右クリックで出るメニューで一旦保存して使いました。
2-2-2. 各画像生成ツールを組み込んだワークフローの例
同様に各画像生成ツール用にアプリを作れば比較検討できます。
いちいちアプリを切り替えたり、ノードを切り貼りするのもちょっと万灯なので、下記のようなフローをつくってみました。
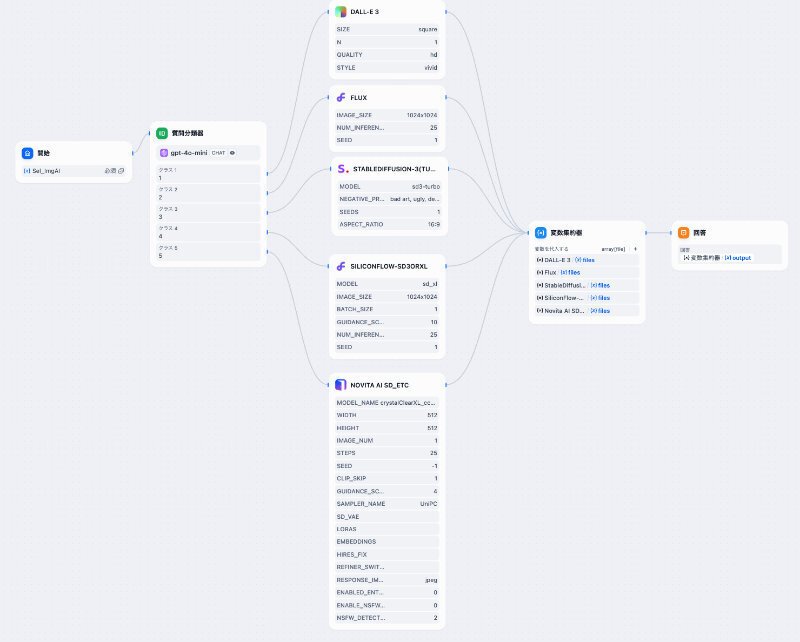
前回ご紹介した画像生成ツールが、4社で5ツールあります。
これらを、ブルーマークの開始ノードで各ツールの選択を行い、次の緑色マークの質問分類器でcase文機能を作って振り分け、選択に従った画像生成ツールに飛ばします。
下記の記事で使ったのと同じ考え方です。
ここまでは、良かったのですが、結果を次の水色の変数集約器で出力をまとめようとしたら、エラーがでました。
変数集約器(Variable Aggregator)は、Arrayタイプが使えないとのことです。ここでは、Array[files]型の出力を使っています。
そこで、次のフローに変更しました。わかりやすいですが、あまりスマートではないです。
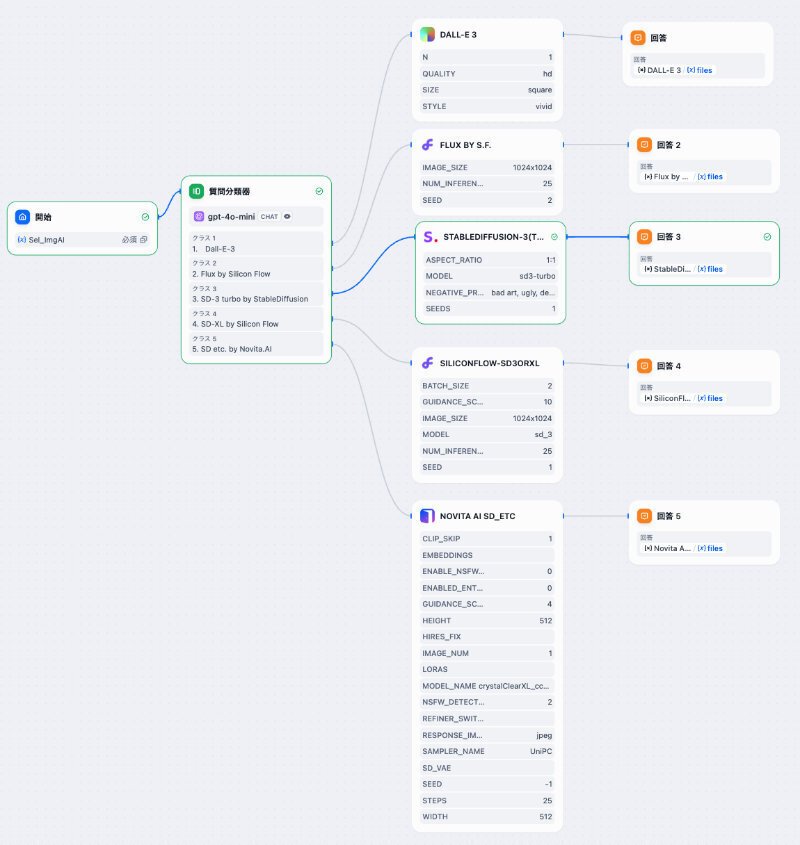
これを使って、各画像生成ツールを動かしてみました。
ちなみに、先程のStable Diffusionで、モデルをcoreとすると、同じプロンプトで次のような画像がでました。

ここで設定されているのは、画風がイラストとリアルの間ぐらいのようです。昔の火星シリーズの挿絵を連想します。火星のプリンセス、とかですね。
また、これは、ちょっとLeonardo.AIの傾向に近い印象も受けます。Leonardo.AIの最新モデルのPhoenixは、このあたりがルーツなのかもしれません。
一旦ここで区切ります。
次回は、下記を予定しています。