
Dify v0.8.1、v0.8.2が、OpenAI o1シリーズをサポートしてリリース

はじめに
つい先日、v0.8.0がリリースされ、パラレル実行が実現したDifyですが、日本時間で、13日に、v0.8.1、そして同日にv0.8.2が、続けてリリースされました。
これらのリリースで、なんと、OpenAI o1シリーズのサポートに対応しました。これは9月12日に発表された今話題の新しいモデルです。
OpenAI o1シリーズは、OpenAI o1-previewとOpenAI o1-miniの2つです。
この2つのモデル、共に計算パワーをとても食うってことで、使える有料ユーザーには週単位の厳しい使用制限が入ってます。(30回/週;preview、50
回/週;mini)週単位の指定です。
また、APIを使えるのは、Tier 5という最も課金をしている最高レベルのユーザーのみ、こちらも20RPMという使用制限付きです。
もっとも、20RPM(1分に20回)というのは、一般ユーザでは十分な感じもしますが。
そのような厳しい制限のあるモデルが、Dify経由では、即、使えるということです。
かなり画期的ではないかと思います。
ただし、新モデルの動作の仕組みの特徴から、料金が飛躍的に高くなりそう、など、通常のAPI使用と比べて、留意しておくことがありそうです。
また、現時点では、従来のGPT 4omni等に比べ全ての点で優れているということではなさそうです。たとえば、通常の文章作成などは、従来のGPT 4o系の方が優れているとOpenAIが述べています。
さらに、Difyだと、他社のLLMも使えますし、、、
つまり、料金体系も考慮して、タスクに最適なLLMを使うということが大事だということです。
それらについて、今回は、関連事項などをメモしておきます。
Difyの新リリースの内容
現在(9/15/2024)、下記リリースでは、v0.8.2が最新となっています。その下に、0.8.1の説明があります。
以下、上記のgithubのリリースからの日本語訳の抜粋です。
v0.8.1について
🚀主な特徴
✨ OpenAI o1シリーズモデルのサポート
o1-previewとo1-miniの両方のサポートにより、OpenAIの最先端モデルのパワーを解き放ちます。これらの追加 により、さまざまなニーズを満たす柔軟性と強化されたAI機能が提供されます。。
🛠️改善とバグ修正
ワークフローの強化
マルチ並列実行の修正
複数の並列ブランチと条件パスをシームレスに実行するワークフローの問題を解決しまし た正確なブランチ出力
質問分類ノードの異なるブランチで同時に出力されていた問題を修正し、より信頼性の高い結果を実現しましたIF-ELSEノードの安定性
IF-ELSEノードが同じ後続ノードに接続すると実行が停止する問題を修正し、ワークフローの一貫した実行を保証します。回答ノードの完全なデータフロー
反復中に回答ノードのストリーム出力で欠落していたコンテンツを修正し、包括的なデータフローを保証しましたストリームチャンク/メッセージイベントセレクター
新しい from_variable_selectorで、データストリームをより細かく制御できます。この機能により、ストリームチャンクとメッセージイベントをより正確に管理し、よりスムーズなデータフローを実現できます。
Ollama 埋め込みモデル
エラー解決
厄介な500エラーを含むOllama埋め込みモデルの追加に関連するバグを修正し、よりスムーズな統合エクスペリエンスを実現しました。
UIとユーザビリティの強化
アイコンの配置の改善
チャット入力エリアの画像アップロードアイコンの位置ずれを修正し、よりすっきりとしたインターフェースを実現しました。マークダウンの読みやすさの向上
マークダウンの段落の余白を調整し、読みやすさと全体的なユーザーエクスペリエンスを向上させましたコピーショートカットの修正
ワークフローのデバッグとプレビューパネルのコピーショートカットの問題を解決し、よりスムーズなナビゲーションを実現しました
その他の修正
ローカライズされた翻訳
翻訳の地域化を強化し 、よりローカライズされたユーザーフレンドリーなエクスペリエンスを提供します。値の取り扱いとラベルの問題
データの一貫性を高めるために、真理値取り扱いと応答フォーマットラベルの問題を修正しましたVariableEntityTypeバグ
VariableEntityTypeバグを修正することで命名規則の不一致を解決しました
🌟その他の機能強化
岩盤の改善
Claudeモデルのサポート
BedrockのClaudeモデルはresponse_formatパラメータをサポートし、より多くのカスタマイズオプションを提供します。クロスリージョン推論
Bedrockのクロスリージョン推論のサポートが追加され、異なるリージョン間での展開の柔軟性が向上しました。
編集者向けAPIキー作成
編集者はAPIキーを直接作成できるようになり、開発ワークフローが効率化され、セキュリティが強化されました
v0.8.2について
🚀 新機能
O1シリーズモデルのサポート:
エージェントアプリにReACTワークフロー(注1;下記)に特化したO1シリーズモデルのサポートを追加しました。アプリケーションで ReACT を活用する人々に新たな可能性が開かれます。サービスAPIワークフローログ:
サービス API 経由で詳細なワークフロー ログにアクセスできるようになりました。これは、内部で何が起こっているかを注意深く監視する必要がある人にとっては大きなメリットです。
🛠️ バグ修正
スコアしきい値の修正: スコアしきい値が「なし」に設定されている問題を修正し、より信頼性の高いパフォーマンス指標を確保しました。
ワークフローのVar-Selectorの更新:ワークフローでエッジが変更されたときにVar-Selectorが更新されないバグを修正しました。
コピー&ペーストのショートカット:ワークフロー実行パネルのテキストエリアのコピー&ペーストのショートカットの問題を解決し、テキスト操作が再び簡単になりました。
今回のリリースはこれで終わりです。引き続きフィードバックと貢献をいただき、一緒にこのプラットフォームをさらに良くしていきましょう。
注1:ReACTは、Reasoning and Actingのことだと思います。
以下は、Google AI Studio による説明です。
今回の、o1シリーズの動作原理の説明にもなっているように思います。
引用:
ReACT (Reasoning and Acting) ワークフローは、LLM (大規模言語モデル) の推論能力と外部ツールやAPIのアクション実行能力を組み合わせた、複雑なタスクを実行するためのフレームワークです。
従来の LLM は、テキスト生成や翻訳など、主に言語処理に特化していました。しかし、ReACT ワークフローでは、LLM が 「思考」と「行動」 を繰り返すことで、より広範なタスクに対応できます。
具体的には、ReACT ワークフローは以下のような手順で動作します。
思考 (Reasoning): LLM は、与えられたタスクを達成するために必要なステップを考え、計画を立てます。この計画には、必要な情報やツール、API などのアクションが含まれます。
行動 (Acting): LLM の計画に基づいて、外部ツールやAPI が実行され、情報収集やアクションの実行が行われます。
観察 (Observation): ツールやAPI の実行結果が LLM にフィードバックされます。
思考 (Reasoning): LLM は、フィードバックされた情報に基づいて、次のステップを考え、計画を更新します。
これらのステップを繰り返すことで、LLM は複雑なタスクを段階的に解決していきます。
Open AI o1シリーズについて
これについては、いつも参考データとして引用させていただいているニャン太さんのYouTube動画が、まずは、概要を伝えていただいていると思いますので引用させていただきます。
色々トライアルする前に、是非一度ご覧いただきたいと思います。
o1シリーズの概要
o1シリーズは、プロンプトを受け取ったら、思考する、色々と考える、という手順を入れてる、というのが最大の特徴のようです。
また、使用回数の制限については、ほとんどリリース直後にChatGPT研究所が、このようなアラートをXにあげています。さすがです。

o1シリーズの特徴と留意点
本家のOpen AIによる本シリーズの説明は、こちらです。
https://platform.openai.com/docs/guides/reasoning
要約すると、ポイントは2点。
1. 数学やコーディング等の高レベルの質問に対しては、かなり高精度の回答をだすが、通常の文章作成等のレベルではそれほどではない。GPT-4omni以下。
2. 本シリーズのモデルは、常に色々と多方面から検討して考える。かつ、その過程も含めたトークンもすべて請求するので、結構、使用コストが高い。
ということのようです。
トークンの考え方
そのあたりを、OpenAIは、上記の引用先でこう言っています。
引用:
" o1 モデルでは、推論トークンが導入されています。モデルはこれらの推論トークンを使用して「考える」ため、プロンプトの理解を分解し、応答を生成するための複数のアプローチを検討します。推論トークンを生成した後、モデルは目に見える完了トークンとして回答を生成し、推論トークンをコンテキストから破棄します。"
その結果、トークン等は、こうなっています。
" o1-preview および o1-mini モデルは、128,000 トークンのコンテキスト ウィンドウを提供します。各補完には、出力トークンの最大数の上限があります。これには、非表示の推論トークンと表示される補完トークンの両方が含まれます。出力トークンの最大制限は次のとおりです。
・o1-preview: 最大 32,768 トークン
・o1-mini: 最大 65,536 トークン
補完を作成するときは、コンテキスト ウィンドウに推論トークン用の十分なスペースがあることを確認することが重要です。問題の複雑さに応じて、モデルは数百から数万の推論トークンを生成する場合があります。使用される推論トークンの正確な数は、チャット補完応答オブジェクトの使用状況オブジェクトで確認できます "
プロンプト作成の留意点
さらに、使いこなすにあたって、このような ”考えるLLM” には、これまでのような余計なプロンプトは不要とのことです。
たとえば、、、
引用:
” これらのモデルは、簡単なプロンプトで最もよく機能します。少数のプロンプトやモデルに「ステップごとに考える」ように指示するなどのプロンプト エンジニアリング手法では、パフォーマンスが向上しない可能性があり、パフォーマンスが妨げられることもあります。次に、ベスト プラクティスをいくつか示します。 ”
プロンプトはシンプルかつ直接的なものにしてください。モデルは、詳細なガイダンスを必要とせずに、簡潔で明確な指示を理解して応答することに優れています。
思考の連鎖を促すプロンプトは避けてください。これらのモデルは内部で推論を実行するため、「段階的に考える」または「推論を説明する」ように促す必要はありません。
明確にするために区切り文字を使用する:三重引用符、XML タグ、セクション タイトルなどの区切り文字を使用して、入力の異なる部分を明確に示し、モデルがさまざまなセクションを適切に解釈できるようにします。
検索拡張生成 (RAG) での追加コンテキストを制限する:追加のコンテキストまたはドキュメントを提供する場合は、モデルが応答を過度に複雑にしないように、最も関連性の高い情報のみを含めます。
あらら、これまで、プロンプトエンジニアリングで、先駆者の皆様から色々サジェスチョンしてもらった手法等については、これらのモデルの場合、適用するのはむしろダメなようです。
これからは、どんどんフールプルーフ化していくという兆しにも感じます。
おバカも使えるLLM、ですかね。
さらに、これまでの、特定個人の言動から推論して、あれ、それ、これ、でも通じるようになるとか。などと、思わず連想してしまいました。
o1シリーズのトークン数とコスト
さらに、コストの観点で、こんなことを言ってます。下記引用がちょっと長いので要約すると、
要は、、内部で考えるのに費やした分のトークンは結果として表に表現されなくても、全部請求される。つまり、考えた過程の分も出力トークンに全て含まれ、請求される、だからAPI料金も高いよ。んんん、チェック用の変数を用意したので確認してね、使用制限も設定できるよ、ということのようです。
エンタープライズの管理者は大変かも、ですね。
引用:
" o1 シリーズ モデルでコストを管理するには、パラメータを使用して、モデルが生成するトークンの合計数 (推論トークンと完了トークンの両方を含む) を制限できますmax_completion_tokens。
以前のモデルでは、max_tokensパラメータは生成されるトークンの数とユーザーに表示されるトークンの数の両方を制御していましたが、これらは常に同じでした。ただし、o1 シリーズでは、内部推論トークンにより、生成されるトークンの合計が、表示されるトークンの数を超える場合があります。
max_tokens一部のアプリケーションはAPI から受信したトークンの数の一致に依存する可能性があるため、o1 シリーズでmax_completion_tokensは、推論トークンと表示完了トークンの両方を含む、モデルによって生成されるトークンの合計数を明示的に制御する方法が導入されています。この明示的なオプトインにより、新しいモデルを使用しても既存のアプリケーションが機能しなくなります。このmax_tokensパラメーターは、以前のすべてのモデルで以前と同じように機能し続けます。
o1-preview: 最大 32,768 トークン(注;Difyでも設定できます)
o1-mini: 最大 65,536 トークン(注:同上)
補完を作成するときは、コンテキスト ウィンドウに推論トークン用の十分なスペースがあることを確認することが重要です。問題の複雑さに応じて、モデルは数百から数万の推論トークンを生成する場合があります。使用される推論トークンの正確な数は、チャット補完応答オブジェクトの使用状況オブジェクトで確認できます。”
どうやら、これまでのような、APIだから格安でトライできる、という安易な発想は、価格体系を考慮すると危険な感じがします。
DIfyのLLMノードの画面
DifyのLLMノードの画面を示します。
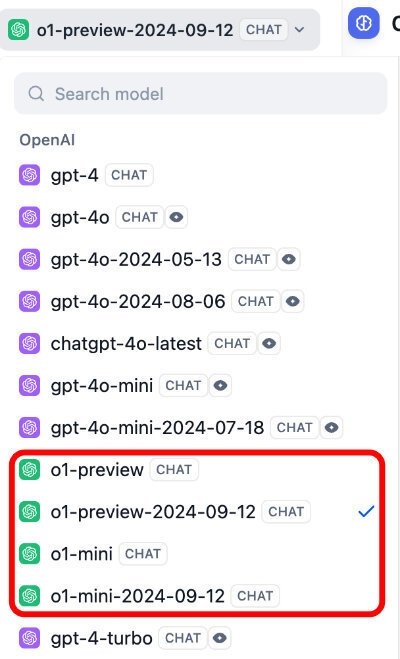
赤い枠で囲んだように、Open AIのLLMで、o1シリーズが4つ追加されています。現時点では、各々、2024-09-12が最新版のようです。
Difyでのo1シリーズのmaxトークン数
それぞれのMax Tokens を示します。
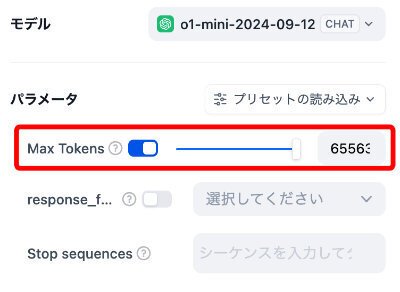

・o1-mini: 最大 65,536 トークン
・o1-preview: 最大 32,768 トークン
Difyにしては珍しく、それぞれの本来の最大トークンと同じ値となっており、このあたりにも気合が感じられます。
o1ノードのパラメータ設定
また、これまでのGPTシリーズとは異なり、設定できるパラメータは、無いといっていい状態です。ただし、バルクで下記のような設定はできます。
これは、従来と同じで、クリエイティブ、バランス、正確の3つから選べます。

とりあえず、予備知識は以上です。
せっかくの先行できるチャンスなのでトライアルは楽しみですが、高度な知的課題を持っているか、また設定できるか、問われている感じもします。
Difyの改良点等
回答ノードの複数画像の出力ができなかった問題
v0.8.1のリリースノートで、下記の説明がありました。
回答ノードの完全なデータフロー
反復中に回答ノードのストリーム出力で欠落していたコンテンツを修正し、包括的なデータフローを保証しました
この、回答ノードが "欠落していたコンテンツを修正し,,"と改良されたということは、もしかして、画像生成結果を複数表示できなかった問題も解決されたのでは?
と考え、試してみました。
下記のフローで試行しました。

バッチサイズとなっているのが、画像の数です。3にしています。
設定画面では、下記のようになっています。

ここでは、Number Images(画像の数)という表現になっています。これに3と設定しています。
プレビューの結果は、こうでした。

ちゃんと画像が3つ表示されました。
改善されていました。
今回は、以上です。