
pdfplumber, Python を使って PDF から目的のテキストを取り出す

とあるサイトを PDF に保存した。今思えば先のことを考えていなかった。
データを活用しようと思ったが、PDF のままでは無理と気づく。
そこで Python を使って文字を取り出すことにした。
ネットで調べると pypdf というライブラリーに関する記述が多かったので、まず pypdf を試してみた。
pypdf は、全然ダメだった。
使えるものはないかと探したら、pdfplumber というライブラリーがあった。
pdfplumber を試したところ、簡単に目的を達成できた。
この記事は、そんな経緯を書いたものである。
pypdf を試す
pypdf を使ってサラッとテキストを読み取っている。
簡単に見える。
スクリプト
import pypdf
data = pypdf.PdfReader('untitled.pdf')
page = data.pages[0]
text = page.extract_text()テキストの読み取り結果(pypdf)
Pycharm のデバッグウインドウで変数 text を View すると

なんだこれは?
おかしいな。まるで読めてない。
自分の環境が悪いのか。
表に書かれた文字を読み取りたいのだが、文字を正しく読めたとしても、pypdf は、表の形を理解しないように思われた。
解決を試みることなく、諦める。
他に何かないだろうか。
上の記事を読んで、pdfplumber が良さそうに思った。
pdfplumber を試す
Pycharm を使ってライブラリーをインストールする
Pycharm > Settings… >
Project:…..
Python Interpreter
+ をクリック
検索窓に pdfplumber と入れる
下に表示された pdfplumber を選択(デフォルトで選択されていた)
Install Package をクリック
(Installing) と表示されている間、待つ。
ウインドウの下に、Package 'pdfplumber' installed successfully と表示されたらOK
Close
本当にインスールされたのかいつも不安になる。
pdfplumber の使い方などは次のところにある
テスト用スクリプト
import pdfplumber
# PDFファイルを開く
with pdfplumber.open('untitled.pdf') as pdf:
# PDFの各ページを処理
page = pdf.pages[0]
text = page.extract_text()
# ページからテキストを抽出
dict_text = page.extract_text_lines()
table = page.extract_table()このスクリプトは、異なる3つのやり方を試している。
.extract_text()
.extract_text_lines()
.extract_table()
テキストの読み取り結果(pdfplumber)
text = page.extract_text()Pycharm のデバッグウインドウで変数 text を View すると

読めている
表の読み取り結果(pdfplumber)
table = page.extract_table()Pycharm のデバッグウインドウで変数 table を View すると
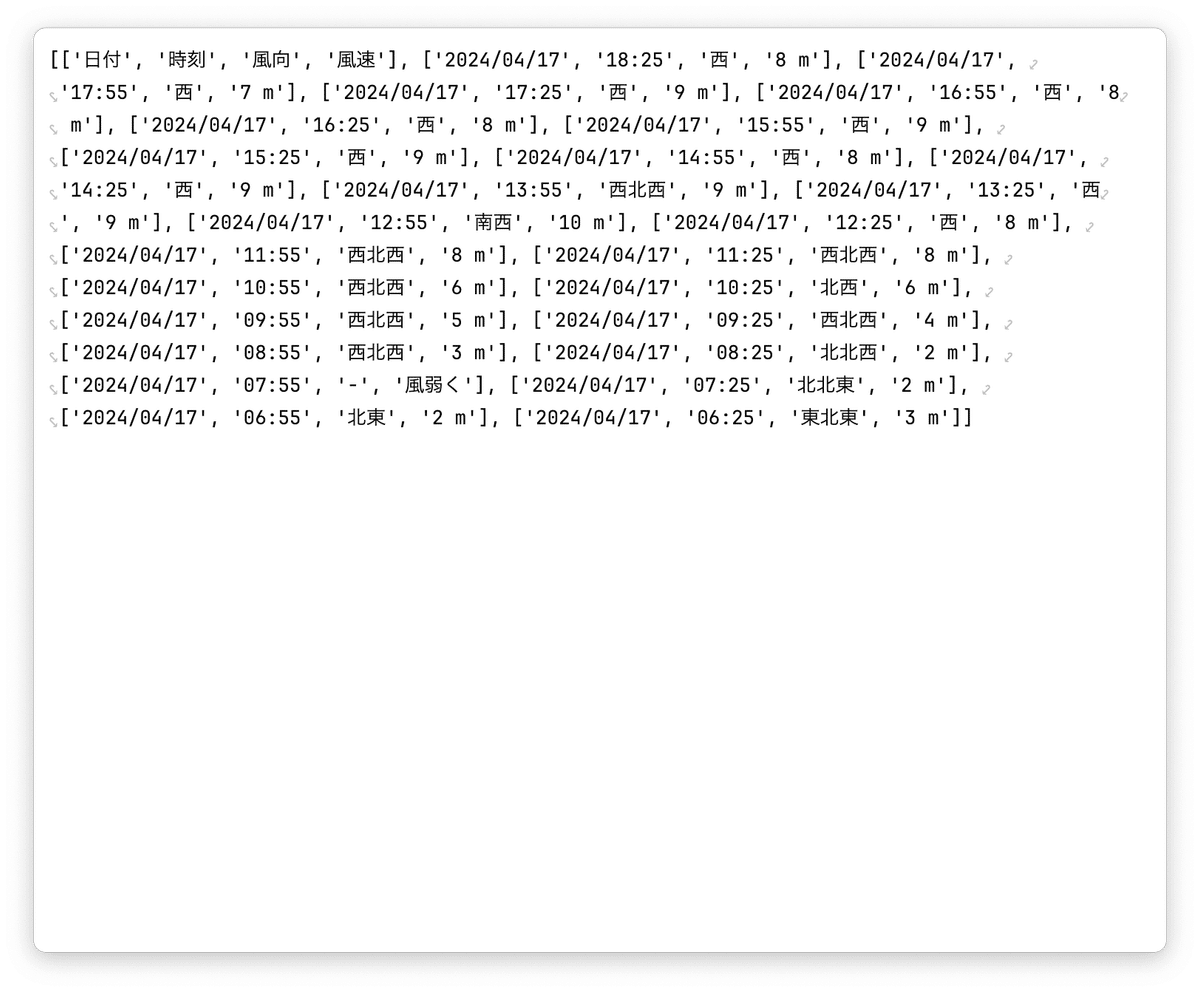
各行のリストを要素とするリストとして取得できる
最終的には、このリストを csv として保存した。
サンプルデータ
実際に読み取る対象は、とある Web ページを PDF として書き出したものだ。
とあるWebページ
これをこのまま記事にして良いか悩んだので、この記事作成用にサンプルデータを作った。
MacOS 付属のアプリケーション Pages で書類を作って PDF として書き出した(ファイル>書き出す>PDF…)
画像は、なんとなく入れてみたが、表の読み取りには関係なかった。
文字もきちんと読めた。
スクリプト
# 海上保安庁の「海の安全情報」舞坂灯台 をブラウザー Safari で表示し、PDFに書き出したものを対象とする
# https://www6.kaiho.mlit.go.jp/03kanku/shimizu/maisaka_lt/kisyou/index.html
# こんなことをするくらいなら、スクレイピングしたら良いだろうに
# とりあえず、これまでに PDF で保存したものがあるので、その風速および風向のデータを csv として保存する
import pdfplumber
from pathlib import Path
import csv
pattern = '観測時刻 ([0-9]{4})/(0[1-9]|1[0-2])/(0[1-9]|[12][0-9]|3[01]) ([01][0-9]|2[0-3]):([0-5][0-9])' # '観測時刻 2024/11/28 00:25'
if __name__ == '__main__':
#files = list(Path('./').glob('*.pdf'))
for f in Path('./').glob('*.pdf'):
# PDFファイルを開く
with pdfplumber.open(f) as pdf:
# PDFの各ページを処理
page = pdf.pages[0]
# ページからテキストを抽出
dict_text = page.extract_text_lines()
if dict_text[1]['text'] == '舞阪灯台': # '舞阪灯台'
result = page.search(pattern, regex=True)
YMDhm = result[0]['groups']
csv_path = './舞阪灯台' + YMDhm[0] + YMDhm[1]+ YMDhm[2] + YMDhm[3]+ YMDhm[4] + '.csv'
table = page.extract_table()
with open(csv_path, 'w') as f:
writer = csv.writer(f)
writer.writerows(table)files = の行は要らなかった。
スクリプトと同じフォルダーにある PDF ファイルを処理する。
for f in Path('./').glob('*.pdf'):まずテキストを抽出して、目的の PDF かどうかをチェック
「舞阪灯台」という文字があったらOK
dict_text = page.extract_text_lines()extract_text_lines は辞書のリストを返すとあった
辞書のリスト、つまりいくつかの辞書の集合体である。
だからこのデータを利用するには、dict_text[1]['text'] のように、リストのインデックスを指定した上で、辞書のキーを指定する必要がある。
[1]:「舞阪灯台」という文字列を含む行のインデックス
['text']:文字を取り出すには辞書のキーとして 'text' を指定する
pdfplumber は正規表現を使って文字を取り出すことができる。
pattern = '観測時刻 ([0-9]{4})/(0[1-9]|1[0-2])/(0[1-9]|[12][0-9]|3[01]) ([01][0-9]|2[0-3]):([0-5][0-9])' # '観測時刻 2024/11/28 00:25'「観測時刻 2024/11/28 00:25」といったパターンをみつける。
丸括弧で囲んだ箇所は、[0]、[1] のようにインデックスを指定することで取り出せる。
result = page.search(pattern, regex=True)結果は、辞書のリストである。
インデックスとキーを指定して、年月日時分の文字列を取り出す。
YMDhm = result[0]['groups']
.search() の結果も、辞書のリストである。
キーとして 'groups' を指定すると、例えば次のようなデータを得ることができる。
result[0]['groups'] = ('2024', '12', '12', '16', '25')
ここでは search の結果が一つしかないので、[0] 固定としている。
正規表現の pattern を定義したときに丸括弧で括ったところがあるが、そこのデータをタプルとして得ることができるということ。
これを利用して「2024/11/28 00:25」からスラッシュやコロン、スペースを取り除く
'./舞阪灯台' + YMDhm[0] + YMDhm[1]+ YMDhm[2] + YMDhm[3]+ YMDhm[4] + '.csv'
表を取り出すのは簡単だ。
table = page.extract_table()この場合、表が1つしかなかったので、このまま csv に書き出したら、できてしまった。
with open(csv_path, 'w') as f:
writer = csv.writer(f)
writer.writerows(table)Python で csv ファイルを書き出す説明を探すと、.writerow() しか説明していないのが多いように感じたが、その場合、複数ある行を1行ずつ書き出すことになる。
.writerows とすれば、2次元の配列を一気に csv に書き出せて楽だと思うのだが。
覚書のつもりでこの記事を書いている。
ゲットしたデータがどういうものであるかとか、なぜそのように処理したのかなど、もう忘れている。大事なところはデバッガーを起動して確認して記事を書いた。
これまで、Python の PDF 用のモジュールとして、PyMuPDF を使ってきたが、それは今、pypdf として存在しているとかなんとか聞こえてくる。しかし、pypdf は使えなかった。pdfplumber を試したらすんなり PDF に書かれた表を csv ファイルに書き出すことができた。
t.koba