
Llama 2研究(2) : モデルカードを解析する

今回はLlama 2のモデルカードを見ていきたいと思います(以下のリンクから確認することができます)。
モデルカードとは何か?
モデルカードとは機械学習モデルの使用目的を明確にし、適していない文脈での使用を最小限にするために記される簡潔なモデルの説明です。
Margaret Mitchellらの論文「Model Cards for Model Reporting」に基づいて始められ,、LLMを含む多くの機械学習モデルが採用しています。
Hugging Face内に日本語の説明がありますので興味がある方はご一読ください。
Llama 2のモデルカードの内容
モデルカード概略を項目ごとに読み解いていきます。
Model Details(モデル詳細)
モデルのバリエーション
事前学習モデルは3種類。それぞれ70億、130億、700億のパラメータ数
チャット用にファインチューンしたLlama-2-Chatモデルもある
ほとんどのベンチマークで他のオープンソースモデルを上回る
有用性と安全性はChatGPTやPaLMのような人気のあるクローズドソースモデルと同等
モデルのアーキテクチャ
Llama 2は、最適化されたトランスフォーマー構造を使用する自己回帰型言語モデル(auto-regressive language model)
※ 自己回帰型言語モデルはトランスフォーマーのデコーダーだけを使用したモデルです。文章生成に優れ、OpenAIのGPTシリーズなども同じ構造です。
ファインチューン版は、教師ありのファインチューンとRLFH(人間のフィードバックを用いた強化学習)を使用して、有用性と安全性についての人間の好みに合わせます。
※ こちらもChatGPTなど他のファインチューンモデルと同じプロセスです。
図表の解説

Training Dataは公開されていません。
Llamaの時には公開されていたのが今回は曖昧になっています。
コンテクストウインドウ(一度に入力できるトークン数)はすべて4000
700億パラメータモデルにはGQA(Grouped-Query Attention)が使用されている
GQAは「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」という論文に基づいたメモリの使用を抑える学習技術です。

事前学習に使われたトークン数はすべて2兆個
GPT-3の学習に使われたトークン数は約5000億、パラメータ数は1450億です。
モデルの精度はパラメータ数など特定の指標だけでははかれません。モデルのサイズ(パラメータ数)、学習データ量、計算量のバランスが必要です。
通称チンチラ・ペーパーと呼ばれる「Training Compute-Optimal Large Language Models」に一定の計算予算の中でパラメータ数と学習データ数のバランスをとる手法が記されています。
学習率(Learning Rate)は70億と130億が3.0 x 10^-4、700億は1.5 x 10^-4
学習率は勾配降下法で最適なコスト関数をとるための値です。大きすぎると収束せず、小さすぎるとものすごく時間がかかったり、仮の最適値に収束してしまったりします。
その他
トレーニング期間は2023年1月から7月まで。
オフラインのデータセットによって訓練された静的モデル。コミュニティのフィードバックによりモデルの安全性を向上させてから次のバージョンを出す。
Intended Use(使用目的)
想定しているユースケース:Llama 2は、英語における商用および研究用途を目的としています。チューニング済みモデルはアシスタントのようなチャット用途を想定しており、一方で事前学習済みモデルは様々な自然言語生成タスクに適応可能です。
範囲外のユースケース:適用可能な法律や規制(貿易遵守法を含む)に違反する方法での使用。英語以外の言語での使用。Llama 2の許容使用ポリシーおよびライセンス契約で禁止されている他の方法での使用。
※ 英語以外の言語での使用は想定していません。日本語をちゃんと使えるようにするには工夫が必要です。

Hardware and Software(ハードウェアとソフトウェア)
トレーニング要素:私たちは、カスタム訓練ライブラリ、MetaのResearch Super Cluster、および事前学習のためのプロダクション・クラスターを使用しました。また、ファインチューニング、アノテーション(注釈付け)、評価も第三者のクラウドコンピューティングで行われました。
※ Metaは自前のAI用スーパーコンピューター、Research Super Clusterを所有していますが必要に応じてサードパーティのクラウドを使用したようです。
カーボンフットプリント:事前学習には、タイプA100-80GB(TDP 350-400W)のハードウェア上で合計330万GPU時間の計算が使用されました。推定された総排出量は539 tCO2eqであり、その100%がMetaの持続可能性プログラムによって相殺されました。

事前学習中のCO2排出量と時間:各モデルの訓練に必要な合計GPU時間、消費電力の表です。使用されるGPUに対する各GPUデバイスのピーク電力容量を、電力使用効率で調整します。排出量の100%はMetaの持続可能性プログラムによって直接相殺されます。モデルを公開しているため、事前学習のコストを皆様が負担する必要はありません。
Training Data(トレーニングデータ)
概要:Llama 2は、公開されている情報源からの2兆トークンのデータで事前学習されました。ファインチューニングデータには、公開されているインストラクトデータセットと、100万以上の新たに人間が注釈をつけた例が含まれています。事前学習やファインチューンのデータセットには、Metaユーザーデータは含まれていません。
データの新鮮度:事前学習データのカットオフは2022年9月ですが、一部のチューニングデータはより新しく、2023年7月までのものもあります。
※ GPT‐3、GPT-4mChatGPTは2021年9月までのデータです。
Evaluation Results(評価結果)
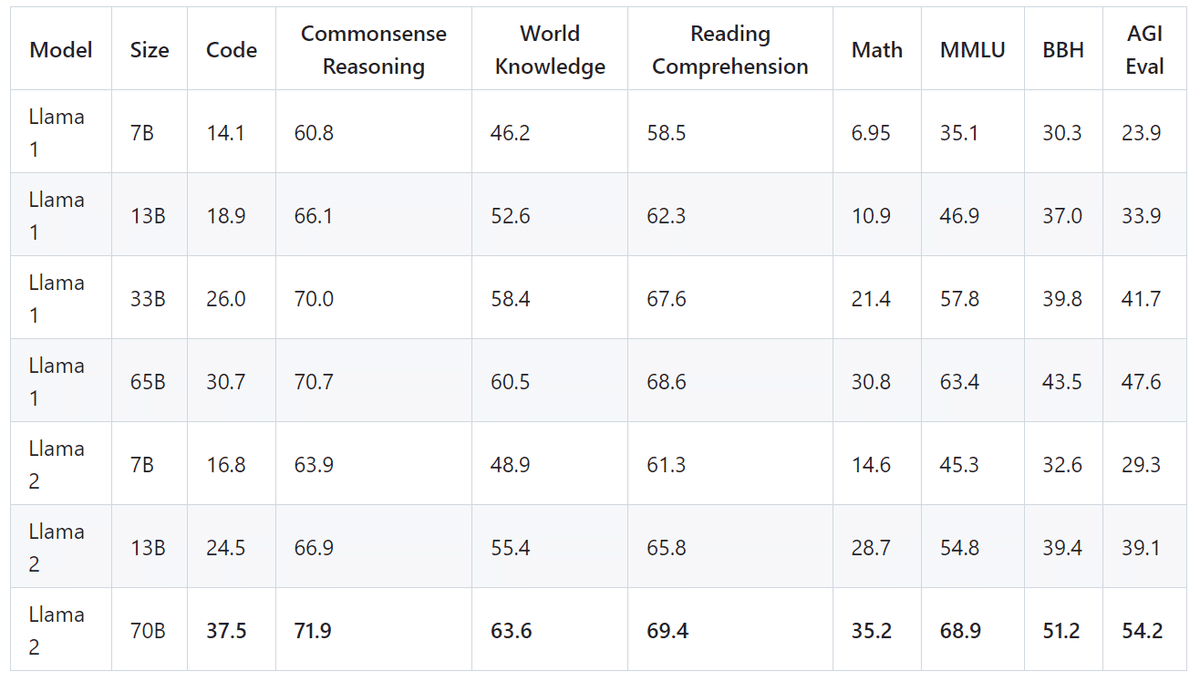
グループ化されたアカデミックベンチマークにおける全体的なパフォーマンス
コード:私たちは、HumanEvalとMBPPにおける私たちのモデルの平均pass@1スコアを報告します。
常識推論:私たちは、PIQA、SIQA、HellaSwag、WinoGrande、ARC easyおよびchallenge、OpenBookQA、CommonsenseQAの平均を報告します。CommonSenseQAについては7ショットの結果を、その他の全てのベンチマークについては0ショットの結果を報告します。
世界知識:私たちはNaturalQuestionsとTriviaQAでの5ショットのパフォーマンスを評価し、その平均を報告します。
読解理解:読解理解については、SQuAD、QuAC、およびBoolQでの0ショットの平均を報告します。
MATH:私たちは、GSM8K(8ショット)とMATH(4ショット)のベンチマークの平均をトップ1で報告します。
※ それぞれのカテゴリー内の多様なベンチマークをグループ化して表現しています。
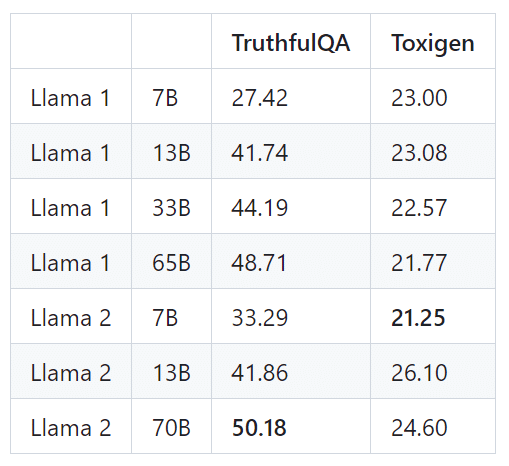
自動安全性ベンチマークでの事前学習済みLLMの評価。TruthfulQAについては、真実かつ情報的な生成物の割合を提示します(数値が高いほど良い)。ToxiGenについては、有害な生成物の割合を提示します(数値が小さいほど良い)。

異なる安全性データセットでファインチューンされたLLMの評価。上記と同じメトリクス定義が適用されます。
※ チャットモデルはほぼ有害性がないという結果です。
Ethical Considerations and Limitations(倫理的考慮事項と制限)
Llama 2は新技術であり、使用にはリスクが伴います。これまでに行われたテストは英語で行われ、全てのシナリオをカバーしているわけではありませんし、全てをカバーすることはできません。これらの理由から、すべてのLLMと同様に、Llama 2の潜在的な出力は事前に予測することができず、モデルはユーザープロンプトへの反応として、場合によっては不正確な、偏った、または他の問題を抱えた反応を生成する可能性があります。したがって、Llama 2の任意のアプリケーションをデプロイする前に、開発者はそのモデルの特定のアプリケーションに合わせた安全性のテストとチューニングを実施するべきです。
責任ある使用ガイドは、以下のURLでご覧いただけます:https://ai.meta.com/llama/responsible-use-guide/
まとめ
完全に無料なオープンソースのLLMの中では最高精度のモデルです。一方で英語以外のユースケースは想定されていないので、日本語での評価や使用には気を付けるべきでしょう(OpenAIのGPTが多国語対応を喧伝していたのとはアプローチが違います)。
またチャット用にファインチューニングを施したモデルは安全性をかなり重視していますね。
最後の項目にあったようにベンチマークはすべてのユースケースをカバーしているわけではないので、他のLLMと同様に実際に使ってみてどんなものかを確認する必要があります。
次回は論文を読んでいくか、実装についてまとめるか検討中です。