
【遊戯王】機械学習でカードの勝利貢献度を評価しよう【全文無料】

背景
皆さんこんにちは、趣味でマスターデュエルを嗜んでいるUNPOKOCHINPOと申します。
突然ですが、皆さんはランク戦やレート戦で遊んでいて、なかなか勝てないなぁ、なんて思ったことはありませんか?
ありますよね。
では、そんな時、どうしますか?
デッキ構築を見直しますよね。
ということで、今回はデッキ構築のお話をしていこうと思います。
デッキ構築の問題
デッキ構築を行う際に、多くの人が直面しているであろう問題を著者の独断で挙げてみようと思います。
それは、
採用してみた札がどのくらい役に立ってるのか、よくわからん
ということです。
例えば、「幽鬼うさぎが今アツい!!」と思って採用してみたものの、「コイツ活躍してるような気もするけど、足引っ張ってるような気もするな…」みたいな気持ちになった経験、皆さんもあるのではないでしょうか。
こんな感じで、多くの人が、デッキの中の各カードがどの程度活躍しているのかを正確に評価することに苦労しているのではないかと思います。
強いプレイヤーであれば、「現在の環境でどのカードを採用すべきか」ということや、「何回か対戦をやってみたけど、このカードのせいで勝率が下がっていそうだな」ということを自分で正確に判断できるのかもしれません。
しかし、私を含む多くの凡夫プレイヤーにとっては、マネのできない芸当です。
つまり、デッキ構築の問題の本質というのは、プレイヤーの強さに依存する点だと私は考えます。
もう少し厳密に言い換えると、「各カードを、客観的な指標に基づいて、かつプレイヤーのスキルも踏まえたうえで評価できないこと」がデッキ構築の問題の根底にあると考えています。
以上を踏まえたうえで、本記事で行うことをまとめます。
本記事で行うこと
本記事では、遊戯王の対戦における新しいデッキ構築理論(厳密には、デッキ調整理論)を紹介していきます。
具体的には、マスターデュエルのランク戦やレート戦から得られた情報を入力として学習した機械学習モデルをベースに、自分のデッキに採用している各カードを定量的に評価する手法を提案していきます。
既存の理論と課題
本筋に入る前に、既存の理論について簡単にレビューします。
よく見る理論は以下の二つだと思います。
特定のカード(主に増殖するG)の効果が通っている条件下での勝率
特定のカード(主にデッキの初動札)を引く確率
これらの理論については、特定のカードが対戦に与える影響を評価したり、デッキの安定性を評価するのに一定の効果を発揮すると考えられます。
しかし、これら既存の理論は、基本的に「カード同士の相互作用を考慮できず、その結果、柔軟にカードの強さを評価できない」という課題があります。
どういうことなのか、みていきましょう。
【特定のカード(主に増殖するG)の効果が通っている条件下での勝率】
まず、増殖するGが通った場合の勝率理論を、他のカードに転移できるか考えてみましょう。
サイコウィールダーというモンスターについて考えます。
このモンスターは、フィールドに★3モンスターが存在する場合に手札から特殊召喚できる★3チューナーモンスターで、☆3エクシーズを作ったり、★6シンクロを作るのに役立ちます。
このサイコウィールダーを特殊召喚した対戦で、60%の勝率が出たとして、60%という数値に、増殖するGのケースと同等の説得力があるでしょうか。
私はないと思います。
もちろん、サイコウィールダーが、60%の勝率の一部を担っているのは間違いないと思いますが、60%という値自体を、サイコウィールダーの手柄とするのは、あまりにも過大評価です。
つまり、この勝率理論を適用可能なのは、単体でパワーが高い、増殖するGのようなカードに限られるのです。
自分のデッキ内の他のカードとの組み合わせで真価を発揮するカードを、この理論で正しく評価するのは困難というわけです。
【特定のカード(主にデッキの初動札)を引く確率】
「一枚初動X枚で引ける確率〇%」、という表現をたまに見かけます。
この表現自体は、デッキの安定性を評価する一つの指標として有用であることは間違いありません。
ただ、手札誘発が大量に飛び交う環境と、そうでない環境にこの理論を晒した場合、どうなるでしょうか。
いずれの環境でも、この評価指標は不変です。
なぜならば、自分のデッキから特定のカードを引く確率を計算しているだけで、実際の対戦で当たる相手のデッキを想定しない理論だからです。
現実を見るのであれば、自分の初動札のカードパワーが、相手の手札誘発によってそがれてしまうという事実を反映させたいところですが、
この理論では、この現実を反映させることができません。
ということで、既存の理論にいちゃもんを付けてみました。
新しい理論を前面に押し出すときには、既存の理論にいちゃもんを付けざるを得ないので、大目に見てください。
まとめると、遊戯王というカードゲームにおいては、カード同士が相互作用しているという事実があり、この事実に既存の理論は対応していないということになります。
この課題を解決するために本記事では機械学習に基づく汎用のデッキ構築理論を提案していきます。
提案手法
それでは本筋に入っていきます。
できるようになること
まずは、提案手法でできるようになることを述べます。
それは、
デッキに採用している各カードの勝敗への貢献度を、機械学習モデルの予測に基づいて定量化すること
です。
もっと噛み砕いて言うと、「デッキ内の特定のカードについて、どのくらい勝利や敗北に貢献しているかを数値で見ること」ができるようになります。
これができるようになると、採用したままにしておくべきカードや、入れ替えるべきカードを、客観的に判断できるようになります。
また、機械学習の予測に基づいて勝敗への貢献度を判定しているので、既存手法の課題「カード同士の相互作用を反映できていない」も解消されます。
これはどういうことかというと、今回作成する機械学習モデルは、過去の対戦データを学習させたものになっています。
例えば、「強い展開札を引いて勝利した場合」と「強い展開札を引いていたけれど、相手が強い誘発を引いていたので勝てなかった場合」という状況を機械学習モデルが覚えてくれる、ということになるわけです。
結果として、カード同士の相互作用が対戦の結果に影響しているという事実を取り込んだ状態で、カードの強さを判断できるようになっています。
これにより、既存手法では対応できなかった課題を解決することができます。
提案手法の概要
ここから具体的な方法論を説明しますが、まずは概要をまとめます。提案手法では、以下のような流れで、デッキ内の各カードについて勝敗への貢献度を評価します。
対戦データを取得する
勝敗予測モデルを作成する
「explanation technique」で各カードの勝敗への貢献度を定量化する
では順にみていきましょう。
1.対戦データを取得する
一回の対戦で取得するデータは以下です。
先攻・後攻
自分の初手(先攻ならば5枚・後攻ならば6枚)
2ターン目までに相手が使用した誘発・捲り札・誘発ケア + 先攻制圧されたら妨害数(1妨害とか2妨害とか)
相手のデッキタイプ(ティアラメンツ、天盃龍などのデッキラベル)
勝敗
これらをランク戦、レート戦で取得します。
妨害数は、3妨害以上だったりサレンダした場合は、雑に「大量妨害」としてカテゴライズしています。
評価方法が固まっていない場合のデータを使用しているので、そこらへんはご愛嬌ということで。
データセットの概要を表1にまとめました。学習する特徴量は、すべてカテゴリカルな(数値ではない)データです。

2.勝敗予測モデルを作成する
1.で取得したデータを用いて勝敗予測を行うための機械学習モデルを学習します。
機械学習モデルを知らない方もいると思うので説明すると、
持っているデータで数式のパラメータ(係数)を調整して、未知のデータに対しても、今までのデータの傾向を反映させたなにかしらを出力させるものです。
一応、Wikipedia [1] のリンクを貼っておきます。
今回は、先攻・後攻の情報や、入力されたカードの情報、相手のデッキタイプを見て、勝敗を出力するものになっています。
本記事では、機械学習モデルの中でも、画像分類で高い性能を示しているCNNを用いています(別のモデルでも特段問題ありません)。
一応工夫して学習しているので詳細を説明しますが、性能はあまり高くないです。
図1に勝敗予測モデル作成の概要図を示しています。
青色の四角形が自分の初手のカード、橙色の四角形が相手が2ターン目までに使用した手札誘発や捲り札、誘発ケア札になっています。

【モデルの学習】
この節は、図1の上半分に当たります。
図を見るとわかるように、一つのデータを並べ替えてデータを水増ししています。
これはデータ拡張と呼ばれる手法で、画像分類器などの学習にしばしば用いられます [2] 。
データ拡張には一般に以下の利点があるとされています。
モデルの汎化性能(未知のデータに対応できる能力)が向上する
データ不足を解消できる
画像のデータ拡張が一番わかりやすいですが、元の画像を回転・平行移動させたデータをモデルの学習に使用することで、予測時に回転・平行移動された未知のデータの予測精度が向上します。
また、少ないデータを増やせるという点も利点です。
このデータ拡張を本手法でも取り入れてみました。
今回の勝率予測は、初手で引いたカード名を見て分類を行いますが、本来データの順番はどうでもよいはずです。
初手で、card1,card2,card3,card4,card5の順に引いていようが、card3,card1,card5,card4,card2の順に引いていようが、同じことです。
そのため今回は、初手で引いたカードを並べ替え、増やした状態でモデルの学習を行います。
具体的には、一つのデータから、初手のカードをランダムに並べ替えたデータを20個作って学習しています。
※後攻1ターン目で引いた札に関しては、エフェクトヴェーラーのような手札誘発を引いた場合を想像するとわかるように、初手5枚と性質が違うので、並べ替えを行いません。
【予測結果の取得】
この節は、図1の下半分に該当します。
データ拡張をしたうえで、モデルの予測の多数決に基づいて勝敗を予測しています。
例えば、未知のデータ一つに対して、そのデータをランダムに並べ替えたデータ20個作成して予測を行い「14回勝ち / 6回負け」と予測された場合には、最終的な予測は多数決で勝ちになります。
【評価指標】
モデルの性能を評価する指標を紹介します。
Accuracy:未知のデータに対する機械学習モデルの予測が、正解である割合
機械学習モデルの評価指標としては一番メジャーな評価指標だと思います。要するにモデルがどれだけ正確に予測を行っているかを表す指標です。
Precision, Recall, F値といった他の指標もあり、一応とったので詳しく知りたい人は参考にしてください。
【評価結果】
今回のモデルは、未知のデータに対して最大で82.93%のAccuracyを出すことができました(複数回モデルを学習してみて、最もよかった分類器が82.93%を達成しました)。
ここで、一般にAccuracy 82.93%はそこまで高くないことに留意してください。
特に、勝ち・負けの分類は、ランダムに結果を出力する簡素な分類器でも50%のAccuracyになるので、そこに32.93%上乗せされたイメージです。
遊戯王の対戦では、プレイヤーによって大きく異なる「プレイング」が絡んでくるので、モデルにとって予想外の場合が多々あるため、正確な予測を行うのが難しいのかもしれません。
とはいえ、モデルを一旦信頼しないことには話が進みませんから、この最大のAccuracyを出したモデルを信頼することにして、この記事の最終段階へと進みましょう。
※ Precision 80.95%, Recall 80.95%, F値 80.95%
【2024/12/07 追記】
Confusion Matrixをとる際の評価を、Accuracy取得の評価と分けていたため、Accuracyと↓のConfusion Matrixが若干整合しません。
∵ 評価時に乱数による並べ替えを行っているため。
この記事の最後で示しているコードは修正済みなので、そちらでお試しください。

3.「explanation technique」で各カードの勝敗への貢献度を定量化する
【explanation technique】
なにそれって方が多いと思うので、遊戯王に絡めて話す前に、この用語を説明します。
まず、複雑な構造を持つ高性能な機械学習モデルが登場した際に、予測根拠がよくわからないということが問題としてありました。
機械学習モデルにおいて、よくわからないけどうまく分類できているという現象は、実はあまり良いことではありません。
例えば、病気を判断する機械学習システムがあったときに、「根拠はようわからんけど、あなたはこういう病気です」とか、「根拠はようわからんけど、あなたはこの病気ではありません」と判断するのはかなりリスキーです。
また、そういったセンシティブなシステムでなくても、機械学習システムの予測根拠を解釈できる方が、モデルの予測に納得しやすい人は多いわけです。
こういった需要にこたえるべく、機械学習モデルの予測根拠を、人間が解釈可能な形で提供してあげよう、というのが「explanation technique」です。
図2を見てください。これは、Local Interpretable Model-agnostic Explanations (LIME) [3] という、有名なexplanation techniqueの論文で示されている図です。

犬の顔をした人がギターを弾いています。
この画像に対して、例えば一番右の(d)は「ラブラドールという犬のラベル」の予測根拠を示している画像になっています。
もう少し正確に言うと、explanation techniqueがラブラドールの根拠になっているっぽいと判断した画像の欠片をつなぎ合わせているのが、(d)です(画像の欠片に数値で重要度をつけて、ラブラドールっぽい上位何個かをつないで出しているイメージです)。
若干欠けたり、下の方に余計なピクセルが含まれていますが、機械学習モデルがしっかりと「犬の部分」を見て、ラブラドールというラベルを出力していると判断できるので、この機械学習モデルはいい感じの判断をしているのだと、人間が分かるようになります。
このような形で、人間が解釈可能な形でモデルの予測根拠を提供してくれるのが、explanation techniqueということです。
本来は、モデルの予測根拠を解釈可能な形で提供することで、モデルの信頼性を評価するものですが、今回はひっくり返して使います。
つまり、モデルを信頼することにして、explanation techniqueの「予測根拠を客観的に示せる部分」を活用するということです。
※どのようにして複雑なモデルの予測を解釈しているかというと、特徴空間における入力データの周辺を、局所的に解釈しやすい簡単なモデルで近似しています。詳しくは論文を見てください。
【遊戯王への応用】
ついにexplanation techniqueを用いて、各カードが勝敗にどれだけ貢献しているのかを可視化していきます。
勝敗への貢献度の可視化は以下の手順で行われます。
「相手が使用する誘発・捲り札・誘発ケア札」+「相手のデッキタイプ」を予め定めておく
「自分のデッキから5枚のカードをランダムに引く」という操作を1000回行う
LIMEで、2で引いた各カードがどれだけ勝利に貢献しているかを定量化し、各カードについて勝利への貢献度の中央値を取得する
まずは、1で相手がどんな誘発や捲り札を使用してくるかを、予め決めます。
例えば、相手が必ず無限泡影を使ってくるという想定で、各カードがどれだけ勝利に貢献するかを見ていきます。
相手が何も打ってこないという想定なら、指定しないことも可能です。
また、相手デッキタイプについても、天盃龍やティアラメンツといった特定の仮想敵を指定してもいいですし、指定しなくてもよいです。
次に、2でランダムにデッキから1000回初手ドローを繰り返します。この操作により、40枚デッキであれば平均で各カードが125回引かれます。
最後に、各カードについてLIMEによる勝利貢献度の計算を行います。
この勝利貢献度は、当然、125回それぞれで変わってきます。
例えば、分かりやすい例で言うと
スプライトブルー・レッド・墓穴・墓穴・抹殺
スプライトブルー・泡影・墓穴・墓穴・抹殺
という5枚のカードを引く試行が、スプライトブルーを引いた125回の試行の中にあった場合、前者のスプライトブルーの勝利への貢献度は、後者のスプライトブルーの勝利への貢献度よりも大きくなるはずです。
なぜならば、前者は、レッドが手札にあるため、ブルーの効果を最大限に発揮できる手札になっているからです。
このように、たくさんのランダムな試行を行えば、勝利への貢献度のより正確な分布を得ることができます。
そして、この分布から今回は、中央値を取得して表示します。

【実際のデッキに理論を適用】
今回評価に使用しているデッキは、以下のゴールドプライドゴブリンライダー(GPGR)デッキです。
GPGRデッキの各カードについて、勝利貢献度を見ていきましょう。先攻での貢献度の評価になります。
・相手が誘発を使用しない場合の各カードの勝利貢献度

この図は、相手がこちらの展開に関与してこない場合の勝利貢献度を表す図になっています。
赤色が濃いほど、勝利に大きく貢献していることを意味しています。SRベイゴマックスが最も勝利に貢献していることが確認できます。
青色が濃いほど、敗北に大きく貢献していることを意味しています。百鬼羅刹爆音クラッタが最も敗北に貢献していることが確認できます。
ただし、初手に来た時の勝利貢献度なので、かならずしも青色のカードを抜けばいいというわけではないということに注意してください。
サーチすることで真価を発揮するカードがありますが、今回はそこまでは評価できません。
・相手が増殖するGを使用する場合の各カードの勝利貢献度

この場合は、あまり誘発なしの場合と変わりません。
墓穴・抹殺のスコアが上がることを期待していたのですが、増殖するGを打たれて止めることができても、他の誘発や捲り札で負けた試合が結構あったので、それがモデルの判断に影響しているのかなと考察しています。
(天盃龍環境なので、一枚の誘発を止めても捲られたことが多く、増殖するGを打たれようが打たれまいが、墓穴・抹殺のベースのスコア自体が低下しているものと考えられます。)
相手が灰流うららを使用する場合の各カードの勝利貢献度

こちらではなぜか、灰流うららのスコアが急上昇しています。学習データが少なめで、それをデータ拡張しているので、偶然がモデルに反映されやすいです。
一方で、P.U.N.Kのフォクシーチューンのスコアが、わずかにマシになっています。
召喚権を消費せずにうららを釣れる部分が評価されており、ここは妥当かなと思います。
相手が無限泡影を使用する場合の各カードの勝利貢献度

魔界発現世行デスガイドのスコアが、初めて負に転落しました。デスガイドに泡影を打たれると、貫通札がなければどうにもならないので、これは納得できる評価結果です。
また、自分では気づきにくかったのですが、デスガイドのスコアが図4~7のいずれにおいてもあまり高いスコアを出していないことから、
手札誘発が飛び交う今の環境(2024年11月)では、抜いたほうが良いのかもしれないという一つの選択肢を考えるきっかけになりました。
このような形で、自分ではかなり強いと思っているカードが、実は勝利に貢献していないということに気付けるのが提案手法の強みです。
特に、相手のデッキに入っている誘発がモデルの判断に影響してくるので、そういった部分込みで、客観的に構築を判断できるようになります。
おまけ:個別の手札を評価
せっかくなので、各カードスコアの中央値を見るだけでなく、個別の手札についても評価をしてみましょう。
次の二つの手札について、セアミンの勝利貢献度を可視化してみます。
※ 相手はうららを使用
(セアミン,ベイゴマックス,無限泡影x3)
(セアミン,GPキャプテンキャリー,無限泡影x3)
1では、セアミンのスコアは、0.1922,
2では、セアミンのスコアは、0.0927
となります。
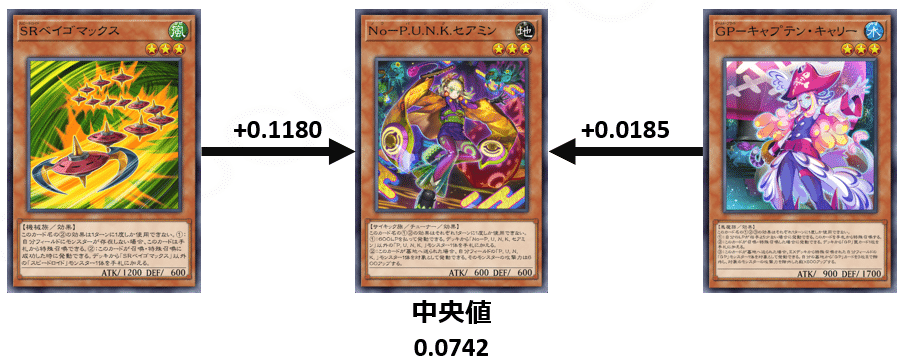
同じカードであっても、異なる手札の中に混ざっていると大きく評価結果が変わっていることが確認できます。
図6のセアミンのスコアの中央値が0.0742だったので、
ベイゴマックス・キャプテンキャリーがセアミンのパワーを増大させていると解釈できるでしょう。
特に、ベイゴマックスを組み合わせで引いていると、セアミンが大活躍できそうです。
このように特定のカード同士の相性も評価できるようになります。
提案手法の限界
各カードについて勝利貢献度を可視化する手法を紹介し、実際に特定のデッキに対して適用した結果を示しました。
一見便利そうな提案手法ですが、いくつかの限界があります。
ユーザが自分のデッキを使用して、十分なデータを取得しなければならない
「偶然」がモデルの判定に影響しうる(特に対戦数が少ない場合)
展開に関与する事故札の性能を正確に評価できない
まず、十分なデータを取得しなければモデルの性能が高くなりません。これは機械学習というデータに依存するモデルに関連する問題であり、解決することが難しいです。
次に、「偶然」がモデルの判定に影響することについてですが、これは図5を見れば明らかだと思います。相手がうららを使用する条件下で、自分がうららを握っていたとしても、そこにはあまり関連がないと考察するのが普通です。
なぜならば、うららはうららに直接影響する効果を有していないからです。
自分も相手もうららを握っていた試合で、相手の他の手札との兼ね合いで、偶然勝ちやすかったのだと思いますが、この結果が顕著にモデルに反映されてしまっています。
このように、偶然現れた傾向をもモデルが学習してしまうのがデメリットです。
たくさんデータを取れればこの傾向は薄まるはずなので、一つ目の限界と絡み合うことで問題になります。
最後に、展開に関与する事故札の性能を正確に評価できないという限界もあります。
ベイゴマックスとタケトンボーグの勝利への貢献度合いを見てください。
ベイゴマックスが常に上位に入っているにもかかわらず、タケトンボーグは常に下位になっています。
ベイゴマックスの強さの一因は、タケトンボーグのはずなので、タケトンボーグがかわいそうなことになっています。
今回は、初手に来たカードを入力としている機械学習モデルなので、展開に関与する事故札が過小評価されるという問題が発生するというわけです。
まとめ
【提案手法の限界】でネガティブな問題点を示しましたが、機械学習モデルを使用して、柔軟にカードの強さを評価できる利点はやはり大きいと思います。
今回は、既存手法のカード同士の相互作用を反映できていないという課題を解決することに注力し、未完全ではあるもののデッキ評価の方法を一歩進められたのではないかと感じています。
この基礎理論を皮切りに、より高度な新しいデッキの評価方法が生まれてくれたらうれしいなと思っています。
Pythonを使える方のみになってしまいますが、
コードを公開中:UNPOKOCHINPO/ML-for-Yugioh
(素人コードなので、ご承知おき下さい)。
マスターデュエルだけをするYoutubeチャンネルをやっているので、よければ遊びに来てね。
稀に、この記事みたいな理論を投稿するよ。基本はマスターデュエルをして遊ぶだけ。
また、この記事を気に入ってくれて、かつお金に余裕がある方は、お茶代およびマスターデュエル課金代をください。僕が幸せになります。続きはないです。
カード画像の著作権:
©スタジオ・ダイス/集英社・テレビ東京・KONAMI
©スタジオ・ダイス/集英社・テレビ東京・KONAMI ©Konami Digital Entertainment
サムネイル画像:
かわいいフリー素材集 いらすとや
ここから先は
¥ 200
この記事が気に入ったらチップで応援してみませんか?