
[プログラム・コード公開] コピペだけで実用的かつ実践的なLabel Spreading(LS)とサポートベクターマシン(Support Vector Machine, SVM)とを組み合わせた半教師あり学習[多クラス分類にも対応) (Python言語)

[New] 実業家として有名な堀江貴文さん(ホリエモン)のメルマガ[Vol.359]における副業紹介において、このプログラム・コード販売が、なんと 1番 に紹介され評価していただきました!
こんにちは!大学教員ブロガーのねこしです。http://univprof.com/
仕事や研究において、より精度・性能の高いクラス分類モデルを構築するため、教師ありデータだけでなく教師なしデータも活用して、半教師あり学習によりクラス分類をする方もいらっしゃいます。Label Spreading(LS)とサポートベクターマシン(Support Vector Machine, SVM)とを組み合わせた半教師あり学習についてはこちらに書きました。
http://univprof.com/archives/17-02-28-12926352.html
しかし、LS+SVMによる半教師あり学習はわかっても、実際にLS+SVMができるようになるわけではありません。ネットや本でプログラミングを説明しているものはありますが、データの読み込み方とか結果の出し方とか、他にも調べてやらなくちゃいけないこと、多いんですよね・・・。手間と時間がかかります。
そこで、すぐにLS+SVMができるプログラムを作りました。一般的なSVMは2クラス分類ですが、今回は多クラス分類にも対応しています。データセットを準備すれば、Python言語で実行ができます。
LSで類似度を計算するときにガウシアンのガンマの値を決める必要がありますが、ちゃんとクロスバリデーションで最適化しています。下の記事の手順をしっかりと実行するプログラムです。
http://univprof.com/archives/17-02-25-12818365.html
データ形式・必要なソフトウェア
以下の記事に示す形式のデータさえ準備すれば、Python言語でLS+SVMを実行することが可能です。data.csvが教師ありデータ、data_prediction1.csvとdata_prediction2.csvとが教師なしデータ、という位置づけです。
Python言語のために必要なソフトウェアは以下の記事をご覧ください。
実行結果
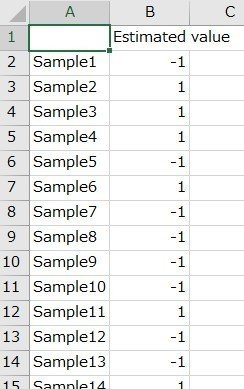
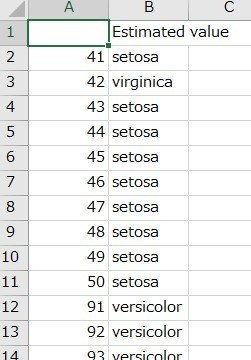
実行結果を下に示します。最後に以下のcsvファイルが同じディレクトリ(フォルダ)に保存されます。
■PredictedY2.csv・・・data_prediction2.csvの目的変数の予測値


このプログラムからスタートしてさらにプログラミングを進めたいと考えている方にもぜひ利用していただければと思います。
プログラム公開
ここまでお読みいただきありがとうございます。
Python言語のプログラムは有料コンテンツとします。ただこれにより、こちらに記載したLS+SVMをすぐに実行できます。
http://univprof.com/archives/17-02-28-12926352.html
こちらからプログラムのzipファイル自体はダウンロードできます。
http://univprofblog.html.xdomain.jp/code/lssvm_analysis_all_e_python_pass.zip
購入していただくと解凍のためのパスワードがありますのでそちらをご利用ください。
またこちらのzipファイルに必要なスクリプトと関数があります。パスワードはかけていません。購入後に使い方の説明があります。
http://univprofblog.html.xdomain.jp/code/supportingfunctions.zip
すべて動作保証ずみですのでご安心ください。上のデータ形式に合わせていただければ、どんなデータにも使えるプログラムです。このプログラム一つでいろいろなデータを解析することができ、余裕で元が取れます。ご不明点などありましたら遠慮なくこちらに連絡をください。
http://ask.fm/univprofblog1
迅速に対応します!
ここから先は
¥ 1,980
この記事が気に入ったらチップで応援してみませんか?