
Python初心者でもなんとかWhisperで日本語音声書き起こしをする

1.イントロダクション
音声データからテキストを書き起こしたいときってありますよね。
会議の議事録を作るのが大変
原稿作成や思考整理の一環として話した内容をテキスト化してストックしておきたい。
2については「思考を整理する方法」を模索して辿り着いた先を読んで私もやってみたいと思いました。一人で思考しているよりも、ラバーダック・デバッグのように誰かに話す前提で整理すると不思議と思考が整理される、なんて一度は経験したことがあるんじゃないでしょうか。
このような場合に便利なのが、OpenAIが公開しているwhisperです。
この記事で案内する方法では次の条件を満たしつつ音声の文字起こしが可能です。登録やログイン不要
無料
インターネットへの音声アップロード不要(ローカルPCで動作)
90~99%程度の精度で音声をテキストに変換
whisperを使うことで、高精度で音声データからテキストデータを作成することができます。うまく活用すれば手間のかかる議事録作成から解放され、ドストエフスキーが口述筆記で『罪と罰』を執筆したように、口述で大量の原稿を執筆することが可能になります。
whisperとは
chatGPTで知られるOpenAIが公開している、音声データをテキストに変換できるモデル
オープンソースであり、無料でダウンロードしてローカルのPCでも動作させることができる
モデルによるが90~99%の精度で書き起こしが可能
この記事の対象者
whisperによる書き起こしはしてみたいけどpythonやライブラリについて改めて学習する気は起きない人
インターネットを通して音声データを処理するのは怖いので、ローカルのPCで動作させたい人
whisperについてはすでにたくさんの記事があります。しかし、pythonやvenvを触ったことがない私は記事に書かれていないところで詰まって都度ググる必要がありました。この記事ではかなりくどい説明になっていますが、同じような境遇の方の参考になればと私がwhisperを動かすまでのステップを説明しています。
音声書き起こしだけサクッと利用したい方を対象とするので、細かい情報は扱いません。例えばVS codeを常用する方なら日本語化してもよいと思いますが、この記事ではインストール時デフォルトの英語のまま利用することを前提として解説します。
インターネットを通して音声データを処理することに抵抗がない方は、ググればgoogle colabのような無料のクラウドサービスを使って実行する方法があるので、そちらを参考にしたほうがよいです。
ローカルPCで動作させる場合、自分のPCのディスクを食います。速度がPCのスペックに左右されるのでよほど高性能なPCを使っていない限りクラウド上で実行したほうが早いです。さらに上位のモデルになるとかなりPCのリソースを食うので、書き起こし中他の作業を行えなくなるかもしれません。
2.whisperを使う準備
venv上に仮想環境を構築し、VS codeのターミナルから操作していきます。
筆者の環境
Windows 11 Home
13th Gen Intel(R) Core(TM) i7-13700F 2.10 GHz
(1)VS codeをインストール
次のページなどからダウンロード・インストールしてください。
(2)Python3.10.0のインストール
Pythonをダウンロードしてインストールします。
注意点が2つあります。
必ず3.10.0をダウンロードすること
他のバージョンでもOKかもしれませんが、後述するライブラリの依存関係がめんどくさいので、変なところで詰まりたくない人は3.10.0にするのが無難です。
pythonのpathを通す
インストーラを起動したときに"Add Python 3.10 to PATH"のチェックボックスが一番下に表示されるのでチェックしておけば問題ありません。デフォルトではチェックされていないので注意!
ここでチェックを忘れた場合でも、後述するffmpegのpathを通すときに一緒にpathを通せばリカバリ可能ですが、めんどくさいのでやっておきましょう。
(3)ffmpegをインストールしてpathを通す
次の記事などを参考にffmpegをダウンロードしてインストールします。
pathを通すのも忘れずに。
コマンドプロンプトを起動して"ffmpeg"と打ち込んでバージョン情報が表示されるかの確認までちゃんとやっておきましょう。
私はこのステップを忘れていて、後段でかなり詰まりました……
https://economylife.net/windows-ffmpeg-path/#google_vignette
(4)仮想環境構築用のフォルダを作成する
適当なフォルダを作成します。
ここでは例としてDドライブ上に「venvTest」フォルダを作成しました。
このフォルダパスは次の過程で必要となるので控えておきましょう。
(5)VS codeのコマンドラインを使う準備をする
(1)でインストールしたVS codeを起動します。
下準備として、スクリプトを実行するためのユーザー設定を行います。
①画面左上「View」→「Command Palette」をクリック

②出てきた検索窓にuser settingと入力して、候補として表示された"Open User Settings(JSON)をクリック

③設定用のJSONに次をコピペする
"terminal.integrated.env.windows": {
"PSExecutionPolicyPreference": "RemoteSigned"
}他にユーザ設定がない人は次のような見た目になるはず。

(6)VS Codeのターミナルを起動する
画面左上の"Terminal"をクリックします。すると画面下部にターミナルが表示されます。ターミナルに表示される文字列は人によって異なるのでこの見た目通りになっていなくて大丈夫です。


(7)Pythonのバージョンを確認する。
ターミナルに"python -V"と打ち込んでPythonのバージョンを確認します。
Vは大文字なので注意!(小文字で打ち込むとpythonとだけ表示されてバージョンが表示されませんでした。私はここでしばらく詰まりました……)
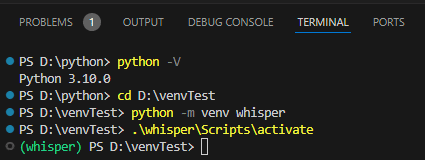
(8)先ほど作ったフォルダ(過程(4))のフォルダに移動する
ターミナルに"cd フォルダのパス"を打ち込んで、Enterを押しフォルダを移動します。
私の場合は"D:\venvTest"のフォルダなので"cd D:\venvTest"と打ち込みます。

(9)環境を作成する
"python -m venv whisper"とターミナルに打ち込みEnterを押してしばらく待ちます。
成功すると先ほどのフォルダの下に「whisper」フォルダが作成されます。エクスプローラーなどでちゃんと作成できているか確認してから次のステップに進みましょう。

(10)仮想環境を起動する
".\whisper\Scripts\activate"と打ち込んでEnterを押してちょっと待ちます。
成功すると、ターミナルの一番左に"(whisper)"と表示されます。
(11)ライブラリの状況を確認する
"pip list"と打ち込んでライブラリのインストール状況を確認します。
特に何もインストールしていないので下の画像のような表示になるはずです。

(12)念のためpipをアップグレードしておく
WARNING: You are using pip version x.x.x; however, version 24.0 is available.
とか警告が出るので"python.exe -m pip install --upgrade pip"と打ち込んでアップグレードしておきましょう。効果があるのかわかりませんが、我々は素人です。警告には従っておきましょう。
※upgradeの前のハイフンは2つなので注意しましょう。ハイフン一つでも一見成功した風のダイアログが流れるのでちゃんとメッセージは読みましょう。
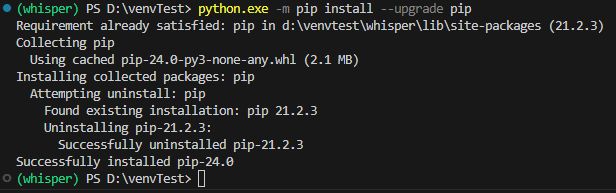
不安な場合はもう一度"pip list"でバージョンが上がっていることを確認しましょう。
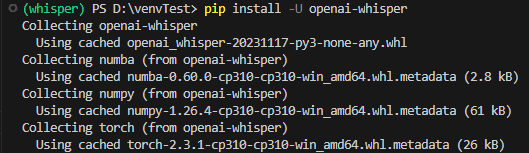
(13)whisperをインストールする
ようやくwhisperインストールまでたどり着きました。
whisperのページを見ると必要なことが書いてあります。
Setupの項目を見ると"pip install -U openai-whisper"というコマンドを打ち込めばよいと書いてあります。素直にターミナルに打ち込みます。
するとなにやら文字列がいっぱい流れるのでしばらく待ちます。
(この記事でいままで書いてきた「待つ」より長い時間待つことになります。多少時間がかかっても不安にならないで大丈夫です。)

(14)そのほか必要なライブラリのインストール
先ほどのwhisperのGithubのページを見ると、他にもライブラリのインストールが必要なようです。厳密にはRustは必要ないというか、そもそもここまでのインストールで詰まっている人向けな気がしますが、あとで詰まるのは嫌なので念のためインストールしておきます。
①"pip install setuptools-rust"でrustをインストール
②"pip install ffmpeg-python"でffmpeg-pythonをインストール
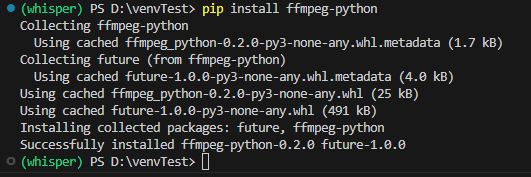
(15)pip listで最終確認
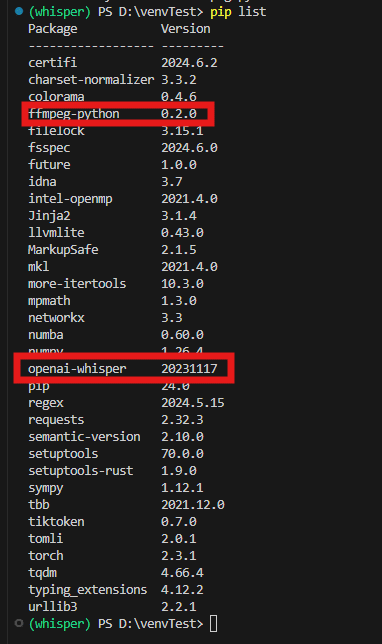
念には念を入れてちゃんとインストールされているか確認しておきましょう。
"pip list"と打ち込んでopenai-whisperとffmpeg-pythonのほか、torchなど必要なライブラリがインストールされていることを確認してください。
(16)いよいよwhisper起動!
書き起こしたい音声ファイルを準備してパスを控えておきます。
自身の環境に合わせてターミナルに打ち込みます。
whisper --model medium --language Japanese "音声ファイルのパス"modelの後ろには使いたいモデルを選択してください。モデルの詳細な情報はwhisperのGithubを参考にしてください。tyny→base→small→medium→largeの順で精度が上がっていきますが、処理時間も伸びていきます。
音声ファイルのパスには、音声ファイルが配置してあるフォルダのパスを指定します。
今回はサンプルとして北区ニュースの音声ファイルをmediumモデルで書き起こそうと思います。次のコマンドをターミナルに打ち込みます。
whisper --model medium --language Japanese "C:\Users\xxx\Downloads\xxx.mp3"※パスのところはあくまでサンプルなので自身の環境に合わせて入力してください。


model baseでは5分以下くらいで終わりましたが、model mediumでは精度が上がるものの10分くらいかかった気がします。
"warnings.warn("FP16 is not supported on CPU; using FP32 instead")"と警告が出ているとおり、今回紹介した方法はCPUを使ってやる方法です。GPUを使えば更に速度向上が見込めるかもしれません。またfaster-whisperのようなより高速なモデルも出ています。

最後に
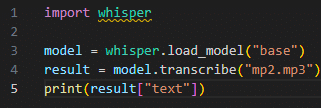
本当はPythonのプログラムから実行したかったのですが、色々な階層にプログラムファイルを配置しても次のとおりimportのところでwhisperが認識されずうまくいきませんでした。そのため上記のとおりコマンドラインから実施する方法をとりました。詳しい方は解消方法を教えていただけるととても助かります🙇
3.トラブルシューティング
個人的に詰まった個所をあげていきます。
手順通りやっていれば大丈夫かと思いますが、手順を飛ばしたり作業を中断後再開したりして順番が前後すると失敗するケースがあります。迷ったら再起動すればなんとかなるかも。
".\whisper\Scripts\activate"実行時に「このシステムではスクリプトの実行が無効になっているため ~ 読み込むことができませんと言われた」
ユーザー設定ができていないと思われます。「(5)VS codeのコマンドラインを使う準備をする」を参考にユーザー設定を行ってください。
「FileNotFoundError:指定されたファイルが見つかりません。」と表示される。
ffmpegがインストールされていないと思われます。「(3)ffmpegをインストールしてpathを通す」「(14)そのほか必要なライブラリのインストール」を参考にインストールしてください。
また、私がはまったパターンとして、仮想環境を起動してからffmpegが必要なことに気付いて後からインストールしたときに、手順通りやってもエラーメッセージが表示されるケースがありました。そのときは一度PCを再起動してください。再起動後は「(8)先ほど作ったフォルダ(過程(4))のフォルダに移動する」を行ったあと、「(9)環境を作成する」は飛ばして「(10)仮想環境を起動する」から実施すれば再開できると思います。
※念のためですが、再起動前にインストールしていたライブラリをインストールするステップは飛ばして大丈夫です。
4.参考記事
https://qiita.com/ussoewwin/items/37a464cd0baebb195275
https://economylife.net/windows-ffmpeg-path/#google_vignette