
S級CEX ML Botterへの道

UKIです。
本記事は仮想通貨botter Advent Calendar 2024の20日目の記事となります。
はじめに
皆さん、Bot作ってますか?
現在ではDEXにおける多様なBotの台頭により、上下予測のCEX Botは御株を奪われてしまいました。筆者も2020年頃にDEX Bot開発を試みましたが、元々ハードウェア出身の筆者にとってその敷居は非常に高く、見事に挫折してしまいました。現在は有用な記事がたくさん公開されているため、当時とはまた状況が違っているかもしれません。
そんなこんなで前回バブルをCEX Botで乗り切った筆者ですが、2022年初頭頃にはバブルの収束とボラティリティの低下に伴ってBot収益は大きく落ち込んでいました。いろいろと思いを巡らせた結果、筆者がBotterとして生き残る術は、予測力を向上するしかないと考えたのです。ここで筆者はある決断をします。日本株で運用システムにMLを適用する手法で成功体験を得ていた筆者ですが、以下の記事の通りそれまでのドメイン知識ベースのモデリング手法を捨て、大きく方針転換することに決めたのでした。
筆者はこれまでの経験と勘所に頼ったファイナンスMLのスタイルを捨てることに決めたのです。(中略)今まさに筆者はMLボット(ファイナンスML)で消耗している真っ最中なのでした。
さて、あれから2年半以上、月日は流れました。
筆者のML Botは完成しています。
最近は物騒ですし、筆者は顔出し本名出しもしているため、オープンな場で具体的な損益に触れることは今後もないと思います。ただ一言、パフォーマンスには満足しているとこの場では述べておきます。
この記事は何?
Richman本により参入した後発組のML Botterの殆どは、もう離脱してしまったのかもしれません。その一方で、未だに大きな利益を得ているML Botterが存在することも事実です。本記事は、このような情勢の中でも「ML Botterを目指してみたい!」という方向けに筆者の経験をまとめたものです。
DEX BotかCEX Botか
まず、DEX BotとCEX Bot、それぞれの違いや利点を説明しておきます。※ここでいうCEX Botはアビトラではなくレンジ長めの上下予測Botの意です
DEX Botは様々な手法により、ごくわずかなDDと初期コストで利益を出すことができます。ここでいう様々な手法とは、時によってハックまがいな物もあるでしょう。一方で、場合によってはチェーン毎ラグられるといった事態も起こりうるかもしれません。DEX Botで利益を上げるためには、他のチェーン参加者よりも技術力で優れていることが何よりも重要です。また、新興プロダクトをいち早くキャッチアップする情報収集能力も求められます。
DEX Botについては最近は数多くの有用な記事が公開されています。興味のある方は、直近3年分の仮想通貨botter Advent Calendarを一通り読むことをお勧めします。
次にCEX Botですが、DEX BotとCEX Botでは根本的に対戦相手が異なります。DEX Botは対戦相手はモニタの向こうに存在する「特定の人」であり、Winner Takes Allの性質を備えています。このアドレスのTxが凄い等のポストを見掛けることがありますね。一方で、CEX Botの対戦相手は「特定の人」ではなく「不特定多数」との戦いであり、加えて不確実性との戦いとなります。Perpetualをはじめ短期トレードは基本的にゼロサムゲームであり、この「不特定多数」よりも相対的に合理的な行動を取ることで利益を得ることができます(あくまで定性的な解釈です)。
バブル期には練度の低い市場参加者が増え、雑な成行注文が飛び交い、不用意な厚い板が発生するため注文の執行コストは下がります。またボラティリティが増加することで値幅が容易に確保できるようになります。
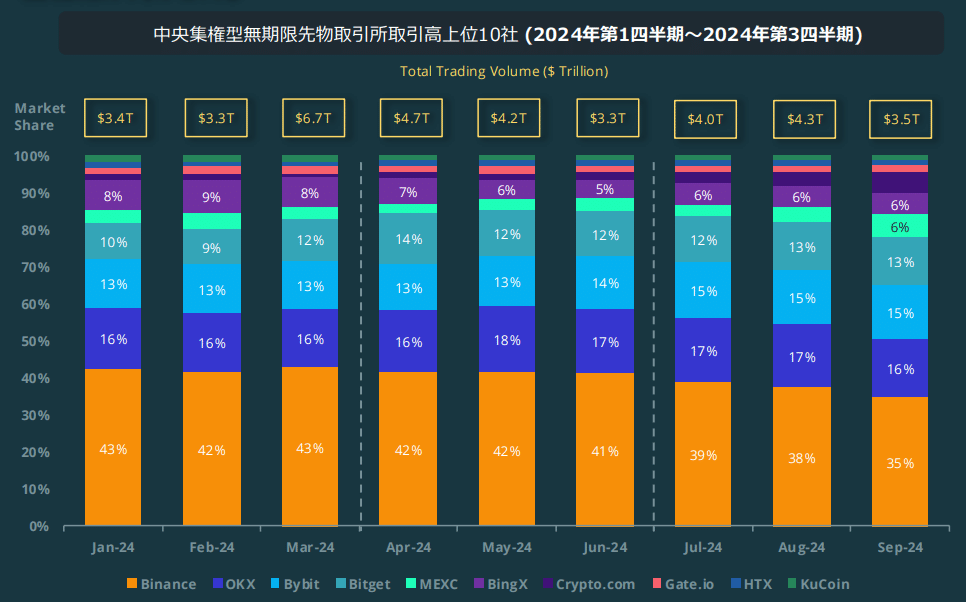
CEX Botの間口は広く、そして何より魅力的なのは運用資金のキャパがDEXよりもはるかに大きいことです。CoinGeckoレポートでは、24年9月の取引高は、DEXスポットの$98Bに対してCEX無期限先物は$3.5Tとなっており、単純に考えると30倍以上のキャパがあります。余談ですがCoinGeckoレポートは市況確認に非常に有用です。わざわざ日本語資料まで準備されているため、定期的に読むことをお勧めします。

MLが必要か?
Botの稼ぎ方(というよりCryptoの稼ぎ方、もっと広義にお金の稼ぎ方)は多種多様です。その中には、稼ぎやすい方法、稼ぎにくい方法があると言われます。注意したいのは、他人にとって稼ぎやすい方法が自分にとってもそうだとは限らないということです。このため自身の適正をよく理解し、その上で立ち回りを決めることが重要だと思います。
さて上記の話を踏まえた上で、ここでは過去データを元に取引の意思決定をするケースを考えます。このケースにおけるBotterは、取引対象となるアセットやタイムフレーム、収益源の考え方などトレード戦略の大枠を決めた後、そのコンセプトに沿ったデータを収集することになります。せっかく収集したデータですので、これらのデータを可能な限り有効活用し、余すところなく情報抽出したいと考えるのはごく自然なモチベーションでしょう。
このとき、データを有効活用するための手段がMLです。「MLなくてもいいよね」という意見もありますが、上記のケースを考えた場合、MLがあるのとないのでは間違いなくあるほうが良いです(選択肢の問題です)。簡単な指標を用いて多角的・機動的にBotを展開するスタイルも考えられますが、この場合にも結局MLを使えたほうが展開性に優れると考えています。
MLにしろAtomic Arbにしろ、技術力をベースとして収益性を高める場合、その習得コストはどうしても高くなってしまいます。自身の運用スタイルと照合して費用対効果についてしっかりと考えるとよいでしょう。

ML Botを始める前に
ML Botterとして大成するには、可処分時間をしっかりと学習・開発に費やした前提で1年半~2年は掛かるものと考えてください。現在はバブルの真っ最中ですので、今すぐこれを目指そうとするのはナンセンスです。今は手持ちの武器を使ってこの波に乗りましょう。バブルでは高尚なBotでなくとも収益を出すことはできます。
バブルで大事なのはコレ
— DEG (@DEG_2020) December 2, 2024
持ち味がこの状況で分かってない人は残念ながら次回バブルまでにトレーニングしてください pic.twitter.com/a54s5ksxO2
ML Botに取り掛かり始めるのにちょうどよい時期はバブル崩壊の後です。冬の時代に研鑽を積むことで、閑散期でも徐々にBot収益が右肩上がりになってきます。そしてそこに満を持してバブル前兆が到来した時、収益の桁が変わります。初めて花開くときが来るのです。
開発環境
ここから具体的なML Bot開発の話に入ります。まず開発環境ですが、モデルパラメータ数や学習サンプル数が比較的小さいときにはGoogle Colabをメインで使います。
2024年12月現在、Colabのランタイムはいくつかのタイプを選択できるようになっており、A100選択時にはCPUメモリが83.5G、GPUメモリが40G、L4選択時にはCPUメモリが53G、GPUメモリが22.5G、T4選択時にはCPUメモリが51G、GPUメモリが15G割り当てられます。
パラメータ数や学習サンプルが大きくなると一番最初にネックになってくるのはCPUメモリです(GPUメモリはバッチ毎にGPUに乗せるとほぼ問題になりません)。課金額低めのL4で使用できるCPUメモリ53Gではすぐに不足しはじめます。ひとまず条件出し時はサンプルを間引いてメモリ不足に対応し、本学習の際にはCPUメモリ目的で課金額高めのA100に移行し、それでも足りなくなる場合は自前で環境構築するかGoogle Cloudに移行することになります。Google CloudでGPUありでCPUメモリ128GB~であれば月額数万円レベルで建てることができます(これ以上先は沼になります)。
なお、Google Cloudで学習を行う際、大規模なデータはGoogle Cloud Storageに保管することになりますが、このときGoogle CloudのインスタンスのリージョンとStorageのリージョンが同じとなっているか注意してください。データ転送により思わぬ課金が生じることがあります。
また計算に数日掛かることが多くなってきます。Colab Proでは計算時間が24時間を超過するとランタイムが切断されてしまいます。このためFold毎に実行を区切ってランタイム再起動する、などの措置が必要になる場合があります。それ以上時間が掛かるようでしたらDeepSpeedなどの検討に移りましょう。
学習本番ではなく、特徴量作成に計算時間が掛かることもままあります。これは以降の「ライブラリ」の章にて取り上げます。
開発体制
可能であれば、信頼のおける複数人でコミュニティを作り、情報共有していくことが大事です。これは、局所解に陥らないようにするためです。ML Botによらず全てのBotに言えることですが、収益の出るフレームワークを引き当てることができるかどうかが重要です。このスイートスポットを引けるかどうかは製作者の嗅覚によるところもありますが、基本的にはBot制作の試行回数を重ねるしかありません。複数人で取り掛かることによって探索範囲を広げることができますし、他者の試行や何気ない一言から思わぬアイディアを閃くこともよくあります。
オフ会は重要な場です。ただし不特定多数が集まる場所への顔出しは、極力気を付けるようにしましょう。Botter達は現在主力となっているBotやエッジについて話すことはありませんが、彼らがしゃぶり終わったネタに関しては比較的話してくれることが多いです。彼らにとっては何気ない情報でも、こちらにとっては有用であることがよくあります。もしもそこで何かインスピレーションが得られれば自身で再検証すればよいですし、そうでなければそこにはもうエッジはないと割り切って別の道へと探索の舵を切りましょう。
MLの問題設定
上述した通り、この問題設定の段階において収益の出るフレームワークを引き当てることができるかどうかがML Bot構築の成否を分けます。勘違いされがちですが、ML Botの制作において試行錯誤すべきはモデリングではなく問題設定であり、この部分の探索範囲を広げることが重要です。また「正しい予測ができること≠収益が出ること」であることに注意が必要です。
問題設定は不確実性の高い上下予測ではなく、ボラティリティの予測などロバストな問題設定にすることもできます。ロバストな問題設定にした場合、しっかりと特徴量やモデルを作り込むことで確実に汎化性能が向上していくため、これはこれで非常にやりがいを感じるタスクとなります。一方そこで得られた結果は、リターンへ変換する過程で必ず精度劣化が発生するため、結局どのような問題設定が最適なのか明言できないのが実情です。とにかく些細なアイディアについても試行錯誤を繰り返しましょう。
ライブラリ
大規模なデータを取り扱っていくと、学習本番よりも特徴量作成に計算時間が掛かる場合があります。特徴量作成は精度を要求しているわけではないので実行が高速であればそれに越したことはありません。
いくつかのライブラリを試しましたが、筆者は大容量の特徴量を作成するときはNumpyの並列計算で行っています。マシン1台でJoblibで並列計算すると結局メモリ制約が問題になるため、手間ではありますがデータ分割し、複数インスタンスを建ててそれぞれで特徴量計算後にデータ書き出しすることが多いです(ColabだとCPUインスタンスは最大で5つまで建てることができる。ColabのCPUコア数は2しかなく並列計算はほぼできないが、50Gメモリを複数インスタンス建てれるのはメモリ制約上非常に助かる)。
Numpyは一般に高速と言われていますが、大容量データを扱うと計算速度が遅くなります。扱うデータサイズや計算内容によってそれぞれのライブラリに得手不得手があるため、人それぞれの用途に最も適したライブラリを使うべきだと思います。この辺りについて、どのライブラリが適しているかは後述する「目標にすべきML botter」達が意見をくれると思います。以下は2022年当時の検討結果です。
Numpy: データが比較的小さいときには高速であるが、大容量の行列に対する抽出、ソート、マージが遅い。場合によってはPandasより遅くなる
Pandas: 遅い。特にiterが死ぬほど遅い
CuDF: PandasのGPU版。iter系が未実装でありapplyはスカラー計算しか対応しておらず使い勝手が悪い。GPUなのでメモリ・パラ数が不足する
CuPy: NumpyのGPU版。メモリ制約が問題で結局触っていない
Polars: Pandasよりも明らかに高速。iterが速い。各row要素へのアクセスの速さはNumpyに劣るが、tensorへの変換速度は速い。
Pandasのみ使っている方は、Polarsのほうが上位互換のためこちらへの切り替えを検討すべきかと思います。Porlarsに関しては専門のAdvent Calendarまで存在しますので、そちらも参照することをお勧めします。
MLモデル
現状でLightGBMかNNの2択になります。
経験上、LightGBMは手持ちのデータではNNよりも強い結果が得られるのですが、実際に運用すると思ったほどのパフォーマンスが出ないことが多いです。感覚的な話になってしまいますが、モデルが強すぎて訓練データにfitしすぎてしまう感が否めません。当然訓練に含まれないデータでの検証を行いますが、結局ここで性能が悪いとモデルをリファインして試行を繰り返すため、恣意的なモデル選択に陥っていることも否定できません。
というわけで筆者が使っているのはNNです(実際に結果を出しているのもNN型ML Botです)。不確実性の高いファイナンスコンペでもNNは確実に1位解法に含まれていますし、GBM系に作った特徴量をそのまま突っ込むだけでもワークします。MLやっているけどLightGBMがメインという方は、是非一度NNに手を出してみるとよいと思います(以前は筆者もNNを忌避してLGBMばかりやっていました)。
一昔前はKerasかPytorch議論がありましたが、今はPytorchでよいと思います。万が一Kerasが必要になった場合は、ChatGPTに頼めばコード置換してくれます。Pytorchは学習コードや推論コードをある程度自分で書かなければなりませんが(LightGBMのようにfit、train、predictなどの関数がない)、テンプレがほぼ決まっているため入門書を買うよりもChatGPTにとりあえずのサンプルコードを生成させるのがよいと思います。1つ1つの関数についても細かく説明してくれますし、ごくわずかな時間でベースラインが出来上がると思います。
どのネットワークアーキテクチャが良いかは、扱うデータに依ります。基本は特徴量エンジニアリングをした特徴を入力としてMLPでベースラインを構築し、そこからの差分を観察しながらモデル改善していきます。ベーシックなアーキテクチャとしてCNN、LSTM、Transformer等がありますが、単純に挿げ替えただけでは良い結果は得られません。データとモデルのお気持ちを汲み取りながら地道にアーキテクチャの改善検討を続けていくと両者が嚙み合ったときにはじめて精度向上する、ということがよくあります。
モデル精度向上するためのテクニック達
この章では筆者がこれまでに検証してきたテクニック達を紹介します。
不確実性への対応
ファイナンスのデータはノイズが多く含まれています。これを低減するために最も有効な手段は、多角的な観点から予測値を出して平均を取ることです。ここでは複数のモデルを作る議論はせず、1つのモデル(アーキテクチャ)で不確実性へ対応する手法を紹介します。
分位点回帰(Quantile Regresssion)
分位点回帰は平均だけでなく、データの分布の他の部分(例えば中央値や特定のパーセンタイル)を予測する手法です。各パーセンタイルの平均を取ることで多角的な観点から(少なくともテールの存在を想定した観点から)期待値を求めることができ、精度改善します。ベイジアンNN
ニューラルネットの各重みを確率分布としてモデル化します。分位点回帰と同じ考え方になりますが、期待値を1点で予測するのではなく確率分布として予測することで、不確実性を考慮できノイズに強いモデルを構築することができます。計算コストがネックです。ランダムシードアンサンブル
アーキテクチャやパラメータ数は全く同じで、シードだけ変えたモデルを複数準備し、出力の平均を取る手法です。簡便でそれなりの効果が得られますが、アンサンブルの数が増えるにしたがって当然計算コストは増えてしまいます。MCドロップアウト
推論時にもドロップアウト層を動かして得られた結果を集計することで近似的にベイズ予測を実現する手法です。余分な計算コストが不要で費用対効果はとても高いですが、筆者は誤って推論時にドロップアウト層以外も動かしてしまったためリークして大問題になったことがあります。
不確実性への対応(ラベルの誤り)
不確実性の高いファイナンスの予測を、ラベルに誤りが混じっているとみなす考え方です。このとき、影響を最小化する手法が考案されています。
ソフトラベル(Label Smoothing)
通常は正解ラベルを1、それ以外のラベルを0とみなしますが、この手法では正解以外のラベルにも数値を割り振ります。交差エントロピー損失では、真の正解を予測してもラベルが誤っていれば誤答と同じペナルティが与えられます。もしも正解ラベル自体が間違っている可能性があるのであれば、ターゲットラベルを曖昧にすることで対応します。一般化Cross Entropy Loss、対称Cross Entropy Loss
通常のCross Entropy Lossは、誤答となるサンプルほど大きな影響を与えます。ラベルに誤りがあるサンプルでは誤答が増える可能性が高くなりノイズサンプルの影響が大きくなってしまいます。これを防ぐために正答と誤答で受ける影響を対称化した損失関数が提案されています。
データに対するアプローチ
ファイナンスのデータは言語モデルなどに比べて圧倒的にサンプル数が少ないと言われます。さらに上記までに述べた通り、ノイズが多く含まれておりその素性は悪く、効率的な扱い方も求められます。
データ拡張
データ拡張の手法にもいろいろありますが、筆者が行ったのは単純に取引対象以外のアセットも訓練データに加える、というやり方です。生成データを使ったデータ拡張には注目していますが、そこまではやれていません。転移学習、ファインチューン
転移学習は学習済みモデルを使い出力層近傍のみを再学習します。一方でファインチューニングは、学習済みモデルを使うがネットワークの全てのパラメータを更新します。ここで使う学習済みモデルは、データ拡張を使って学習したモデルを使うことが多いです。カリキュラム学習
サンプルの中には、学習が容易なサンプルと学習が難しいサンプルが混在しています。容易なサンプルから学習させる手法をカリキュラム学習、難しいサンプルから学習させる手法をアンチカリキュラム学習と呼びます。また、ファイナンスの学習で実際に寄与しているサンプルはほんの一部であり、その素性の良いサンプルのみ選別して学習する手法もあります。
損失関数、Optimizer
Sharpe Loss
リターンをターゲットとして直接Sharpe Ratioを最適化(最大化)する損失関数です。この損失関数自体にはいくつか課題があり、代替として直近のSIG-FINではCARA utility lossという損失関数が提案されていました。ADAMG(Adam with the Golden Step Size)
多様な最適化問題に自動的に適応するように設計されたパラメータフリーのOptimizerです。Optimizerはとにかく新しいものが次から次へと出てきますので、自分のMLモデルの損失曲面と相性が良いものがないか逐一チェックすべきです。
ネットワークに与える制約(帰納バイアス)
「MLモデル」の章でも触れましたが、NNのネットワークアーキテクチャはデータとモデルのお気持ちを汲み取りながら設計を進めることが大事です。ここでは簡単な説明に留めますが、パターン検出したいのであればCNN、系列データを扱うのであればRNN系が考えられます。一歩踏み込んで、マルチタイムフレームの概念を組み込む場合はブロック毎にフィルタサイズやストライドを変えてみたり、ユニバースのロングショートを考えるのであればLayerNormを使うことで数値をスコアとして扱うことができます。
当てずっぽうでアーキテクチャを設計するのではなく、しっかりと自分の考えをモデルに積み込みましょう。
目標にすべきML Botter
この章からはML Bot構築のための情報ソースとして、筆者以外のものを紹介していきます。以下、目標にすべき界隈のML Botter三銃士です。
yoshisoくん
ML Botterの親玉みたいな人。彼の月初めのS級達成ツイに恐々としているBotterが多数存在する。
今日はさすがに久しぶりのSSか
— yoshiso (@yoshiso44) November 11, 2024
morioくん
来る日も来る日も損益報告してくれる界隈のベンチマークみたいな人。彼の損益報告を見ていると、時折USDなのかJPYなのか頭がバグってしまう。
仮想通貨トレードbot損益
— morio (@morio202008) December 9, 2024
- 日付: 2024/12/09
- 日次損益: +46,764 USD
- 直近30日
- 合計損益: +215,044 USD
- 日次勝率: 0.73
- 通算
- 合計損益: +1,581,272 USD
- 日次勝率: 0.62 pic.twitter.com/TtImMyLAxn
ウーマンさん(ウーマンではない)
損益報告はされていないが屈指の理論派で、直近のSIG-FINでは研究内容を報告されていた。世界を転々としているが、幻ではなく実体のあるBotter。
> 界隈では珍しい女性Botterとして一時期は認識されていてとむいさんが騙されていた。
— richwomanbtc@就活中 (@richwomanbtc) December 1, 2024
参考となった書籍
ここでは、筆者のML Bot構築の学習過程で特に役に立った書籍を厳選して紹介します。リンクはリファなしです。
Vision Transformer入門
Transformerの原理を説明しているだけでなく、位置エンコーダ、マルチヘッドアテンション、レイヤー正規化など各構成要素を恐ろしく丁寧に掘り下げています。最後にCNN、Vit、MLP Mixerの3者は同精度が出るとしつつ、これらの特性と使いどころについて説明があります。
深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ)
網羅している範囲が広くそれぞれ文献も記載されているため、辞書として重宝しています。もしも購入するのであれば間違いなく改訂第2版を購入してください。初版から大きくページ数が増えています。
施策デザインのための機械学習入門
問題設定の本です。「正しい予測ができる≠収益が出る」ということが実感できます。取り上げられている事例は直接ファイナンスのモデリングに転用できませんが、確実にインスピレーションを得ることができます。
Kaggleに挑む深層学習プログラミングの極意
機械学習や深層学習の一般的な専門書とは異なり、実務上の実践的なテクニックが記載されています。手元に置いておきたい1冊です。
その他参考サイト
以下、参考にしているサイトや記事等を紹介します。
ML技術のキャッチアップについて
日々更新されるMLに関する情報をキャッチアップするための方法を紹介した記事です。
松尾研のDeep Learningの輪読会
かなりの頻度で更新されていますので、時折覗いて気になるものがあったら視聴してみましょう。
論文1000本ノックの人
1日1本、機械学習系の論文を要約してポストしてくれています。
#111論文等共有 1462 https://t.co/QqfJQTbYwH
— anonym(論文1000本ノックの人) (@shriver_light) December 12, 2024
[NeurIPS'24] Transformerの収束の初期値依存性を初めて理論的に定量化した論文。データを1次マルコフ連鎖で簡単化し singile-layer transformer を低ランク仮定のもと勾配流で解析。Loss は next toke… pic.twitter.com/EJnM7iawBp
おわりに
今回の記事では、CEX Botterに逆風の吹く中、「それでもML Botterを目指してみたい!」という方向けに筆者の知見を紹介しました。冒頭で「筆者のML Botは完成している」と述べましたが、まだまだ先があると思っています。これからもインプットを続けていき、自身の中で咀嚼できた内容はYoutubeで動画としてアウトプットしていく予定です。興味ある方はそちらもご視聴頂けると幸いです。
それでは、これまでにも増してML Botで消耗していきましょう。