
Figmaプラグイン開発のすすめ

ログラスでプロダクトデザイナーをしているうえだです。
先日Figmaプラグインをリリースしました。
通称「Tableの文字列を一括置換できる君」です。

今回はその経緯と概要を書こうと思います。
(この記事はログラスアドベントカレンダーの18日目です)
作成に至った経緯
作ろうと思ったきっかけは、自分がデザインファイルを作る際に楽をしたかったからです。
基本的にきっかけはいつもコレです。
(このほかにも日本語の校正プラグインやモデリングのためのウィジェットとかも作ってます。)
ログラスが提供しているクラウド経営管理システムには、Tableビューがいくつかあります。
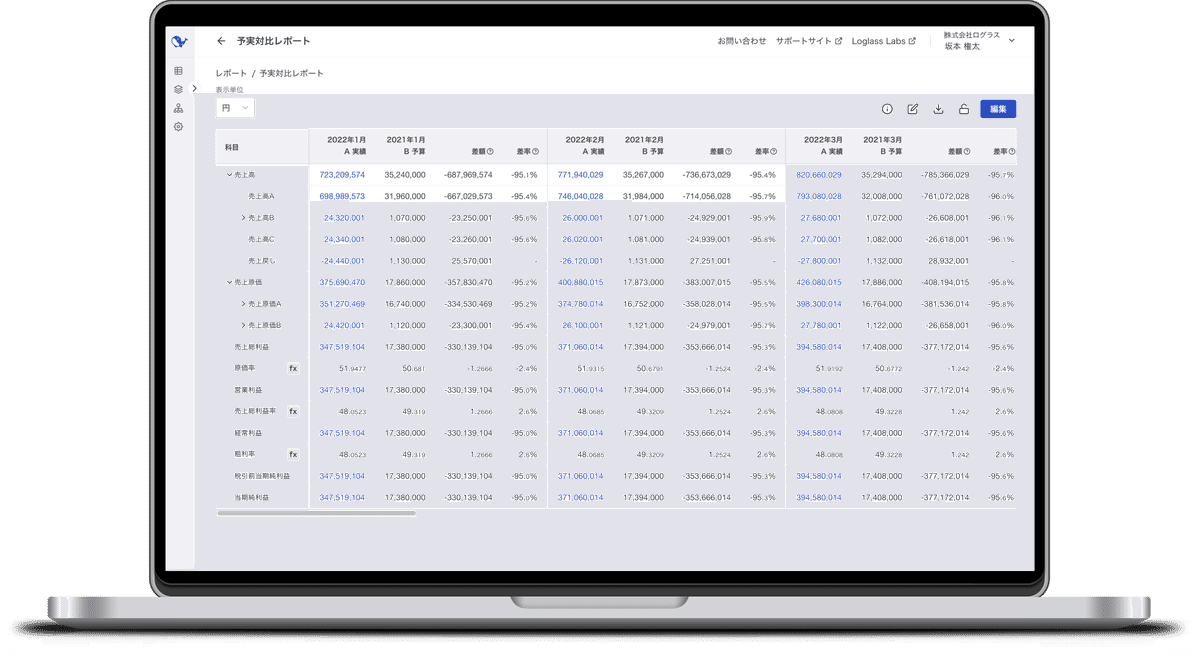
これらのUIを設計する際、実際のユーザーデータに近いものを使用しないと現実的なデザインの検討が難しいため、これまではSpreadsheet syncを活用してダミーデータを組み込みながらデザインを進めてきました。
Spreadsheet syncは最高のプラグインで、Figmaファイルのテキストレイヤーに対して、レイヤー名とspread sheetのカラム名をマッピングしてデータを置き換えてくれます。
しかし、怠惰な私はテキストレイヤーの名前を書き換えるのすらめんどくさく…またプラグイン開発当時は新規事業に携わっており、事業としてまだまだ探索的なフェーズだったため、UIを変えるたびにレイヤー名を書き換える作業をするのは現実的ではありませんでした。
そこで、「もっと楽にFigma上の文字列を置き換えられないか?(そうじゃなくちゃ仕事にならん)」と思い始めたのが事の発端です。
作成したプラグイン
こちらが実際のプラグインです。

スプレッドシートなどから対象のデータをコピペしてプラグインに貼り付けると、選択範囲の文字列を置き換えてくれます。
また、文字列に対して条件を指定して色をつけることができます。
ライブラリを使用している場合はライブラリのvariableを指定することもできます。レポートなど、特定の値で文字列の色を変えたい時に便利です。
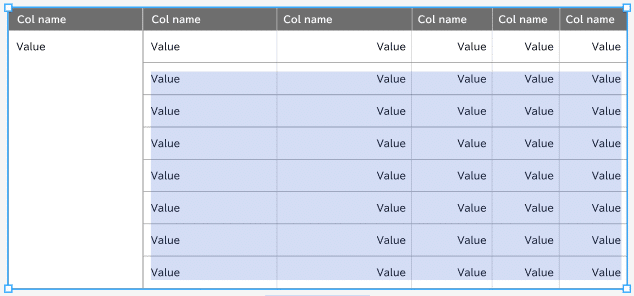
ちなみに、セルの結合には対応していないので、以下のような形式のTableでは一部の文字列を無視します。
仕組みの解説
プラグインがどういう仕組みになっているかを簡単に解説します。
仕組み1:TableデザインをTableデータの情報として取得する
Figmaプラグインではfigma.currentPage.selectionで選択中のノードの情報を取得することができます。
ノードというのはFigma上のレイヤー情報のことで、文字列はTextNodeとなっています。
その他にも、FrameNode、RectangleNode…などなどさまざまなレイヤー情報をノードとして取得することができ、そこから文字列や文字色などのプロパティにアクセスすることができます。(公式ドキュメント)

const selection = figma.currentPage.selection
console.log(selection)
// [TextNode, TextNode, TextNode, TextNode]当初は取得したTextNodeの配列をそのままTableの構造を保った情報として使えるか?と思っていましたが、そう甘くありませんでした。というのも、Figmaファイルの構造が見た目上の構造と必ずしも一致しないケースがあることがわかったためです。
前提として本プラグインは私だけでなく弊社の他のデザイナーにも使ってもらいたいと考えていたため、みんなのデザインファイルを見ながら、みんながTableのデザインをどのように作成しているかを観察していました。
そして、Tableといっても人によっていろんな作り方があることがわかりました。
・行をコンポーネントにしている / 列をコンポーネントにしている
・セルだけコンポーネントにしている(行列はFrameのまま)
・Auto layoutを使っている / 使っていない
・FrameやGroupでなんとなくグルーピングされている(これが一番辛い)
コンポーネントやAuto layoutが利用されていれば、ノードの構造からTableの構造を再現した二次元配列を生成しやすいのですが、多くの場合Tableはコンポーネント化されておらず、なんとなくレイヤーがグルーピングされているだけだったり、Auto layoutも使っておらず微妙にレイヤー同士が重なっていたり隙間が空いたりと、かなり悩ましい感じになっていました。
※ 背景として、当時弊社のFigmaのUIライブラリが汎用的なつくりになっておらず、デザインの過程でdetachされまくっていたというのがあります。
現在はUIライブラリのつくりを見直したのでコンポーネントが利用されている…はずです!
Figmaのデザインを画像として書き出してLLMで表構造を読みとるか?といったことも考えましたが、ここでも面倒くさがりな私は有料APIを使うことで課金のための機能を追加開発するのがイヤで、なんとか他の方法を探しました。
そこで思いついたのが、TextNodeの座標からそれぞれの位置関係を比較して構造化するというものです。
y座標が近いものを1つの行とみなし、また行の要素をx座標でソートすることで2次元配列に変換しています。

こうして、見た目上の構造をTableの情報として取得することができました。
仕組み2:文字列の置き換え
textareaに入力されたcsvは文字列として取得されます。これをPapa Parseというモジュールを利用して2次元配列に変換しています。

そして、このcsvから生成した2次元配列と仕組み1でTableデザインから取得した2次元配列をマッピングしていくことで文字列の書き換えを行なっています。
// Figma APIの仕様上、TextNodeのfont情報を取得してからでないと文字列の変更ができない
await figma.loadFontAsync(node.fontName as FontName);
// csvの2次元配列から置き換える文字列を取得
const valueToApply = csvValues[valueIndex.row][valueIndex.col];
// charactersにTextNodeの文字列が入っているのでこれを書き換える
targetSelection.characters = valueToApply.toString();(実際にはもっといろんな工程がありますが割愛します。)
おわりに
ここまで読んでいただきありがとうございました。
最後に、特にデザイナーの方に向けて、プラグイン開発を通じて得た気づきを共有させていただきます。
このプラグインは現在「文字列置き換え」と「文字色の条件設定」という機能を提供していますが、
当初は文字列に正負の記号をつけたり金額表記に変換したりできる「書式設定の機能」もつけようとしていました。
ですが、開発を進める中で、「そもそもこれって表計算ソフトの役割じゃないか?」という気づきがあり、最終的にスコープから外して「表計算ソフトとFigmaを併用した時に課題になっている部分の解消」に絞って機能提供することにしました。
自作アプリケーションの開発は、ユーザーとしての自分、デザイナーとしての自分、開発者としての自分、それぞれの視点を行き来しながら作り上げていくので、つい「あの機能もこの機能も欲しい!」と欲張ってしまいがちなのですが、どんなアプリケーションでも提供すべき価値を見定めてシンプルに保つことがとても重要です。
これは普段のデザイン業務にも通じる考え方で、「本質的な課題は何か?」「ユーザーが本当に必要としているものは何か?」を見極めていく過程そのものです。
Figmaのプラグイン開発は、課題の発見から、解決策の検討、実装まで、一連のプロダクト開発プロセスをコンパクトに体験できる絶好の機会になります。
そういう意味で、デザイナーの方にはとてもおすすめです!
コードはChatGPTなどを活用することもできるので、機会があればぜひチャレンジしてみてください!