How SSIS Fits into an ETL Process

Microsoft SQL Server Integration Services – SSIS – is a common solution for many organizations’ data management requirements with regard to their Business Intelligence systems. 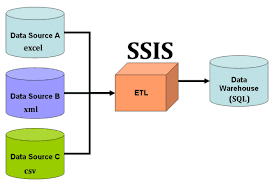
Specifically, SSIS and SQL Server together streamline Extract, Transform and Load – ETL – operations on data warehouses. The process is essential to providing efficient, accessible data flows to BI system applications.
To get in depth knowledge on microsoft business intelligence, enrich your skills on Msbi online training
Using SSIS “As-Is” to Design Your ETL Process
Guidance about utilizing SSIS/ETL capabilities typically centers on the use of SSIS control and data flows to extract and apply multiple data transformations before storing processed results within the original or an alternative database. Its greatest strength is that it runs as a one-step process without the need for intermediate storage. However, that aspect leads to certain drawbacks that are discussed later for an alternative development approach with staging tables.
Standard SSIS Extract/Transform
Data transformation employs SSIS’ large selection of data filtering operations, such as sorting, merging, unions, joins and data type conversions. Extraction is accomplished using either a flat file or OLE DB connection. Transformations are defined with graphical control and data flows that may include data multicasting to parallel processes. These process flows may have separate endpoints or may re-combine via a union operation. Learn more from Msbi online course
The Use of Staging Tables
Staging table ETL architecture provides several benefits over standard SSIS ETL development, which has deficiencies especially with regard to slowing down development and debugging.
Standard SSIS Drawbacks
Because standard development utilizes the built-in one-step process, each data flow test run extracts a batch of data from the original source, which consumes additional time. This problem is compounded if your tests are running on a production database because extra care must be taken not to corrupt its state.
An additional problem is that SSIS data flows are specified at a very low level of abstraction, which makes their development and debugging tedious in the same way that assembly code slows code production compared to using C# or Python for example.
Separating Extract and Transform
Staging separates the steps of extraction and transformation in the top-level control flow. Rather than working with the entire data source, a copy of the data is pre-fetched into a staging table with minimal transformation, if any. The only filtering necessary would be to avoid performance issues such as an overly large table.
In SSIS, an easy way to create the staging table is to edit the data source destination table properties with the option to create a new table, which results in fetching all the correct columns. Data transformations are implemented as database views in lieu of specifying SSIS transformations. These can be written as SQL queries using CREATE VIEW with SELECT statements for the fields of interest.
Tips When Using Staging
While building a staging query, it is a good practice to change field names into more human-readable form as necessary and to rename IDs as Keys to accommodate BI application usage. The multiple staging tables created in this fashion are later joined into dimension and fact tables.
Note that the use of database views for larger data sets may create performance constrictions in production, although it is much more efficient at the development stage. You can get around this by later converting the views to stored-procedure tables that break down views operations into smaller pieces that are run during the ETL transformation step.
Memory Performance Tips for Standard and Staging Approaches
Regardless of which architectural approach is used to develop your ETL process, a key aspect to bear in mind is that transformation processes should be small enough to run completely within memory. This practices avoids performance-crushing disk swaps.
1.If the SQL Service and SSIS are running on the same system, SQL Service 2.typically gains priority, which means that SSIS becomes a bottleneck
3.Apply SELECT only to the columns actually needed
4.Avoid using a Commit size of zero if inserting into a Btree to avoid memory spill
5.Use narrow data types to reduce memory allocation but avoid excessive data casts
Move sorts to the end of the transformation chain
To determine if your implementation avoids touching the disk during transformations, keep an eye on the SSIS performance counter Buffers spooled. If transformation remains in memory but performance lags, check the obvious, which is whether or not the speed of the data source system can keep up.
Especially if you employ the staging approach, since it requires more disk space, be mindful of overall resource utilization such as CPU usage, I/O bandwidth and network usage.
Conclusion
SSIS ETL is an essential pillar in supporting BI information systems. It provides powerful data transformation capabilities to match raw, large data stores to the narrower, optimized data needs of BI applications that are so essential to modern enterprise IT. The architectural approaches to SSIS ETL process development presented here offer trade-offs between performance and development/debugging effort that may improve the efficiency of your organization’s SSIS utilization. You can learn more through Msbi online training India