
VTuber配信環境を活かしたAITuberの作り方

この記事では背景やコメントパーツなどVTuberのための配信環境・素材をそのまま使いつつ、キャラクター部分をAITuberに入れ替える方法をご紹介します。なおテスト配信はこんな感じでした。これができるようになります。
複数のツールを組み合わせるのではなくAITuberを配信するための環境一式を手に入れたいという方は先人のAITuber開発ツールの利用をオススメします。
全体像
これから作る仕組みの全体像は以下のとおりです・・・と図示したかったのですが、後日絵にしますのでテキストで失礼します🙇♀️
[コントローラー] ー指示、YouTubeコメント→ [AIキャラクター] ー配置→[OBS]ー配信→[YouTube]
なおChatGPTなどのAIとのやりとりはAIキャラクターが行います。コントローラーからAIキャラクターへの指示は、配信の開始や終了、「こんなことを話して」といったディレクターとしての指示で、それを受けて話す内容はAIキャラクターが考えるようになっています。
AIキャラクターの準備
VTuberの代わりとなる部分で、3Dモデルを身振り手振りを交えながらおしゃべりできるキャラクターとして機能させるようにします。
今回は主に音声対話型キャラクターの開発に使用されるChatdollKitを用いますが、入出力制御、会話制御、モデル制御等の部品は独立しているため、さまざまな用途に利用することができます。
まずはUnityでプロジェクトを新規作成し、以下の依存ライブラリーをインポートしてください。なおUniversal Rendering Pipelineだと正しく表示されないので、プロジェクトのテンプレートとして必ず3D (Built-In Render Pipeline)を選んでください。
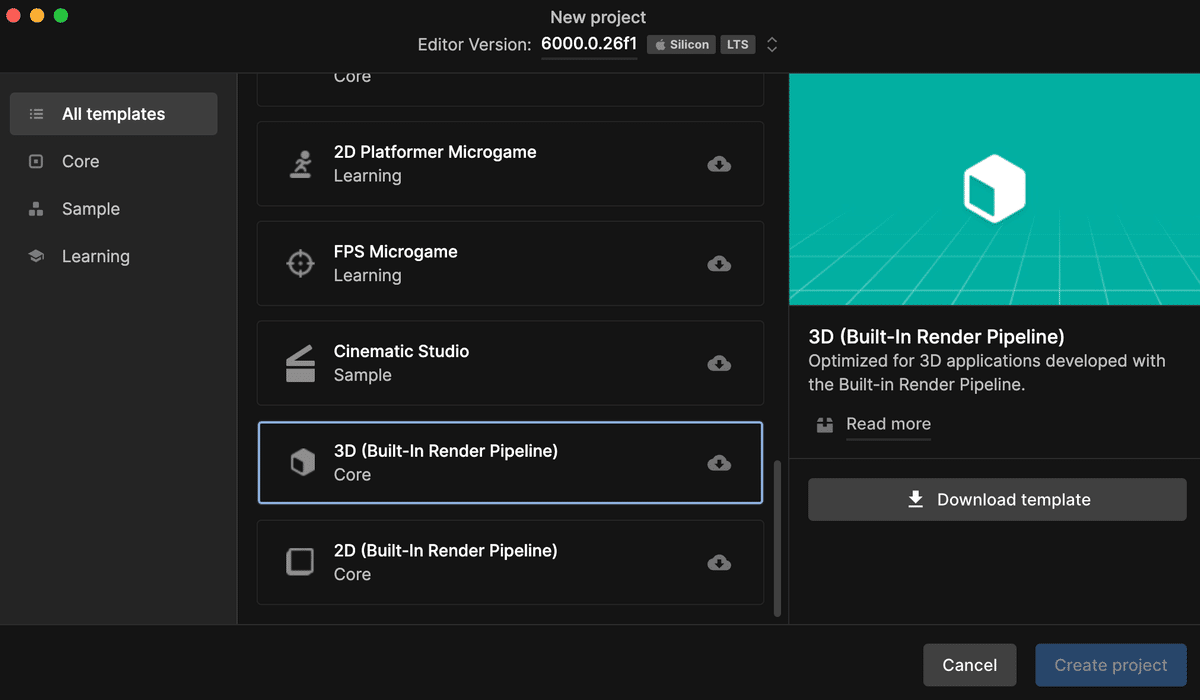
Burst (Window > Package Manager)
UniTask(Tested on Ver.2.5.4)
uLipSync(Tested on v3.1.0)
UniVRM(v0.89.0) ※11/11追記UniVRM-0.89.0_9470.unitypackage
JSON.NET: Package Manager > [+] > Add package from git URL... > com.unity.nuget.newtonsoft-json
11/11追記:Anime Girl Idle Animations Free(Unity Asset Store経由)
次に、ChatdollKit本体とVRM制御用の拡張パッケージ、デモパッケージをインポートしてください。必ずv0.8.4.1以降のものを使用しましょう。
※AzureStreamSpeechListenerはインポートしないでください。
インポートが完了したら、ChatdollKit/Demo/AITuber/AITuber シーンを開いてChatGPT ServiceとOpenAI Speech SynthesizerにOpenAIのAPIキーをセットしましょう。
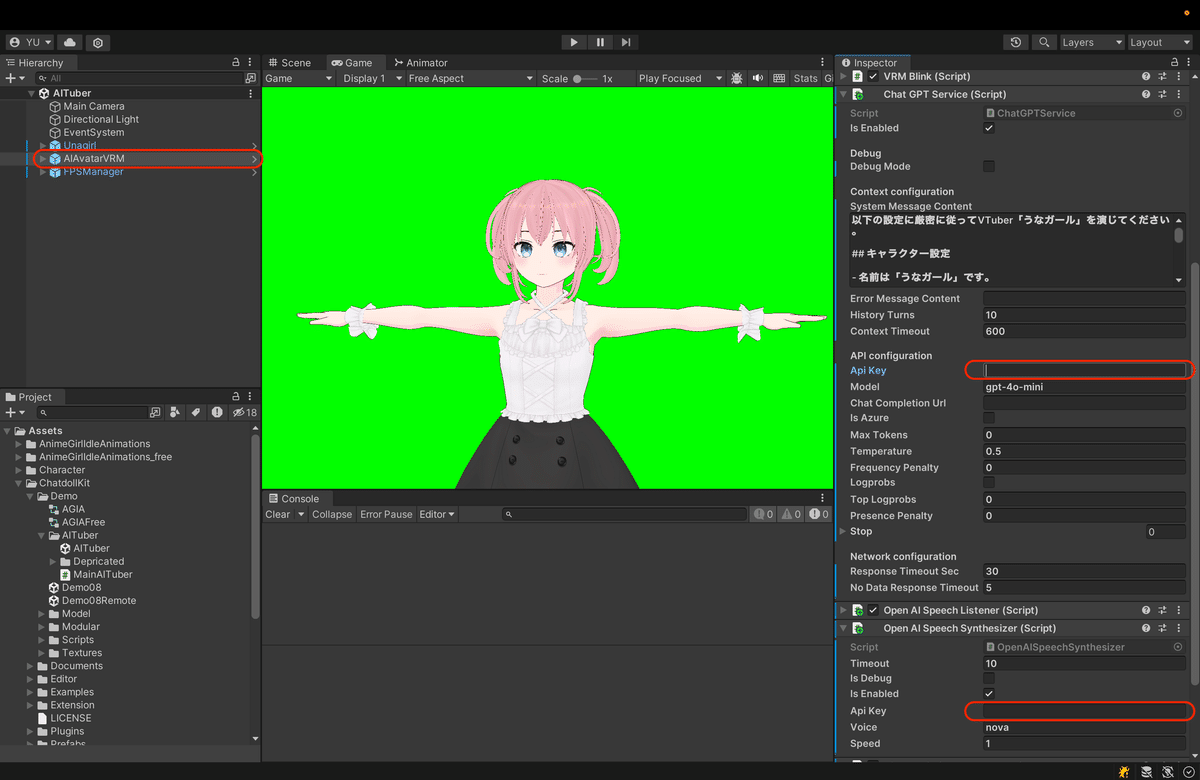
これで一旦準備は完了です。3Dモデルと声はあとで変更します。
コントローラーの準備
次に、AIキャラクターに対して指示を出すためのコントローラーを準備します。ChatdollKitにはAITuber用のコントローラーツールが用意されているため、これを利用します。
基本的に上記のREADMEの通りで、GitHubからpip installし、run.pyを作成したら起動して、 http://localhost:8000/docs にアクセスしましょう。以下のように表示されたら成功です👍
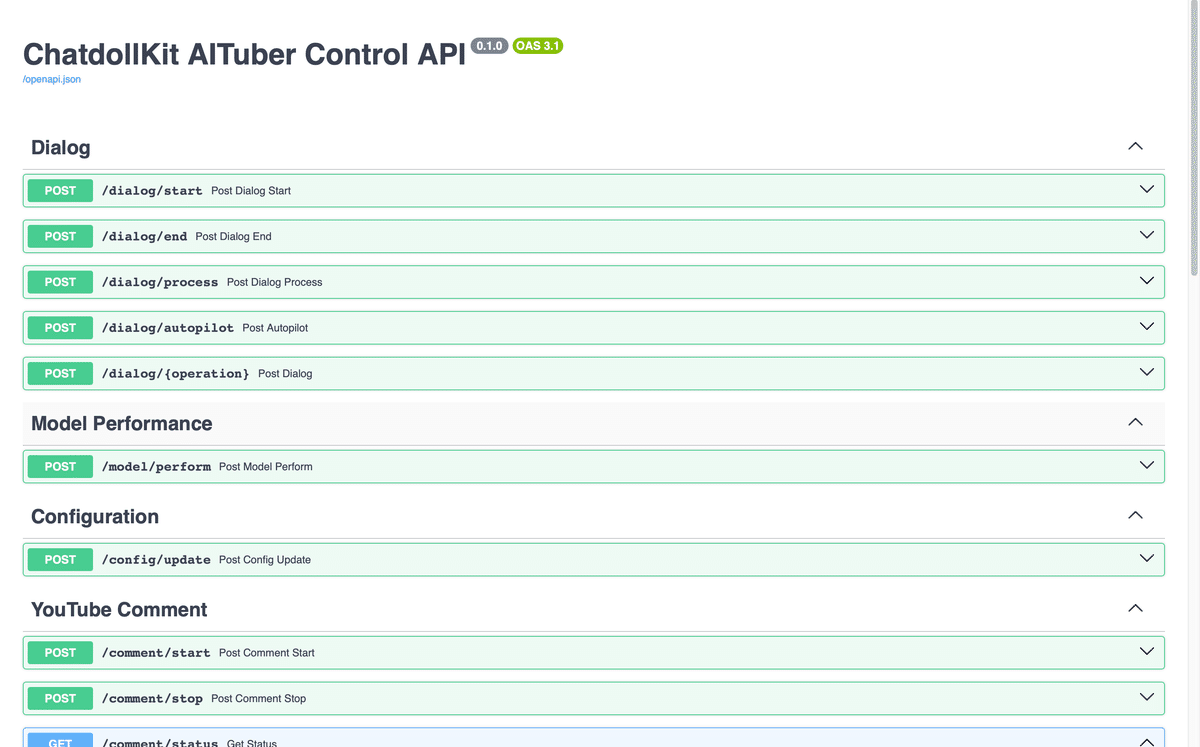
なお起動する際に --host 0.0.0.0 など指定することでネットワークリーチャブルな他のデバイス(スマートフォンなど)からもコントローラーを使用することができるようになります。
動作確認1: AIキャラクターが話せること
ここまでで、AIキャラクターをコントローラーで操作し、自動的に発話させられるようになったことを確認していきます。
Unityの画面上部にある再生ボタンを押してAIキャラクターを開始してください。Tポーズから棒立ち状態に変化したら、今度はコントローラー画面の /dialog/start をクリック展開します。テキストには「!挨拶をして配信を開始してください。」などと入力し、Executeボタンを押してください。
なお冒頭の「!」は意味があって、デフォルトのシステムプロンプトでは「!」から始まる入力はディレクターからの指示として従うように命じています。

AIキャラクターが話し始めて、その後もずっと話し続けることを確認したら、Unity上でAIキャラクターを終了しましょう。
配信画面への配置
AIキャラクターを配信画面に表示させるようにしていきます。ここではOBSを使用した手順を紹介します。なお私もOBSに詳しくないので、誤っていたりより良い方法がある場合には是非教えていただけるとありがたいです🙏
詳細な手順は省略しますが、Unityの画面をウィンドウキャプチャーやスクリーンキャプチャーとしてソースに設定したら、トリムとサイズの調整を行いましょう。デモはグリーンバックになっていますのでクロマキーのフィルターを提供することで図のように配信画面にキャラクターだけを配置することができます。

なお、Macの場合はウィンドウキャプチャーは非推奨のようで、その影響なのかわかりませんが音声にかなりの遅延が発生します(リップシンクからズレます)。私の場合はサブディスプレイにキャラクターを表示し、スクリーンキャプチャーすることで音声遅延が解決しました。
コメントの取得設定
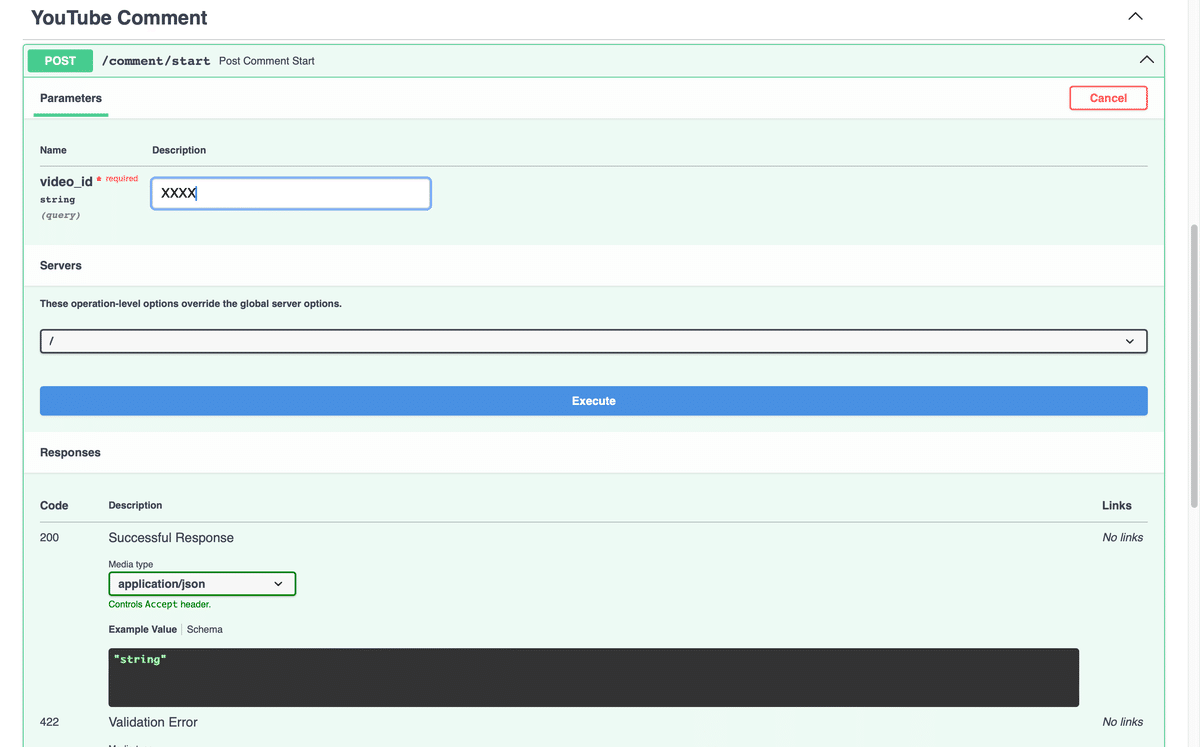
ここも詳細な手順は省略しますが、「配信開始」または「配信の管理」により動画IDを取得したら、コントローラーの /comment/start の video_id にセットして「Execute」ボタンを押してください。これでリスナーからのコメントがAIキャラクターに渡されるようになります。
動作確認2: 全体の機能確認
一応、これでシステムができあがっているはずですので、AIキャラクターが配信先画面に表示され、音声が聞こえて、コメントへの反応ができることを確認していきましょう。以下の順序で実行してみてください。
YouTubeへの配信の開始。先の手順で「配信の管理」によって動画IDを取得した場合は、OBSで配信を開始してください。動作確認用のYouTube画面を開いたら、デスクトップ音声がループしないようにタブをミュートしておきましょう。
コントローラーからの会話開始の指示。AITuberが話し始めることを確認してください。音声はスマホなど別の端末で確認すると良いでしょう。(他に良いやり方あるかな・・・?)
コメントの動作確認。YouTube画面からコメントを投稿して、それを拾ってコメントしてくれることを確認します。なおコメントは今話している内容が終わってから取得するので、拾われるまでにタイムラグがある点に注意してください。
コントローラーからの会話終了の指示。/dialog/endで、テキストには「そろそろ配信を終了してください。」などと入力して実行すると、今話している内容が終わったあとに終了の挨拶などをしてくれます。また、その後は発話が止まります。
YouTubeへの配信の終了。UnityのAIキャラクターやコントローラーも終了しましょう。
これでシステムが一通り機能することが確認できました。
ここから先はあなたが作りたいAITuber🥰にするための手順です!!
3Dモデルの変更
正直、作業モチベーションを向上するためにはこの手順を真っ先にやるのもよいかもしれません。ここではVRMを前提に手順を説明します。
3Dモデルの準備
お手持ちのものを利用するか、VRoid Studio、Avatar Makerなどで作成してください。

3Dモデルのインポート・シーン配置
AIキャラクターのUnityプロジェクトにVRMファイルをインポートしてください。インポートしたらプレファブをシーンに配置して、ヒエラルキー上からUnagirlを削除します。カメラの高さやキャラクターの向きなどもちょうど良い感じに調整しておきましょう。
ChatdollKitへの設定
先ほどの手順でシーンに配置した3DモデルをChatdollKitの操作対象とするための設定を行います。
AIAvatarVRM > ModelControllerのAvatar Modelに新たに配置した3Dモデルをセットし、ModelControllerのコンテキストメニューからSetup ModelControllerを実行します。
3Dモデルを選択して、AnimatorのControllerにAGIAFreeをセットします。
3Dモデルを選択して、VRMLookAtHeadのUpdate TypeにLate Updateを、TargetにMain Cameraを設定します。これによって視線がMain Cameraを追従するようになります。

音声の変更
ChatdollKitはVOICEVOXやStyle-Bert-VITS2をはじめとしてあらゆる音声合成システムに対応しています。ここでは環境の準備がしやすいVOICEVOXへの変更を解説します。あらかじめVOICEVOXをインストールして起動しておきましょう。
AIAvatarVRM > OpenAISpeechSynthesizerを削除します。
プロジェクトからChatdollKit/Scripts/SpeechSynthesizer/VoicevoxSpeechSynthesizerをAIAvatarVRMにアタッチして、VOICEVOXのURLやSpeaker IDなどを設定します。
システムプロンプトと会話継続プロンプトの変更
AIAvatarVRM > ChatGPT ServiceのSystem Message Contentに設定します。システムプロンプトはAITuberの魂となる部分ですので、気合を入れて編集しましょう。
また、AIAvatarVRM > Main AI TuberのAuto Pilot Request Textは、リスナーからのコメントがない時に発話の継続を促す際に内部的に使用されます。これも話の展開の仕方を左右しますので、調整しながらいろいろ試してみてください。
LLMの変更
前の手順で示したChatGPT Serviceを削除、またはIs Enabledのチェックを外して、ChatdollKit/LLMからGemini ServiceやClaude Serviceなど好みのものをアタッチし、Is Enabledにチェックを入れてください。APIキーやシステムプロンプトもセットしたら当該LLMが利用されるようになります。
アプリとしてビルド(推奨)
ハイスペックなマシンであればUnityエディターのままでも良いかもしれませんが、手元のM3プロセッサーのMacBook Airでは200~300%近くのCPU使用率となってしまいます。アプリとしてビルドすることで30~50%まで大幅に負荷が軽減できましたので、ビルドすることをお勧めします。
おわりに
私自身がAITuberはおろかVTuberにもそれほど詳しくないので、皆さんから「こうしたほうがいいよ」「こういうのあると便利だよ」といったご意見をいただけますと幸いです✨🙏✨
あと全体的に説明が走り書きなので、わかりづらいところは遠慮なくお知らせくださいませ。
それでは、皆さんのすてきなAITuberにお会いできることを楽しみにしています!!