ローカルKubeflowのPipelineでGCPを操作する

MiniKFでローカルにたてたKubeflowのPipelineでGCPを操作してみた
とりあえず公式ドキュメントを参考に作成してみた感じ
今回はETL的なイメージで「csvファイルをGCSにアップロード」、「GCSからBQにデータをロード」と言う2stepをパイプラインで実現

csvをGCSにアップロードComponent作成
基本ディレクトリ構成はベスプラ参考にしてこんな感じ
(100MB以上あるcsvとかはgitで管理できないんのでgit-lfsあたりを導入
components
└── forecasting
└── upload_from_local_to_gcs
├── Dockerfile
├── README.md
├── build_image.sh
├── requirements.txt
└── src
├── data
│ ├── calendar.csv
│ ├── sales_train_validation.csv
│ ├── sample_submission.csv
│ └── sell_prices.csv
└── main.pyGCSにアップロードするmain.pyを作る
from google.cloud import storage
import argparse
import os
from os import listdir
def main():
parser = argparse.ArgumentParser(description='ML Trainer')
parser.add_argument('--bucket-name', type=str, help='Google Cloud Storage bucket name', required=True)
parser.add_argument('--bucket-dir', type=str, help='Google Cloud Storage bucket dir', required=True)
args = parser.parse_args()
storage_client = storage.Client()
bucket = storage_client.bucket(args.bucket_name)
destination_blob_dir = args.bucket_dir
source_dir = os.path.join(os.path.dirname(__file__), 'data')
for file in listdir(source_dir):
destination_blob_name = f"{destination_blob_dir}/{file}"
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(os.path.join(source_dir, file))
with open('/tmp/output_bucket_name.txt', 'w') as f:
f.write(args.bucket_name)
with open('/tmp/output_bucket_dir.txt', 'w') as f:
f.write(destination_blob_dir)
if __name__ == '__main__':
main()
ポイントとしては以下
1. アップロードするバケットとディレクトリをパイプラインの引数で指定
2. 次のComponentのInputとして渡したいものをOutputとして出力
requirements.txtに必要なパッケージ記載
google-cloud-storage==1.27.0pythonをローカルで実行して動作すること確認したら、コンテナ化のためのDockerfile作成
FROM python:3.8.2
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY ./src /pipelines/component/src
ENTRYPOINT ["python", "/pipelines/component/src/main.py"]ビルドしてGoogle Container Registryにpushするためのbuild_image.shも作っとく。[project_name]は自分のGCP Project nameを指定してください。
#!/bin/sh
if [ $# -lt 1 ]; then
cat << EOS
image_tag argument is required.
ex) sh build_image.sh 0.1.0
EOS
exit
fi
IMAGE_TAG="$1"
image_name=asia.gcr.io/[project_name]/forecasting/upload_from_local_to_gcs
full_image_name=${image_name}:${IMAGE_TAG}
cd "$(dirname "$0")"
docker build -t "$full_image_name" .
docker push "$full_image_name"
実際にビルドしてプッシュしてみる
$ sh build_image.sh 0.1.0
Sending build context to Docker daemon 328.7MB
...
0.1.1: digest: sha256:xxx size: 2847
GCSのcsvからBQテーブル生成component作成
構成は基本的に同じで、違うディレクトリに作成した
components
└── forecasting
├── load_from_gcs_to_bq
│ ├── Dockerfile
│ ├── README.md
│ ├── build_image.sh
│ ├── requirements.txt
│ └── src
│ └── main.py
└── upload_from_local_to_gcs
GCSのCSVをBQにロードするmain.py作成
import argparse
from google.cloud import storage
from google.cloud import bigquery
def main():
parser = argparse.ArgumentParser(description='ML Trainer')
parser.add_argument('--bucket-name', type=str, help='Google Cloud Storage bucket name', required=True)
parser.add_argument('--bucket-dir', type=str, help='Google Cloud Storage bucket dir', required=True)
args = parser.parse_args()
print('args.bucket_name: ', args.bucket_name)
print('args.bucket_dir: ', args.bucket_dir)
storage_client = storage.Client()
blobs = storage_client.list_blobs(
args.bucket_name, prefix=args.bucket_dir
)
client = bigquery.Client()
dataset_id = 'raw'
dataset_ref = client. dataset(dataset_id)
job_config = bigquery.LoadJobConfig()
job_config.autodetect = True
job_config.skip_leading_rows = 1
job_config.source_format = bigquery.SourceFormat.CSV
base_uri = f"gs://{args.bucket_name}"
for blob in blobs:
num = blob.name.count('/')
string = blob.name.split('/')[num]
string_list = string.split('.')
load_job = client.load_table_from_uri(
f"{base_uri}/{blob.name}", dataset_ref.table(string_list[0]), job_config=job_config
)
load_job.result() # Waits for table load to complete.
with open('/tmp/output_dataset.txt', 'w') as f:
f.write(dataset_id)
if __name__ == '__main__':
main()
requirements.txtはこんな感じ
google-cloud-bigquery==1.24.0
google-cloud-storage==1.27.0
同様にしてDockerfileを作成(さっきのと全く同じ内容や)
FROM python:3.8.2
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY ./src /pipelines/component/src
ENTRYPOINT ["python", "/pipelines/component/src/main.py"]さっきとはimage_nameを変えたbuild_image.shを作成
[project_name]は例の如く自分のやつを設定してくだされ
#!/bin/sh
if [ $# -lt 1 ]; then
cat << EOS
image_tag argument is required.
ex) sh build_image.sh 0.1.0
EOS
exit
fi
IMAGE_TAG="$1"
image_name=asia.gcr.io/[project_name]/forecasting/load_from_gcs_to_bq
full_image_name=${image_name}:${IMAGE_TAG}
cd "$(dirname "$0")"
docker build -t "$full_image_name" .
docker push "$full_image_name"
ビルド&プッシュしておく
$ sh build_image.sh 0.1.0
Sending build context to Docker daemon 328.7MB
...
0.1.1: digest: sha256:xxx size: 2847GCP認証するための事前準備
ここが一番つまずいたポイント。基本的な流れとしては以下
1. サービスアカウント の作成
2. サービスアカウントキー(json)のダウンロード
3. GCRのprivate imageからpullするためのサービスアカウントsecret作成
4. GCS, BQに接続するためのサービスアカウントsecret作成
1. サービスアカウント の作成
以下役割を付与したサービスアカウントを作成
- BigQuery 管理者
- ストレージ管理者
- ストレージ オブジェクト閲覧者(GCR pull用)
2. サービスアカウントキー(json)のダウンロード
コンソールから作成したサービスアカウント のキーダウンロード
3. GCRのprivate imageからpullするためのサービスアカウントsecret作成
vagrantにダウンロードしたサービスアカウント キーをアップロード
そんで、Secret作成。これでPrivateなGCRからpullできる
適宜以下の通り修正して実行
・gcp_credential.jsonはダウンロードしたキーの名前
・--docker-emailはサービスアカウントのメールアドレス
$ vagrant upload gcp_credential.json /tmp/gcp_credential.json
$ vagrant ssh
vagrant@minikf:~$ kubectl create secret docker-registry regcred \
--docker-server=asia.gcr.io \
--docker-username=_json_key \
--docker-password="$(cat /tmp/gcp_credential.json)" \
--docker-email=for-local-test@[project_name].iam.gserviceaccount.com \
-n kubeflow4. GCS, BQに接続するためのサービスアカウントsecret作成
3. と同様にvagrant上でもうひとつsecret作成
vagrant@minikf:~$ kubectl create secret generic user-gcp-sa -n kubeflow --from-file=user-gcp-sa.json=/tmp/gcp_credential.jsonComponentを繋ぐPipelineを作成
2つのComponentディレクトリと並列したとこにパイプラインを置いてみる
components
└── forecasting
├── load_from_gcs_to_bq
├── pipeline.py
├── pipeline.tar.gz
└── upload_from_local_to_gcs
pipeline.pyはこんな感じにした
[project_name]は適宜変更ください
import kfp
from kfp import dsl
from kfp import gcp
import kubernetes
def load_from_gcs_to_bq(bucket_name, bucket_dir):
return dsl.ContainerOp(
name='load csv files from gcs to bq',
image='asia.gcr.io/[project_name]/forecasting/load_from_gcs_to_bq:0.1.0',
arguments=[
'--bucket-name', bucket_name,
'--bucket-dir', bucket_dir,
],
file_outputs={
'dataset': '/tmp/output_dataset.txt',
}
).apply(gcp.use_gcp_secret())
def upload_from_local_to_gcs_op(bucket_name, bucket_dir):
return dsl.ContainerOp(
name='upload csv files from local to gcs',
image='asia.gcr.io/[project_name]/forecasting/upload_from_local_to_gcs:0.1.0',
arguments=[
'--bucket-name', bucket_name,
'--bucket-dir', bucket_dir,
],
file_outputs={
'bucket_name': '/tmp/output_bucket_name.txt',
'bucket_dir': '/tmp/output_bucket_dir.txt',
}
).apply(gcp.use_gcp_secret())
@dsl.pipeline(
name='m5 forecasting pipeline',
description='A pipeline fro m5 forecasting.'
)
def m5_forecasting_pipeline(bucket_name, bucket_dir):
dsl.get_pipeline_conf().set_image_pull_secrets([kubernetes.client.V1LocalObjectReference(name="regcred")])
_upload_from_local_to_gcs_op = upload_from_local_to_gcs_op(bucket_name, bucket_dir)
load_from_gcs_to_bq(
_upload_from_local_to_gcs_op.outputs['bucket_name'],
_upload_from_local_to_gcs_op.outputs['bucket_dir'],
).after(_upload_from_local_to_gcs_op)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(m5_forecasting_pipeline, __file__ + '.yaml')
ポイントとしては以下
1. set_image_pull_secretsメソッドで先ほど作ったsecretを指定。これでGCRのprivate repositoryからpullできる
2. apply(gcp.use_gcp_secret())で先ほど作ったもう一つのsecretを指定。これでpodからGCS, BQへアクセスできる
3. def m5_forecasting_pipeline(bucket_name, bucket_dir):でUIから指定できる引数を指定
4. file_outputsでプログラム内で出力したパスを指定。_upload_from_local_to_gcs_op.outputs['bucket_name']で前のcomponentの出力を取得して次のcomponentの入力として渡す
Pipelineをコンパイル
以下コマンドを実行
$ dsl-compile --py pipeline.py --output pipeline.tar.gzPipelineをデプロイ
UIでUpload pipelineをクリックして生成したpipeline.tar.gzをアップロード
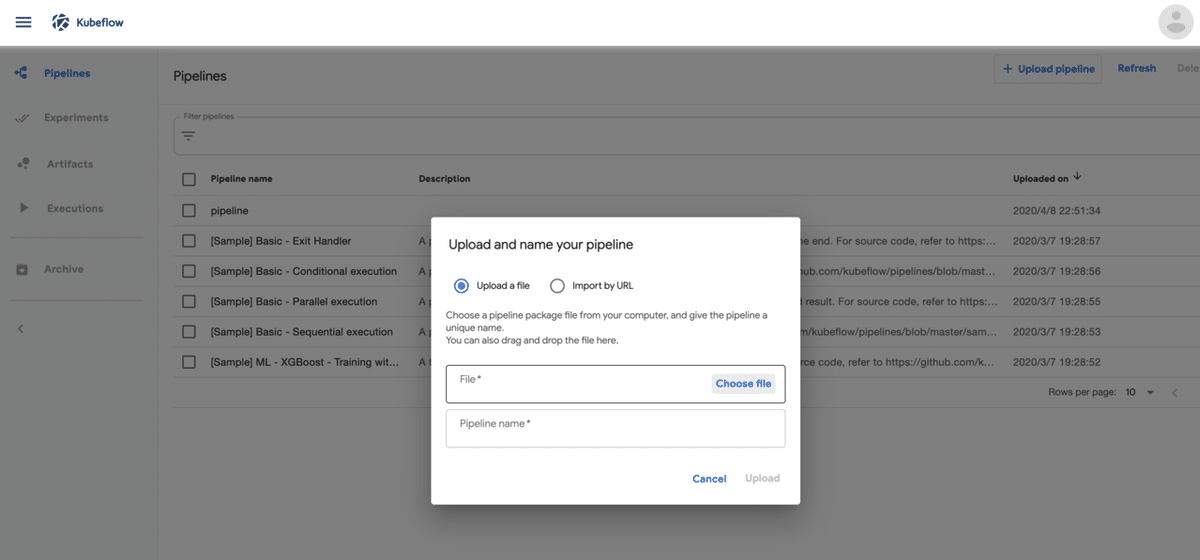
Pipeline実行
Experiment作成
pipelineで「Create experiment」ボタンをクリックして作成

Pipeline実行
「Create run」ボタンをクリックして、pipeline, experimentを指定
アップロードしたいGCSのバケットとディレクトリを指定して実行!

こんな感じでグリーンOKなアイコンがついてGCS, BQにデータ格納される

所感
なんとかたどり着いた
GCSとの認証周りでつまづいたが、それ以外は割とスムーズに進んだ。
componentの再利用性向上、UIでの結果可視化など、まだまだトライしたい部分あるので引き続き時間見つけて勉強しよう