
YouTube音声をテキスト化する旅

はじめに
皆さん、YouTube動画の音声をテキストに変換する技術的な挑戦に、共に取り組みましょう。この記事では、OpenAIの画期的な音声認識モデル「Whisper」を用いて、YouTube動画の音声からテキストへの変換プロセスを詳細に解説します。本ガイドは、特定のプラットフォームやツールに依存しない一般的なアプローチを取っており、さまざまな環境での応用が可能です。
ステップ1: 動画の音声ダウンロード
最初の課題は、YouTube動画から音声をダウンロードすることでした。ここでは`pytube`ライブラリを使用して、直接音声ファイルをダウンロードします。以下は、そのプロセスを簡潔に示すPythonスクリプトです。
from pytube import YouTube
def download_audio_from_youtube(video_url, download_path):
yt = YouTube(video_url)
audio_stream = yt.streams.get_audio_only()
audio_stream.download(output_path=download_path)この関数を使用して、指定されたYouTube動画のURLから音声ファイルをダウンロードし、ローカルに保存します。
ステップ2: 音声ファイルの形式変換
ダウンロードした音声ファイルをWhisperが処理できる形式に変換する必要があります。ここで`ffmpeg`を使用して、MP4形式からMP3形式への変換を行います。以下は、この変換プロセスを行うPythonスクリプトの例です。
import subprocess
def convert_mp4_to_mp3(audio_file_path):
mp3_file_path = audio_file_path.replace('.mp4', '.mp3')
subprocess.run(['ffmpeg', '-i', audio_file_path, mp3_file_path])この関数は、ダウンロードしたMP4ファイルをMP3形式に変換し、同じディレクトリに保存します。
ステップ3: Whisperによるテキスト変換
OpenAIのWhisperを使用して、MP3形式の音声ファイルをテキストに変換します。初期の試みでは、コマンドラインからWhisperを実行しましたが、以下にPythonスクリプトを通じて実行する方法を示します。
import subprocess
def whisper_to_text(mp3_file_path, output_dir):
output_txt_path = f"{output_dir}/output.txt"
subprocess.run(['whisper', mp3_file_path, '--output', output_txt_path])この関数は、指定されたMP3ファイルをテキストに変換し、結果を指定されたディレクトリにテキストファイルとして保存します。
ステップ4: faster-whisperの実装
処理速度をさらに向上させるために、`faster-whisper`ライブラリの導入を試みました。以下に、`faster-whisper`を使用して音声ファイルをテキストに変換するプロセスを示すPythonスクリプトを追加します。
from faster_whisper import WhisperModel
def faster_whisper_to_text(audio_file_path, output_dir):
model = WhisperModel(model='base')
result = model.transcribe(audio_file_path)
with open(f"{output_dir}/output.txt", 'w') as output_file:
output_file.write(result["text"])OpenAIのWhisperよりも高速なテキスト変換するfaster-whisperへの期待は大きかった。しかし、実際に導入してみると、期待ほどの速度向上は見られませんでした。
ステップ4: Whisperへの回帰
結果として、元のWhisperモデルへと回帰しました。Whisperの信頼性と精度は、少々の時間差を補って余りある価値がありました。以下に、最終的に使用したPythonスクリプトを記載します。このコードは、YouTube動画の音声をダウンロードし、それをテキストに変換する一連のプロセスを実装しています。
import subprocess
import os
from pytube import YouTube
def download_audio_from_youtube(video_url, download_path):
try:
yt = YouTube(video_url)
audio_stream = yt.streams.get_audio_only()
audio_file_path = audio_stream.download(output_path=download_path)
return audio_file_path
except Exception as e:
print(f"Error downloading video: {e}")
return None
def convert_mp4_to_mp3(audio_file_path):
mp3_file_path = audio_file_path.replace('.mp4', '.mp3')
try:
subprocess.run(['ffmpeg', '-i', audio_file_path, '-q:a', '0', '-map', 'a', mp3_file_path], check=True)
os.remove(audio_file_path) # 元の.mp4ファイルを削除
return mp3_file_path
except subprocess.CalledProcessError as e:
print(f"Error converting file: {e}")
return None
def whisper_to_text(mp3_file_path, output_dir, model='base', language='ja'):
output_txt_path = os.path.join(output_dir, os.path.basename(mp3_file_path).replace('.mp3', '.txt'))
try:
subprocess.run(['whisper', mp3_file_path, '--model', model, '--language', language, '--output_format', 'txt', '--output_dir', output_dir], check=True)
print(f"Text saved to: {output_txt_path}")
os.remove(mp3_file_path) # テキスト変換後、不要になったMP3ファイルを削除
except subprocess.CalledProcessError as e:
print(f"Error in Whisper conversion: {e}")
def main():
video_url = 'YouTube 動画の URL'
download_path = '保存先のパス'
audio_file_path = download_audio_from_youtube(video_url, download_path)
if audio_file_path:
mp3_file_path = convert_mp4_to_mp3(audio_file_path)
if mp3_file_path:
whisper_to_text(mp3_file_path, download_path)
if __name__ == '__main__':
main()
ここで紹介した方法やスクリプトは、Windows、MacOS、Linuxなど、さまざまなオペレーティングシステムで実行可能です。ターミナルやコマンドプロンプトの基本的な操作に慣れていれば、どのプラットフォームでも同様の手順を踏むことができます。
実際の作業に移る前に環境設定の前提条件の明確化
"このチュートリアルを始める前に、あなたのコンピューターにPythonがインストールされていること、そして基本的なターミナル操作に慣れていることを確認してください。もしPythonがまだインストールされていない場合は、Python公式ウェブサイトからダウンロードしてインストールできます。また、このプロセスでは、ターミナルやコマンドプロンプトを使用しますので、その基本的なコマンドについても事前に学んでおくとスムーズに進められます。"YouTube動画をテキストファイルに変換する方法を一緒に見ていきましょう。このプロセスを通じて、Pythonスクリプトの作成からターミナルでの実行まで、ステップバイステップで説明していきます。初心者の方でも分かりやすいよう、具体的な操作を一つ一つ丁寧に解説を心がけます
ステップ1: YouTube動画のURLを見つける
まずは、テキストに変換したいYouTube動画のURLを見つけましょう。ブラウザでYouTubeを開き、変換したい動画のページへ行って、URLをコピーします。
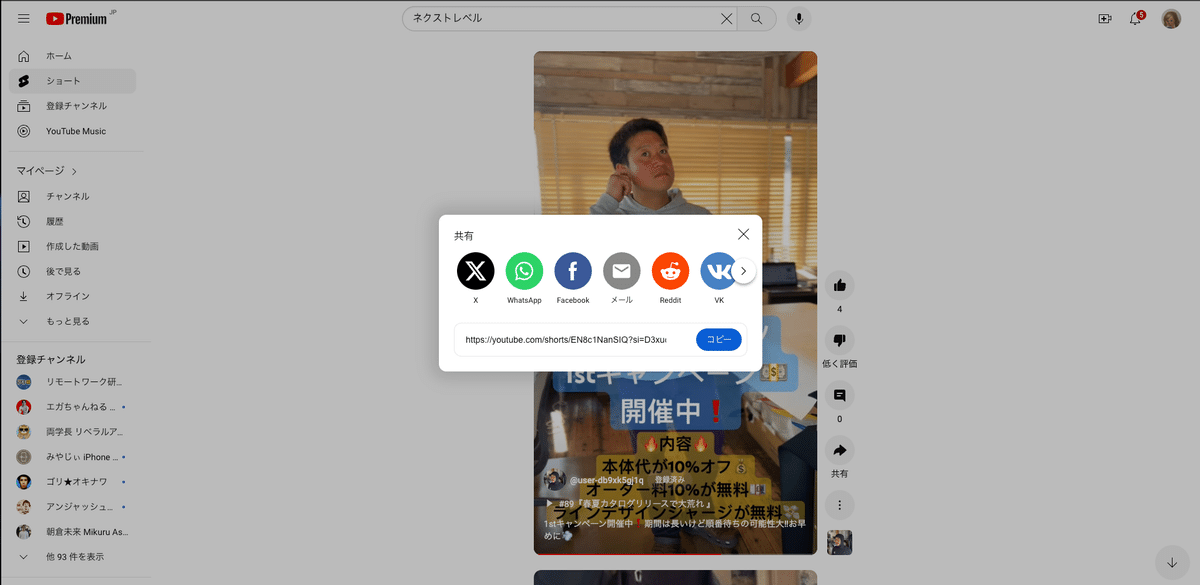
ステップ2: Pythonスクリプトの準備
次に、コピーしたURLをPythonスクリプトに入力します。
テキストエディタを開き、新しいファイルを作成して、
以下のPythonスクリプトをコピペします。
import subprocess
import os
from pytube import YouTube
def download_audio_from_youtube(video_url, download_path):
"""
指定されたYouTubeのURLからオーディオストリームをダウンロードします。
video_url: ダウンロードしたいYouTubeビデオのURL
download_path: ダウンロードしたオーディオファイルの保存先パス
"""
try:
yt = YouTube(video_url) # YouTubeオブジェクトを生成
audio_stream = yt.streams.get_audio_only() # オーディオストリームのみを取得
audio_file_path = audio_stream.download(output_path=download_path) # 指定されたパスにオーディオをダウンロード
return audio_file_path
except Exception as e:
print(f"Error downloading video: {e}")
return None
def convert_mp4_to_mp3(audio_file_path):
"""
ダウンロードしたオーディオファイル(.mp4)を.mp3形式に変換します。
audio_file_path: 変換するオーディオファイルのパス
"""
mp3_file_path = audio_file_path.replace('.mp4', '.mp3') # .mp4拡張子を.mp3に置換
try:
# ffmpegを使用してmp4からmp3への変換を実行
subprocess.run(['ffmpeg', '-i', audio_file_path, '-q:a', '0', '-map', 'a', mp3_file_path], check=True)
os.remove(audio_file_path) # 変換後は元のmp4ファイルを削除
return mp3_file_path
except subprocess.CalledProcessError as e:
print(f"Error converting file: {e}")
return None
def whisper_to_text(mp3_file_path, output_dir, model='base', language='ja'):
"""
MP3ファイルをテキストに変換します。変換にはOpenAIのWhisperモデルを使用します。
mp3_file_path: テキストに変換するMP3ファイルのパス
output_dir: 生成されるテキストファイルの保存先ディレクトリ
model: 使用するWhisperモデルの種類
language: テキスト変換に使用する言語
"""
output_txt_path = os.path.join(output_dir, os.path.basename(mp3_file_path).replace('.mp3', '.txt')) # 出力テキストファイルのパスを生成
try:
# Whisperコマンドを使用してmp3からテキストへ変換
subprocess.run(['whisper', mp3_file_path, '--model', model, '--language', language, '--output_format', 'txt', '--output_dir', output_dir], check=True)
print(f"Text saved to: {output_txt_path}")
os.remove(mp3_file_path) # テキスト変換後、不要になったmp3ファイルを削除
except subprocess.CalledProcessError as e:
print(f"Error in Whisper conversion: {e}")
def main():
"""
メイン関数。ここからプログラムが始まります。
"""
video_url = 'ここにコピーしたYouTube動画のURLを貼り付けます'
download_path = '保存先のパスを指定します'
audio_file_path = download_audio_from_youtube(video_url, download_path)
if audio_file_path:
mp3_file_path = convert_mp4_to_mp3(audio_file_path)
if mp3_file_path:
whisper_to_text(mp3_file_path, download_path)
if __name__ == '__main__':
main()
先ほどコピーしたURLをスクリプト内へ入力します。
URL: https://youtube.com/shorts/EN8c1NanSIQ?si=YPor_JzNT066R63S
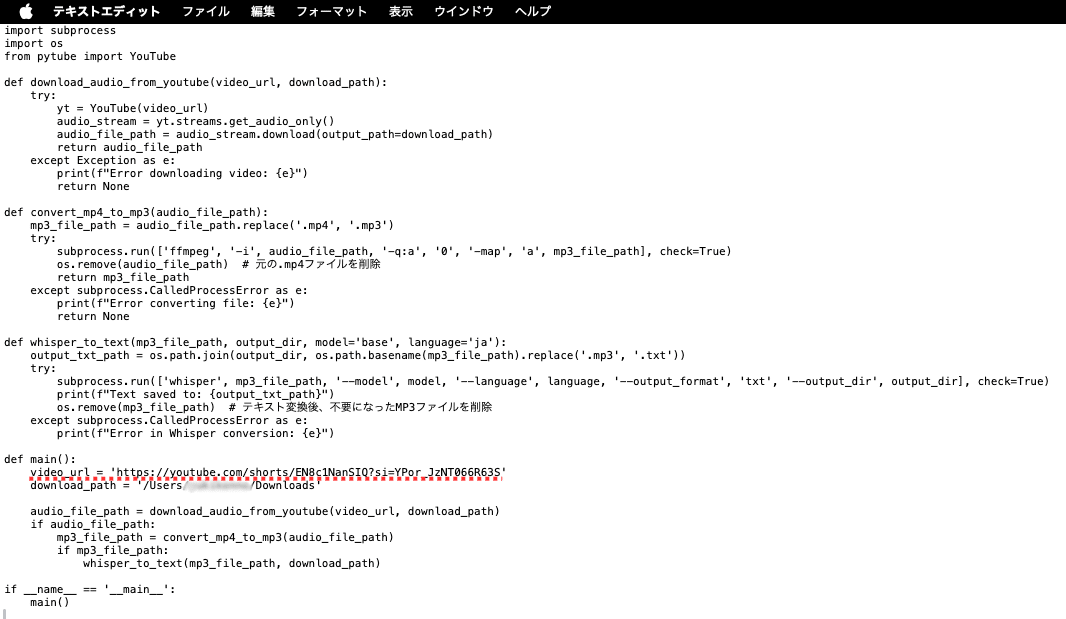
保存先のパスも設定します。
私はダウンロードフォルダへ設定しました。
保存先: download_path = '/Users/********/Downloads'

このファイルを「youtube_to_text.py」という名前で保存します。名前の部分は任意ですが、わかりやすい名前にしましょう。拡張子が「.py」であることを確認してください。

ステップ3: ターミナルでスクリプトを実行
ここからが本番です。ターミナル(またはコマンドプロンプト)を開き、Pythonスクリプトを保存したディレクトリに移動します。ディレクトリの移動には`cd`コマンドを使用します。私の場合、以下のように入力します。
cd /Users/********/Downloads/02.Script正しいディレクトリに移動したら、スクリプトを実行します。以下のコマンドを入力してください。
python youtube_to_text.pyステップ4: 結果の確認
スクリプトが正常に実行されると、指定した保存先にテキストファイルが生成されます。生成されたテキストファイルを確認しましょう。
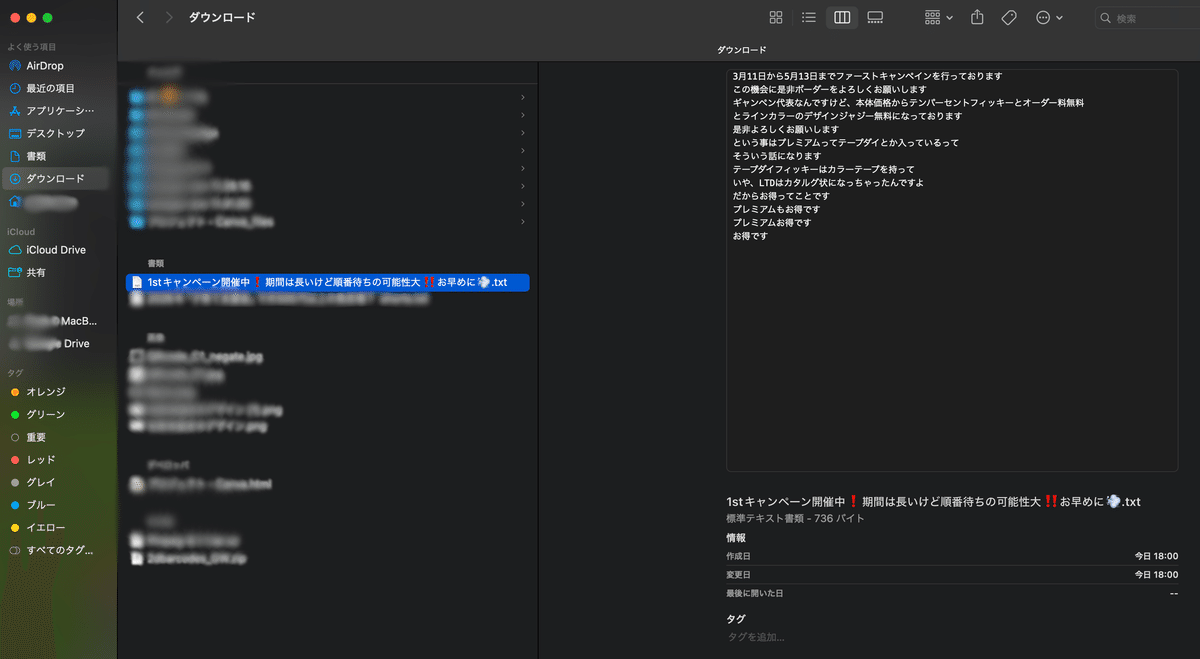
PythonでYouTube動画をテキスト化する際の一般的なエラーとその対処法
ステップ 1: 環境設定の問題の診断
問題発生: スクリプトを実行しようとした際に、以下のいずれかのエラーが発生。
`cd: not a directory`: 指定されたパスがディレクトリではない。
`command not found: python`: Pythonが見つからない、または環境にインストールされていない。
`ModuleNotFoundError: No module named 'pytube'`: 必要な`pytube`モジュールがインストールされていない。
`error: externally-managed-environment`: Python環境が外部で管理されており、直接の`pip`インストールができない。
ステップ 2: 仮想環境の作成と有効化
解決策の提案: `pytube`モジュールのインストール問題を解決するため、Pythonの仮想環境を作成し、有効化する。
実施内容:
`python3 -m venv ~/venvs/myvenv`: ホームディレクトリ内に新しい仮想環境`myvenv`を作成。
`source ~/venvs/myvenv/bin/activate`: 作成した仮想環境を有効化。
ステップ 3: 必要なパッケージのインストール
実施内容: 有効化された仮想環境内で、`pip install pytube`コマンドを実行して`pytube`パッケージをインストールしました。
ステップ 4: スクリプトの実行とデバッグ
実施内容:
スクリプト`youtube_to_text.py`を実行した結果、`ffmpeg`を用いた処理が行われ、YouTubeのビデオが正常にテキストに変換されました。
処理中に`FP16 is not supported on CPU; using FP32 instead`という警告が表示されましたが、これは使用されているライブラリの内部処理に関連するもので、処理の成功には影響しませんでした。
ステップ 5: 成功の確認
注意点:
このプロセスは、特定のPython環境やライブラリのバージョンに依存する可能性があります。将来的には、Pythonやライブラリのバージョンアップに伴い、手順の一部を調整する必要が生じるかもしれません。
仮想環境の使用は、プロジェクト固有の依存関係を管理しやすくするため、強く推奨されます。
安全性と倫理性について
YouTube動画をダウンロードする際には、常に著作権やその他の法律を尊重することが重要です。個人的な使用や教育目的での使用は一
般的に許可されている場合が多いですが、ダウンロードしたコンテンツを無断で再配布したり、商業目的で使用することは法律に違反する可能性があります。また、YouTubeの利用規約や著作権法は国や地域によって異なるため、自身の居住する国や対象のコンテンツが発信されている国の法律を事前に確認することが重要です。私たちは技術的な知識の共有を目的としていますが、このチュートリアルで紹介する技術や方法を使用する際には、それらの法的な側面に注意し、倫理的に行動することを強く推奨します。情報は責任を持って使用しましょう。
結論
この冒険を通じて、YouTube動画の音声をテキストに変換するプロセスを深く理解し、OpenAIのWhisperをはじめとする強力なツールを効率的に使用する方法を学びました。このNoteが、同様の課題に直面している方々にとって参考になり、より効率的で効果的な解決策を見出すための一助となることを願っています。技術は常に進化しており、このNoteが皆さんの知識を広げ、新たな発見への扉を開くきっかけになれば幸いです。もし何か疑問点があれば、コメントで質問してください。
これで今回の記事の内容は全てとなります。最後までご覧いただき、心から感謝申し上げます。この記事が皆様のお役に立てば幸いです。
今回ご紹介した内容にご満足いただけた場合、「記事へのサポート」として100円の寄付を募集しております。ご支援いただくことで、より質の高いコンテンツを提供するための励みになります。もちろん、寄付は完全に任意であり、皆様がこの記事を楽しんでくださったこと自体が私たちにとって最大の報酬です。今後ともよろしくお願いいたします。
ここから先は