Google Colab + OpenCVで顔認証

はじめに
こちらのマガジン、久しぶりに更新します。
いろいろ作っていたのですが、なかなかNoteの更新をしていませんでした。
そろそろ追加で出していきたいと思います。
とはいえ、今年はアウトプットの年と位置づけています。
とはいえ、スキルチェックで資格チャレンジも計画しているので、不定期更新になるかと思います。
前置きはさておき、顔認証、これで2回目です。
前回はPC環境なのですが、Anacondaを利用しての顔認証環境の構築でした。
ところが、これ環境構築でいろいろトラブルことがわかりました。
そこで、同じ環境で誰でもチャレンジできる、が今回のコンセプトです。
使わせていただいたサイトは
です。コードはこちらを使わせていただいております。
Uranishiさんありがとうございます。
そこに自分の覚書を書いたものとなります。
まずは概要。
今回のプログラム、Qiitaにあるように、メインの顔認証はOpenCVです。
その初回は、OpenCVに搭載されているDNN(ディープニューラルネットワーク Deep Neural Network)を利用しての顔認証です。
画像ではつまらないので、PC搭載のカメラを用いての顔認証にチャレンジしてみたものとなります。
環境構築
では早速、環境構築をしてきましょう。
環境構築は簡単です。
Googleアカウントをご用意ください。
で、googleから、Google colab、と入力しましょう。
アカウントを聞かれたら、ご自身のGoogleアカウントを入力してください。
Google chromeでアカウントを入れている場合は自動で開きます。
上のように、Colabへようこそ、と表示されたらOKです。
では、メニューのファイルー>ノートブックを新規作成、を押して新しいノートブックを開きます。
これで基本的には環境構築は完成です。
ライブラリのインポート
では実際にプログラムを入力していきます。
とはいえ、私の作ったものをアップしますので、こちらのコピーをすればOKです。
まずは必要なPythonライブラリのインポートです。
# Google Driveをマウント
from google.colab import drive
drive.mount('/content/gdrive')
# imshowサポートパッチのインポート
from google.colab.patches import cv2_imshow
# dnn用
from IPython.display import display, Javascript
from google.colab.output import eval_js
from base64 import b64decode
# その他パッケージ
import imutils
import numpy as np
import matplotlib.pyplot as plt
import cv2Googleドライブ、カメラ、OpenCV、その他Numpyなどをインポートします。
Google ColabでPCカメラを使う
この部分は
金子研究室のHPを参考にしました。
Googleが提供しているスニペットを利用します。
Colab画面で左にある<>というコードスニペットをクリックしてください。
その時の画像がこちらです。
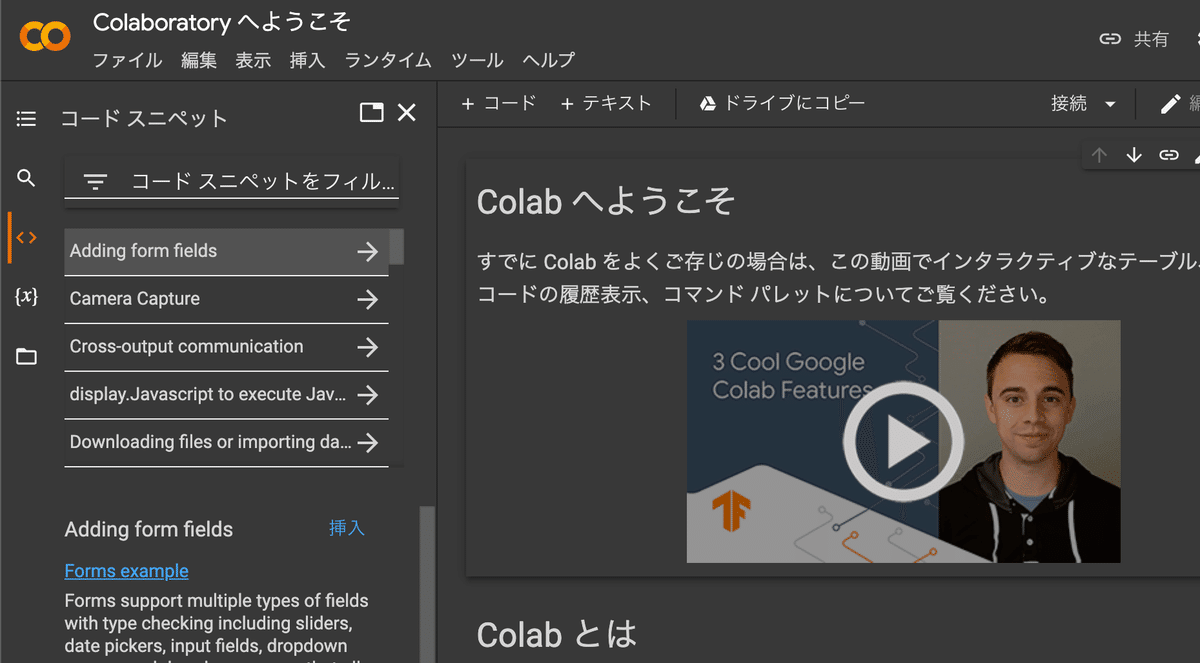
コードスニペットの部分がオレンジ色に、で選択可能なコードスニペットの一覧が表示されるようになります。
今回使うのは、「Capture Camera」です。
こちらでPC上のカメラをColab上で使うことができるようになります。
Capture Cameraをクリックし、「挿入」をクリックしてください。
すると、コード部にスニペットが挿入されます。
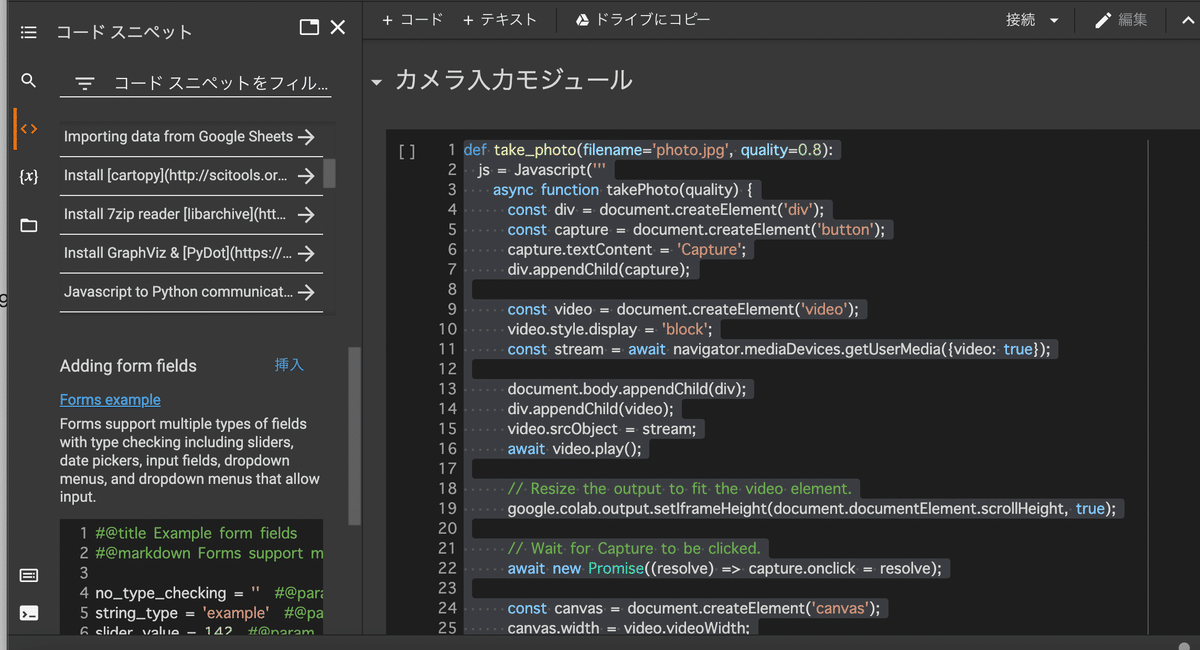
実行するとカメラを使えるようになります。
Javascriptの部分もあるようですね。
まだ実行せず、次に進みます。
学習済みモデルのダウンロード
今回はOpenCVで公開されている学習済みモデルを利用します。
そのため、モデルをダウンロードする、という作業が入ります。
!wget -N https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
!wget -N https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel!wgetコマンドなど、Linuxのコマンドを!をつけることで利用できるのもColabの利点ですね。
wgetを使って、Githubよりモデルをダウンロードします。
ダウンロードするのは
deploy.prototxt: ネットワーク
res10_300x300_ssd_iter_140000.caffemodel: 学習済みモデル
となります。
詳細はGithubないしはOpenCVのサイトをご覧ください。
もしくは、GoogleでCaffeモデルとして検索していただければ
オープンソースモデルである(BSDライセンス)と検索できます。
ということで今回はこちらを利用させていただきます。
今回は詳細は省き次に進みます。
カメラ画像をキャプチャして保存
カメラを使って認識させたい顔、ご自身でもいいですし、写真を用意してくださってもOKです。
そのコードがこちらです。
try:
filename = take_photo()
img = cv2.imread(filename)
print('Saved to {}'.format(filename))
# Show the image which was just taken.
#display(Image(filename))
except Exception as err:
# Errors will be thrown if the user does not have a webcam or if they do not
# grant the page permission to access it.
print(str(err))撮影した画像を filenameに入れ、 img に保存しています。
もし撮影できなければエラーを返すことになります。
モデルの読み込みと画像のリサイズ
# ネットワークと学習済みモデルをロードする
print("[INFO] loading model...")
prototxt = 'deploy.prototxt'
model = 'res10_300x300_ssd_iter_140000.caffemodel'
net = cv2.dnn.readNetFromCaffe(prototxt, model)こちらで、モデルとprototxt(ニューラルネットワークの構造を記述)を読み込みます。
詳細は以下をご覧ください。
続いて、画像をリサイズ(整形)してBlobを作成します。
# 幅400画素になるようにリサイズする
img = imutils.resize(img, width=400)
(h, w) = img.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(img, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0))blobとは、Binary Large Objectの略で、画像や音声などバイナリ形式のデータを格納するためのデータ型です。
詳細は
最近は、AzureなどのBlob storageなどで知られていますね。
今回はクラウドメインではないので、早速次へ。
# 物体検出器にblobを適用する
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()顔認証と検出結果(バウンディングボックス)の表示
for i in range(0, detections.shape[2]):
# ネットワークが出力したconfidenceの値を抽出する
confidence = detections[0, 0, i, 2]
# confidenceの値が0.5以上の領域のみを検出結果として描画する
if confidence > 0.5:
# 対象領域のバウンディングボックスの座標を計算する
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# バウンディングボックスとconfidenceの値を描画する
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(img, (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.putText(img, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)この部分で、カメラ画像から顔認証を行い、その確率が50%以上のところにバウンディングボックスという、ボックスを表示します。
# 出力結果を表示して保存
cv2_imshow(img)
cv2.imwrite("/content/gdrive/My Drive/Works_OpenCV/OpenCV_Colaboratory/dnn_face_out.jpg", img)最後が結果を描画する部分です。
中身をちょっとだけ説明
confidence値が認証の信頼性を表す部分です。今は0.5、つまり50%以上としています。こちらの精度を上げると正確に認証できたものだけが表示されるようになります。
次に、ボックスは、cv2.rectangleで表示しています。
box = で認証結果から、箱を描画するStartとEndを取得し、四角Rectangle
を描画しています。
ここの、(0, 0, 255)が色(RGB)です。今は赤を指定しています。
ここで好きな色を調べて表示させることができます。
一例として、
白(255,255,255)、青(0,0,255)、黄色(255,255,0)
です。
ここでお気づきかと思います。
おいおい、下の箱と文字、赤じゃないか、
そうなんです。
これRGBではなく、BGRなんです。
なので、Redが255だから赤となります。
色を変えたい場合は、このRGB(Red, Green, Blue)ではなく、BGR(Blue, Green, Red)でご記入ください。
続いて、FONT_HERSHEY_SIMPLEX は表示する文字のFONTです。
こちらのサイトを参考に変えてみて遊んでみてください。
認証実行
では実行してみましょう。
ここまで来たら、Colabのメニューから
ランタイムー>全てのセルを実行
として、実行してください。
途中、ドライブへの接続を許可するか聞いてきます。
ご自身のアカウントを選択し、下にある許可をクリックします。
ご自身のGoogle Driveに接続され、以下が実行されます。
カメラが起動すると、上に「Capture」という白く小さい表示があります。
こちらをクリックすることで、カメラ画像を取得します。
今回はGoogleの検索で表示された、竹内結子さん、のストロベリーナイト姫川刑事のときの画像をipadに表示させて、カメラで読み取らせました。

下まで実行されると、先程キャプチャされた顔+バウンディングボックス+信頼性の数値が表示されているかと思います。

99.3%で顔を識別しています。
参照
竹内さんファンでした。
このドラマを観てから小説をみると、頭の中の映像には竹内さんで変換されていました。
それもあり、誰をと考えた時に真っ先にお名前が浮かび、使わせていただきました。
もちろん原作も好きで、最新だけ追えていないですが読んでいます。
それにしても、今後も観ていたい女優さんでした。
ご冥福をお祈りいたします。
(著作権の問題がある場合はご指摘ください。画像を差し替えます。今のところGoogleで検索されたので使わせていただいております)
再度ですが、こちらを作りにあたり、
こちらを使わせていただきました。
ありがとうございます。
Uranishiさんがおっしゃるとおり、ちょっと認証制度高すぎですよね。
なので、そのうち前回搭載カスケード分類器でもチャレンジしてみたいと思います。