音楽生成 MusicGen

また新しい生成AIが誕生しました。
MusicGen
Simple and Controllable Music Generation
だそうです。
こんな記事をみつけました。
その生成AIの
Abstractはこちら
We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen
日本語訳はこちら
我々は、条件付き音楽生成という課題に取り組んでいる。MusicGenは、圧縮された離散的な音楽表現(トークン)の複数のストリームに対して動作する単一の言語モデル(LM)であることを紹介します。先行研究とは異なり、MusicGenは1段の変換LMと効率的なトークンインターリーブパターンで構成されており、階層化やアップサンプリングなど、複数のモデルをカスケードする必要がない。このアプローチに従って、MusicGenがどのように高品質のサンプルを生成できるかを実証し、同時にテキスト記述やメロディーの特徴に条件付けして、生成される出力をよりよく制御できるようにします。自動と人間の両方を考慮した広範な実証評価を行い、標準的なtext-to-musicベンチマークにおいて、提案アプローチが評価済みのベースラインよりも優れていることを示す。アブレーション研究を通じて、MusicGenを構成する各コンポーネントの重要性を明らかにする。
FaceBook社が作ったAIです。
論文はこちらです。
サイトはこちら
サンプル
MusicGen、MusicLM、Riffusion、Musaiの生成結果が比較できます。
メロディーコンディショニング
クラシック音楽の有名なメロディーと、新しいテキストの説明から、あらたな音楽を生成できます。
では実際に試せるサイトは
1つは Hugging Faceに用意されていました。

Exampleはこちらです。
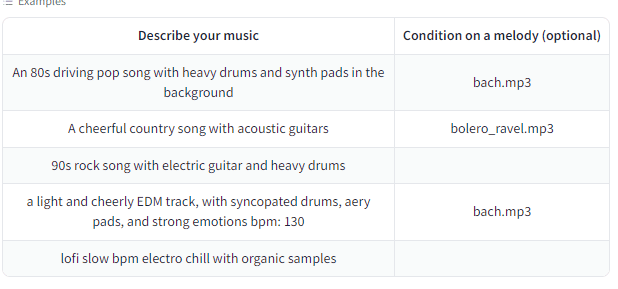
Describe your music
にPromptを入れてGenerateを押すと生成してくれます。
例もあるので、参考にして入れてみましょう。
入れてみたのは、90年代ロック、です。
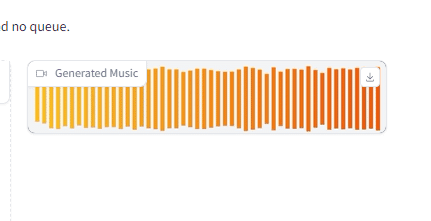
生成されるとこのようになります。
で、生成されたのがこちら。12秒のロックです。
そんなプログラム群がGithubに掲載されているようです。
そのFacebooks社のGithubはこちらです。
APIが用意されていますした
small Text to music
medium Text to music
melody Text to music and text+melody to music
large Text to music
4種のモデルが用意されています。
Google Colabでのデモ、demo.ipynb が用意されていました。

Cudaを使うので、ランタイムからランタイムタイプを、GPUかTPUに変更が必要ですね。
切り替えてからスタートしてみます。
結果がこちら。
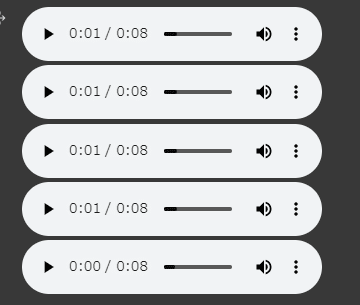
最後の曲
earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves
で生成されたのが上のファイルです。
もう一つのデモがありました。
それがこちらです。
# Adapted from https://github.com/camenduru/MusicGen-colab
%cd /content
!git clone https://github.com/facebookresearch/audiocraft
%cd /content/audiocraft
!pip install -r requirements.txt
# Click on the gradio link that appear.
!python app.py --share
# See also https://colab.research.google.com/drive/1fxGqfg96RBUvGxZ1XXN07s3DthrKUl4-?usp=sharing
# for a Colab demo using the underlying API instead.生成された画面がこちら。
Google Colab用のデモなので、全て実行、で実行します。
するとリンクが生成されるので、こちらをクリックします。
するとこの画面に行きつきます。

使い方は、Input Textに、生成したい音楽のプロンプトを入力し、生成ができます。
モデルとDuration(長さ)を選び、送信ボタンを押してください。
生成された音源がこちら
実はまだデモがあります。Github上からコピペして、
自分のGoogle Colabに貼り付けます。
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained('melody')
model.set_generation_params(duration=8) # generate 8 seconds.
wav = model.generate_unconditional(4) # generates 4 unconditional audio samples
descriptions = ['happy rock', 'energetic EDM', 'sad jazz']
wav = model.generate(descriptions) # generates 3 samples.
melody, sr = torchaudio.load('./assets/bach.mp3')
# generates using the melody from the given audio and the provided descriptions.
wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)今回の試行では、特にエラーでした。
もう少し、実験を重ねたいdすね。