
絵文字を支える技術について

はじめに
こちらはmhidakaが建立したAdvent Calendar Day.3となります。
こんにちは、はじめまして、のなと申します。mhidakaさんのTweetを見つけて、初めてAdvent Calendarなるものを書いています。なにかお作法間違っていたら大目に見てください、よろしくお願いします。
軽く自己紹介をさせていただくと、普段はGoogleでAndroidのTextまわりの開発を行っており、DroidKaigiやShibuya APKで発表させていただいたりしています。最近はほぼ絵文字の話しかしてないので、絵文字おじさんと思われてそうですが、普段の仕事は絵文字に限らず、Androidの文字表示の部分は大抵面倒をみています。
今回この機会をいただいたので、どんな内容を書こうか迷ったのですが、やはり皆が読んで面白い内容というと、絵文字になるのかなぁ、ということで性懲りもなく絵文字について書くことにしました。でもさすがに絵文字おじさんがすぎるので、これを最後にするという思いから、雑多な知識をまとめた絵文字の総集編的な記事にすることにしました。昔、Qiitaに一度書いたことがある内容とかぶるのですが、なぜかQiitaのアカウントを消していたので、改めて書かせていただきたいと思います。知っておいたら役に立つかもしれないし、これから絵文字を扱わないといけない立場になった方が、絵文字の技術的側面を知るのに役立つ、そんな内容を書いていきたいと思います。
この文章を読んでいくにあたって、前提とする知識はなるべく少なくなるように書いていますが、以下の知識があるとスムーズに読んでいただけるかと思います。
AndroidでHello,Worldを書いたことがある。
Unicodeという名前を聞いたことがある。
また、この文章では文字のUnicodeのコードポイント、UTF-16、UTF-8での表記をそれぞれU+XXXX,\uXXXX,\xXXで表記します。例えば文字「あ」に対してコードポイントはU+3042、UTF-16エンコードされた文字列は\u3042、UTF-8エンコードされた文字列は\xE3\x81\x82と表記します。
コードポイントやUTF-16とUTF-8を知らない人のために軽く説明をしておきますと、コードポイントというのがUnicodeが文字に割り当てた数字のことで、0x0000から0x10FFFFまであります。例えば「あ」は0x3042に割り当てられています。そして、その数値をエンコードしたもののうち、16bitの整数値でエンコードしたものがUTF-16、8bitの整数値でエンコードしたものがUTF-8となります。具体的なエンコード方法を知らなくても、本記事を読むことはできますが、気になる場合はWikipedia等を参照していただけると良いかと思います。
https://ja.wikipedia.org/wiki/UTF-16
https://ja.wikipedia.org/wiki/UTF-8
加えてDisclaimerですが、これから書く記事は、Androidのオープンソースプロジェクトである、AOSPの実装およびソースコードをもとに書いています。ほとんどの部分は他のiOSやWindowsなどでも共通するのですが、微妙に異なる挙動をすることがあるかもしれません。中の人がAndroidの開発者なので、他のプラットフォームの実装に詳しくなく、適当なことは言えないので、特段注記がなければ、Androidのことだと思って読んでいただければと思います。また、このブログはAndroid14の挙動に即して書いています。様々な理由で挙動は今後変わる可能性もありますので、あくまでも現時点での挙動や実装だと思って読んでいただけたらと思います。
また、最後にお約束なのですが、この文章は私の所属する会社とは何ら関係がなく、ここでの意見は私個人のものであり、所属するいかなるものを代表するものではありません。私的な見解以外の部分はすべて公式の公開情報をもとに書いています。
では始めていきます。
絵文字とは
まず絵文字とはなにか?絵文字は例えば😝のような文字のことです。絵のような文字ですね。ぶっちゃけ絵文字の定義ってあるんでしょうか?私は寡聞にして知らないです。言語学の話をするわけでもないので、ここでは「絵文字とはUnicodeが絵文字としてカテゴライズした記号のこと」だとおもって話を進めようとおもいます。先程「Unicodeの絵文字」といきなり言いましたが、Unicode以外の絵文字も昔はありました。というかスマホ以前の時代に日本の携帯文化で普及していた絵文字が、スマホの普及のタイミングでUnicodeに収録されたという歴史があります。とはいえ、そんなスマホ前史の話はここでは触れません。私が詳しくないというのもありますが、もはや世の中はUnicode時代なので、あまり気にする必要はないかなと。少なくともAndroidでアプリを開発する上では、Androidで完結している限り、Unicode以外の他の文字コードのことを気にする必要はありません。さらに絵文字以外にも、多言語対応、他のプラットフォームとの互換性等を考えると、現代のソフトウェア開発はUnicode一択だと思います。なので絵文字の歴史みたいな難しいお話はここではしないで、Unicodeになって以降の絵文字のお話をしていこうと思います。なお、これ以降にこの記事の中で、単に絵文字と表記した場合、それはUnicode絵文字を指します。
そんな絵文字ですが、2010年に初めてUnicodeに収録されて以降爆発的な人気になりました。当初は色がついていなかったのに、いつのまにか色がついていたりして、気づいたら世界中の人たちが利用しています。そんな人気のある絵文字ですがそのユーザーの人口はどれくらいだと思いますか?参考までに、Wikipediaによる現在の言語別ネイティブスピーカーの上位ランキングがこちらです。
1位 中国語 9億3900万人
2位 スペイン語 4億8500万人
3位 英語 3臆8000万人
・・・
8位 日本語 1億2300万人
やはり中国語は強いですね。では、これらの人たちのうち、どれくらいの人が絵文字を使うでしょうか?答えは「おそらく全員」ですね。絵文字は言語を問わず、世界中のすべての人が使います。つまり70億人がユーザー数と言ってもいいでしょう。ユーザーベースでいうと、一位の中国語のダブルスコアどころか、8倍くらいの人口がいるわけです。まぁ絵文字だけで会話が成り立つわけではないので、ネィティブスピーカーとは言わないですし、単純比較はできません。ですが、絵文字はその文字の特殊性から非常にユーザーインパクトのある文字ということがおわかりいただけるかと思います。実際「全Tweetのおよそ20%は絵文字が含まれている」とか「毎日50億の絵文字がFacebook Messengerで送信されている」とか「Instagramのコメントの半分は絵文字を含んでいる」とかいう統計が出ているみたいです。使われすぎていてヤベーですね。
そしてみんなが使い始めると、当然「俺の使いたい絵文字がないぞ!」となり、新しい絵文字というものが求められてきます。その結果、収録されている絵文字は増加の一途をたどり、現在(Unicode 15.1)では色違い等も含めると3782個の絵文字がUnicodeに収録されています。単純比較はできませんが、日本の常用漢字は2136文字です。こう見ると絵文字がどれだけ成長しているのかがよくわかりますね。
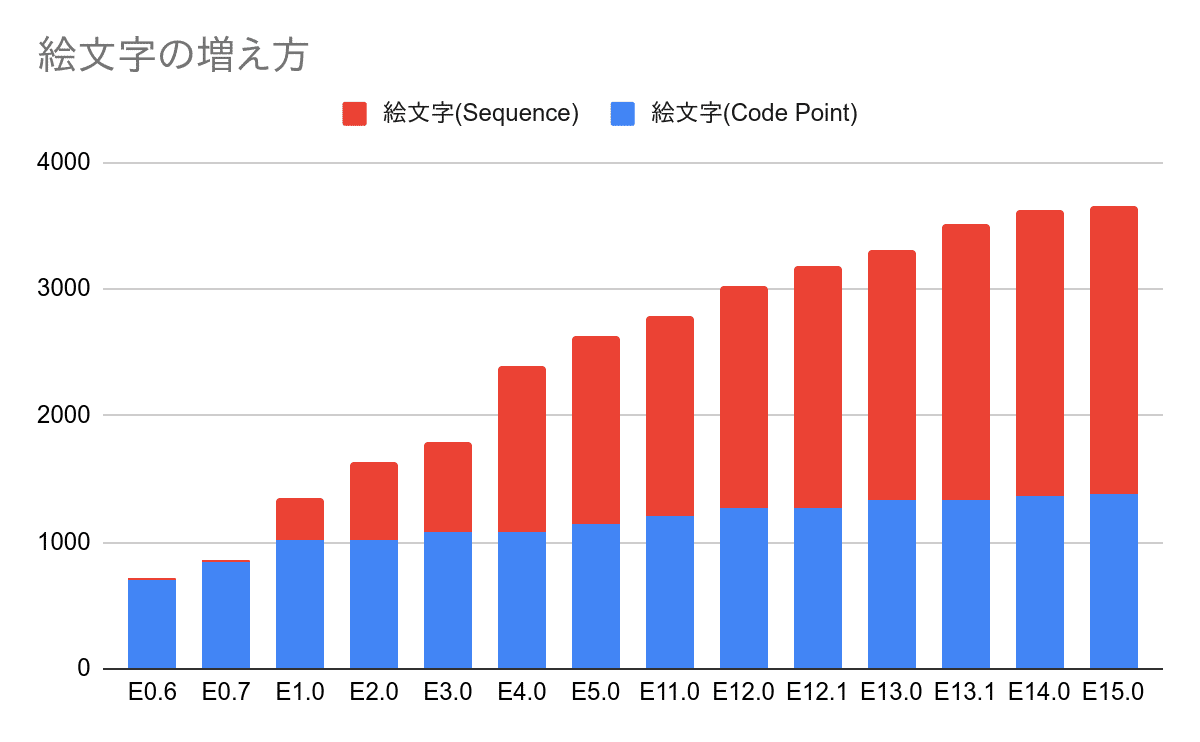
これに加えて、絵文字は注目度も高いので、新しい絵文字がUnicodeに追加されると、すぐにみんなその文字を使いたがります。なので「絵文字が新たに収録されました!でも使えるのは5年後からになります!」って言ってもだれも納得してくれないのです。これは絵文字特有の現象で、新しい漢字が追加されたからといって、「新しい漢字だ!使ってみよう!」とはならないんですよね。下手したら最近増えた漢字が何かすら知らない人が多いと思います。私も知りません。
まとめると、絵文字とは
ほぼ世界中の人達が使う文字で、個人やビジネスを問わずに高頻度で利用されていて、その数は3700文字を超えているのに、毎年新しい文字が増えていって、それがすぐに使えることが期待されている。
そんな文字です。絵文字パイセン、マジパねーっす。
絵文字を扱うときの注意点
絵文字がどんな文字なのかがわかったところで、ここから絵文字を取り扱う上で注意したほうがいい点をいくつか説明していきます。
絵文字とサロゲートペア
絵文字を扱う上で、まず最初に気をつけないといけないことは、ほとんどの絵文字はBMPではないということです。ここでいうBMPとはBasic Multilingual Planeの略で、コードポイントが16bitに収まる文字の範囲をさします。当初は「16bitもあれば全部の文字を収録できるでしょ!」って思って設計された言語が多く、例えばJavaは文字を格納するchar型を16bitにしました。もし世界中の文字がBMPに収まっていれば、「1 char = 1 コードポイント」という非常にクリアで扱いやすい世界になっていたことでしょう。ですがUnicodeは早々に16bitでは無理だと気づいて、追加のコードポイントを16bitを超える領域に確保したので、この美しい世界は早々に終わりを告げました。しかし、世の中はすでに16bitの整数型で文字列が組まれていて、いまさら追加なんてできません。そこでUnicodeはU+FFFFよりも大きなコードポイントをなんとか16bitの整数型を維持したままで扱えないかと頭をひねりました。そして出てきたのが、「2個の16bit整数を組み合わせで16bit以上のコードポイントを表せばいいんだ!」というアイデアです。この2つの16bitの数字のペアがサロゲートペアと呼ばれるものです。
具体的なサロゲートペアの仕組みを見てみましょう。サロゲートペアには、1024個のハイサロゲートと1024個のローサロゲートと呼ばれる2つのグループがあり、この合計2048個をUnicodeはサロゲート領域として確保しました。これらの領域はサロゲートペア専用の領域なので、今後決して文字は割り当てられません。こうしてUnicodeはこのハイサロゲートとローサロゲートの組み合わせである、1,024×1,024=1,048,576個の新たな領域を獲得しました。なお、このサロゲートペアには、必ずハイサロゲートの直後にローサロゲートがくるというルールがあります。なので、ハイサロゲートの直後にローサロゲートがなかったり、逆にハイサロゲートがないのに、いきなりローサロゲートが現れた場合、もしくはペアになっていたとしてもローサロゲートが先にきて、直後にハイサロゲートがきていた場合も、それらは正しくないUTF-16文字列になっています。
// 正しいUTF-16の例
val text = "\uD83D\uDC68" // U+1F468を表す。 \uD83Dはハイサロゲート,\uDC68はローサロゲート
// 正しくないUTF-16の例
val text = "\uD83D" // 直後にローサロゲートの来ないハイサロゲートは違反
val text = "\uDC68" // 直前にハイサロゲートのないローサロゲートは違反
val text = "\uDC68\uD83D" // ローサロゲート、ハイサロゲートの順番は違反 必ずハイサロゲートが先こうして約100万個のコードポイントを2つの16bit整数で表すことで獲得することができたのですが、以下のような弊害がうまれてしまいました。
UTF-16文字列の文字列長とコードポイント数が一致しなくなった。
(例:😝はUTF-16で文字列長は2、コードポイント長は1)substringを使った場合、正しくないUTF-16を作ってしまう可能性がある。
(例:😝を(0, 1)でsubstringを作ると、ハイサロゲートのみの壊れた文字列になる)
絵文字は比較的新しい文字なので、ほとんどはこのBMPではない領域に収録されています。ですので、絵文字を処理するということは、ほぼサロゲートペアの処理が必要になると思ってください。具体的な使い方を😝の絵文字で見ていきましょう。この絵文字のコードポイントはU+1F61Dです。これはU+10000を超えていますので、Java(Kotlin)のchar型に入りません。
val emoji = charArrayOf(0x1F61D) // これは無理そこで、代わりにサロゲートペアに分解された2つの数値を使います。
val emoji = charArrayOf('\uD83D', '\uDE1D') // これならOKなお、文字列として渡す場合もサロゲートペアにしないとダメです。
val emoji = “\uD83D\uDE1D”どうやって変換したの?って思ったあなた。当然計算式はあるのですが、直接その数式を使うことはほぼないので、APIで変換してください。
val emoji = charArrayOf(Character.highSurrogate(0x1F61D), Character.lowSurrogate(0x1F61D))逆にサロゲートペアからコードポイントを取得する際にはこちら
val codePoint = Character.toCodePoint('\uD83D', '\uD83D')白黒絵文字と異体字セレクタ
今でこそ絵文字はカラーで表示されるのが当たり前となっていますが、昔の絵文字は白黒でした。というより、そもそも絵文字以外の文字は白黒なので、カラーで表示される絵文字が特殊だと言えます。Unicodeに収録されている絵文字のいくつかは、古くから存在していたのですが、絵文字の普及によって、昔は白黒の記号だったものが絵文字にカテゴライズされたことによって、カラーで表示されるようになったものがあります。例えば、♂の記号は白黒ですが、♂️と表示されるかもしれません(環境によっては同じ文字に表示されるかもしれません)。しかし、Emoji属性になったからといって、ある日いきなり今まで白黒だったものをカラーで表示し始めたら困りますし、逆に最近の絵文字はほぼカラー前提で設計されており、白黒にするのが困難なものもあります(色違いのハートなど)。なのでUnicodeはデフォルトで白黒で表示すべきものと、デフォルトでカラーで表示すべきもののリストを持っています。
https://www.unicode.org/Public/UCD/latest/ucd/emoji/emoji-data.txt
ここに列挙されている、Emoji_Presentationという属性を持つ絵文字のリストは、デフォルトでカラーで表示されるべきであるとUnicodeが定めています。逆に言うと、ここに列挙されていなかったら白黒で表示すべきだと言っています。なお、「表示すべき」と言ってはいますが、Androidはこれに完全に準拠しているわけではなく、歴史的経緯や、白黒のグリフが無いなどの理由から、いくつかの絵文字はEmoji_Presentationの属性を持っていないにも関わらず、デフォルトで絵文字で表示されます。

デフォルトの挙動はUnicodeが指示してくれました。しかしユーザーとしては「やだ!カラーがいい!」とか「白黒で出してよ!」っていう方もいらっしゃるでしょう。Unicodeはそのようなカスタマイズ方法にも規格を定めています。そのうちで最もおすすめの方法は異体字セレクタを使ってカラーか白黒かを選択する方法です。
異体字セレクタ(Variation Selector、略してVS)とは、ざっくりいうと直前の文字の見た目を変えるために使用する特殊な文字のことです。この文字は日本語では積極的に利用されていて、例えば、日本全国にいる渡邉さんの「邉」の字形を変更するのに利用されています。Unicodeは数ある「邉」という字形を一個一個収録するのではなく、「邉」という字を登録して、その文字の異体字という形でたくさんの「邉」を収録しました。具体的には、「邉」の後ろにU+E0104などの文字をくっつけることで文字の形が変わります。

ちなみに、このU+E0104は前に説明したサロゲートペアで指定する必要があります。
val text = "\u9089\uDB40\uDD04: U+9089 U+E0104"さて、これがなぜこれが絵文字の白黒かカラーかの違いに関わってくるのかというと、「絵文字を白黒にする異体字セレクタ」と「絵文字をカラーにする異体字セレクタ」なるものをUnicodeが用意してくれているからです。U+FE0Eは「絵文字を白黒で表示してね」という異体字セレクタで、Text Presentation Selectorとか、異体字セレクタの番号をとってVS15とか呼ばれていたりします。逆にU+FE0Fは絵文字をカラーで表示してねという異体字セレクタで、Emoji Presentation SelectorとかVS16と呼ばれています。これらを絵文字の直後に置くことで白黒かカラーかを変更することができます。ただし、すべての絵文字について使用できるわけではありません。具体的にはこちらのリストにあるものにしか使用できません。
https://www.unicode.org/Public/UCD/latest/ucd/emoji/emoji-variation-sequences.txt
なぜかというと、最近追加されている絵文字は、基本的にカラーで表示することが前提のものがおおいからです。ですので、「新しい絵文字は基本カラー、古い絵文字やごく一部の絵文字だけ白黒で表示可能」と思っていただけたらと思います。例えばUnicode15で収録された「ブルーのハート」があるのですが、白黒で表示したら・・・いやできると思いますよ。でもねぇ、きっと「ピンクのハート」や「イエローのハート」と区別できないと思うんですよね。なので、白黒で用途がありそうなものだけのリストになっているんだとおもいます。ただ、Androidの内部実装の話をしますと、実は特にこのリストを参照しているわけではありません。VS15が指定されていたら、このリストを見ずに白黒で表示できるフォントを探しに行きます。そして見つかったらそれを使うという実装になっています。ですので、リストになくても白黒で表示できるフォントがあれば表示されるはずですし、逆に上記のリストに入っていても、デバイスの中に白黒で表示するためのフォントが存在しないため、VS15が効かない絵文字も多数あります。ちなみにですが、後ほど説明するシーケンス絵文字は基本的には全部カラーです。
実用上は、今説明した絵文字一つ一つに異体字セレクタをつけて回るのが一番確実だと思います。ですがUnicodeは他にも言語設定で白黒カラーの表示を変更できる仕組みを規格化しています。ここからは「絵文字用の言語設定とはなんぞや?」と思った方のために簡単に説明しますが、ちょっと複雑な話になりますので言語設定に興味がない方はスキップしてください。
Unicodeは言語設定に絵文字の白黒かカラーを指定できる規格をつくりました。「言語設定」と書くとややこしいのですが、正確にはロケール設定(Locale Setting)とでも言うのでしょうか、Localeに相当する日本語訳がわからなかったので、ここでは言語設定と訳しています。 現在は言語設定にはBCP47というフォーマットを利用するのが一般的です。(どうでもいいことなんですけど、仕事の書類などでAKB48に引っ張られて、何度かBCP48と書いてしまったことがあります。ほんとうにどうでもいいな。)言語設定の話を始めるとそれだけで何十ページもかけてしまうので、とりあえず今回は絵文字に関するところだけ説明します。BCP47は(狭義の)言語、文字体系、地域、拡張の識別子をハイフンでつなげた形をしています。例えば日本語だと
ja-Jpan-JP
という具合になります。最初の”ja”が言語としての日本語、次の”Jpan”が文字体系としての日本語、最後の”JP”が地域としての日本という意味で、拡張は指定していないのでありません。言語等から類推可能な場合は省略する場合もあります。例えば日本語だと通常日本語の文字体系なので”Jpan”を省略して
ja-JP
と表記することが可能で、このような表記をよく見かけると思います。文字体系とは、言語としては同じでも違う文字体系を使っている人々がいるので、それを区別するために必要な概念です。例えば中国語(zh)には簡体字(Hans)と繁体字(Hant)があるので、それを区別するために以下のようになります。
zh-Hans-CN
zh-Hant-TW
1個目は中国語で簡体字の中国本土のロケールを表します。2個目は中国語で繁体字の台湾のロケールを表します。中国語の場合は地域から文字体系を推測することは可能なのですが、セルビア語(sr)のようにラテン文字(sr-Latn)とキリル文字(sr-Cyrl)の両方が同一の地域で同一の言語で使用されているケースでは、文字体系なしでは区別できません。このように、この文字体系は使用している文字を区別するのに非常に重要な情報です。そしてこの文字体系の中に絵文字(Zsye)と記号(Zsym)という規格が存在します。Androidだとこんな感じでつかうことができます。
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:textSize="64sp"
android:textLocale="ja-Zsye-JP"
android:text="\u231B\u2708"
/>
さて、絵文字と白黒を文字体系で変更することができましたが、現実ではこれは困りますよね。だって絵文字の白黒カラーの指定に文字体系をつかってしまったら、他の用途に使えないです。なので、Unicodeは文字体系を使わずに白黒カラーを指定できるためのUnicode拡張を用意しました。
ja-Jpan-JP-u-em-emoji
ja-Jpan-JP-u-em-text
ja-Jpan-JP-u-em-default
上から、「日本語で、絵文字はカラーで表示する」「日本語で、絵文字は白黒で」「日本語で、絵文字はデフォルトで」を表すロケールです。これを同じようにロケール設定に食べさせてあげると以下のようになります。

さてここで注意力のある方は「文字体系と拡張が逆の指示をしたらどうなるの?」と思ったでしょう。私の記憶が正しければ、Unicodeは何も言ってなかったと思います。なのでどうなってもいいと思うのですが、確かAndroidの実装は拡張のほうを優先しているはずです。というかそんな設定しないでください。
ずっと長々と説明してきましたが、個人的にはこの方法はあまりおすすめしません。なぜなら、頑張って実装したのでAndroidだと動きますが、他のプラットフォームでは動くのか不明ですし、優先順位としては先に見たVariation Selectorが優先されます。文字列のなかにカラー白黒の情報が入っているので、コピペしても同じ表示になることが期待できます。さらに、昨今の言語設定は複雑で、Androidは複数の言語を優先付けして設定できたり、数字やカレンダーの拡張なども言語設定に組み込むことができるようになっています。ですので、下手にいじるとスペルチェッカーのような言語に依存している他の機能を壊す恐れがあります。なるべく言語はユーザーがシステムで設定した値をそのまま使ったほうが良いです。というわけで、白黒カラーを切り替えたかったら異体字セレクタを使ってください。
シーケンス絵文字
これまで絵文字を見てきましたが、そのほとんどは1コードポイントで一つの絵文字を表していました。ですが近年、新たに追加されている絵文字の大部分はシーケンス絵文字とでもいいますか、複数のコードポイントを結合して一つの絵文字とするタイプの絵文字です。今後そのような絵文字をシーケンス絵文字と読んでいきます。シーケンス絵文字は結合に使用する文字種などの違いから、いくつかのグループに分かれています。
みなさんはもしかすると、「文字を結合する」と聞くと、ぎょっとするかもしれません。これから見ていく絵文字はちょっとアグレッシブすぎるかもしれませんが、文字を結合するという手法自体は、日本語を含めていろんな言語で一般的に使われています。例えば先に見た異体字セレクタも複数文字で一文字を表す例です。ほかにも日本語では「が(U+304C)」を一文字で表すこともできれば、「か(U+304B)」と濁点「゛(U+3099)」の二文字を合成した「が」で表すこともできます。これも複数コードポイントから一文字を作っている例となります。実際Mac OSXのファイルシステムなどでは「が」を2コードポイントに統一して保存しており(NFD正規化と言います)、WindowsやLinuxのファイルシステムではそんなこと気にしないで保存しているので、たまにMac OSXとファイルを共有して、開けなくなるトラブルになったりしてますね。この辺はあまり深入りすると戻ってこれなくなりそうなので、ここまでにすることにします。興味がある方はUnicode正規化で調べてみてください。
絵文字シーケンスに正規化という概念はないのですが、複数のコードポイントで一文字を表すという試み自体は同じコンセプトですので、なんとなくイメージを掴んでもらえると、これから紹介していくシーケンス絵文字を理解しやすいかもしれません。
さて、シーケンス絵文字を見ていく前に一つ注意していただきたいことがあります。これから見ていくシーケンス絵文字は割と自由です。やりたい放題です。「人」の絵文字を「ハート」と「キスマーク」で連結させて、「キスしてる絵文字」にしちゃうくらいやりたい放題です。なので「俺は猫が好きだから、「猫」と「人」の絵文字で「猫とキスする人」の絵文字を作っちゃえ!」って思う人がでてくるかもしれません。実際今後Unicodeに猫信者がたくさん入信して猫と人間、猫同士のキスの絵文字ができるかもしれません。ですが少なくとも現状ではUnicodeのデータベースにそんな絵文字は存在しません(残念!)。なのでシーケンス絵文字には多数の「Unicodeのコードポイント列としては正しいが、Unicodeはそのシーケンスを絵文字として収録していない」というようなものが多数存在することになります。実際に過去にはMicrosoftが「猫」と「忍者」の絵文字を合成して「Ninja Cat」なる絵文字を独自にWindowsに入れていた過去があります。私はMicrosoftとはなんだか馬が合いそうな気がします。でもWindows 11で居なくなったみたいなんですよねぇ、残念です。このNinja Catの絵文字ですが、当然Unicodeには収録されていません。このような各プラットフォームベンダーが独自に追加している絵文字は他のプラットフォームでは表示されません。そこでUnicodeはこのような野良絵文字が氾濫すると思い、RGIという概念を導入しました。このRGIとはRecommended for General Interchangeのことで、プラットフォームの互換性のためにサポートするのが望ましい絵文字のことを指します。なんのことはない、Unicodeに収録されている絵文字のことです。逆に言うとRGIではないシーケンス絵文字は、Unicodeの管轄外なので表示されなくても知らないし、どう表示されるかもわからないから、自己責任でやってねということですね。なおこの記事のなかに出てくる絵文字の例はすべてRGIになっています。
ではシーケンス絵文字の各グループについて見ていきましょう。
キーキャップ
キーキャップ(U+203E)と呼ばれる特殊な文字があります。キーキャップとはキーボードのスイッチの上に乗っかっているプラスチックの部品のことです。雑に言うとパソコンのキーボードのキーです。キーキャップを数字の後ろにつけるとボタンみたいな絵文字になります。パソコンのキーボードのキーなのですが、テンキー部分しかありません。電話機のボタンを表現したかったのかな?
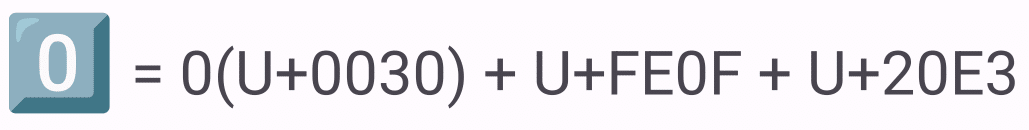
モディファイヤーシーケンス
モディファイヤーとは日本語に訳すと「修飾子」、つまり飾り付けるものを意味します。Unicodeは今の所、この飾り付けるためのコードポイントとして、肌の色のみが収録されています。この肌の色の絵文字は合成文字のカテゴリーに属しており、日本語の濁点やラテン語圏のアクセント記号と同じ分類になります。ですので基本的に単独での使用は想定されていません。これとは対照的に、似たような用途で「髪の毛の色を変える」絵文字があるのですが、それは合成文字のカテゴリーに入っていません。後ほど見ていきますが髪の色はZWJという「結合しますよ」という特殊な文字と一緒に使用することで結合します。おそらくUnicodeの方針としては、「シーケンス絵文字はなるべくZWJで結合させる」という方針なのでしょう。なので今後肌の色以外の修飾子が増えていくことはないんじゃないかなぁと予想しています。
肌の色を変更する絵文字は現在のところ五種類収録されていて、人に関連する絵文字の後ろにつけることができて肌の色を変更することが可能です。
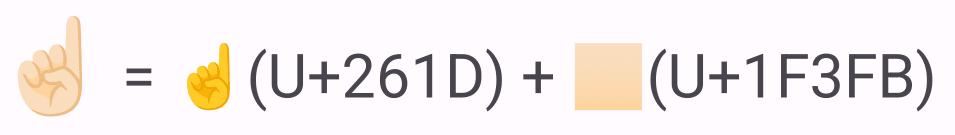
旗シーケンス
絵文字には旗の絵文字も多数収録されています。個人的にはこの規格は非常に困ったちゃんなのですが、それは後ほど「絵文字と文字数」のセクションで説明したいと思います。旗シーケンス(Flag Sequence)と書いてありますが、国旗です。なんで国旗と書かないのか・・・色々あるみたいです。具体的な実装方法としては、旗専用のアルファベットが定義されていて、それで二文字の国コード(ISO3166)を作ってその国の旗を表しています。この旗専用のアルファベットをRegional Indicator (RI)と呼びます。例えば日本の場合二文字の国コードはJPなので、Jに相当するRIはU+1F1EF、Pに相当するRIはU+1F1F5なのでこれら2つで日本の国旗になります。

ちなみに、表示すべき旗がない場合は「どこの国かわからないよ〜?」を示す旗を表示させることが期待されています。
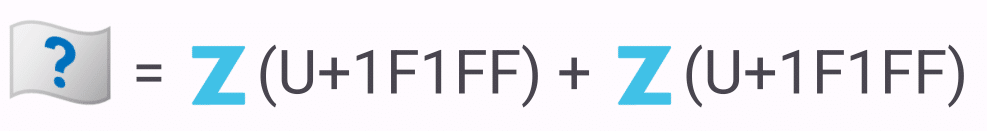
愚痴なのですが、これはプラットフォーム的には地味にめんどくさいんですよね。「対応するグリフがない場合はTofuを表示する」という一般的な挙動から外れてるので、「この文字を表示できますか?」というAPIに対しての例外処理に相当するんです。「どこの国かわからない用の旗」のグリフは存在しており、それを表示しているが、それは指定された文字列が表示できている訳ではない、というややこしい状態になります。
余談ですが、Unicodeはもう旗の絵文字を増やす気はないと声明を出しました。なのでこれ以上旗が増えることはないでしょう。(国が増えたら自動的に追加される言ってるので、国が増えない限りは増えないのかな?)
タグシーケンス
タグシーケンスとは絵文字タグという特別な専用アルファベットを使って、絵文字に意味を与えるシーケンスのことを言います。現在のところイギリスの地方を表す旗のみがRGIに登録されていますが、先程の旗シーケンスで見たように、もうUnicodeは旗の絵文字を増やす気はないみたいなので、旗に関してはこの三つでこれ以上増えることはないでしょう。ただ、このタグシーケンスはもっとやりたい放題できる仕様になっています。現在の規格からは削除されていますが、過去のドラフトにはこれを使った「俺の考えた最強の絵文字エンコード」みたいな規格が提案された過去がありました。例えば「走っている人の絵文字を、金髪にして左に向かって走っている絵文字にする」みたいなエンコードが考えられていました。さすがにアグレッシブすぎたと思ったのか、結局規格にもRGIにも入っておらず、タグのコードポイントだけが今も残っている感じですかね。諸行無常、兵どもが夢の跡という感じです。
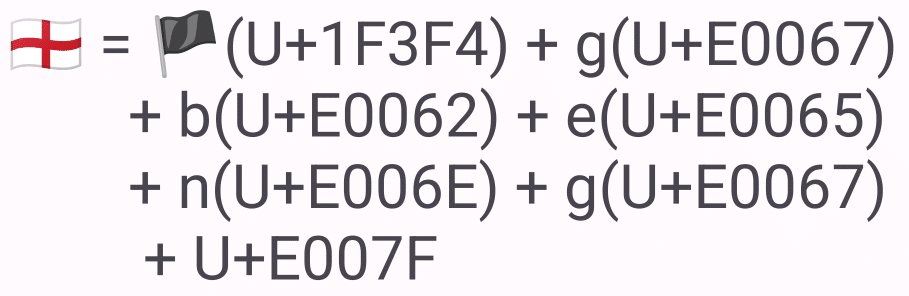
ZWJシーケンス
これまで見てきた絵文字シーケンスたちは、言ってしまえばUnicodeが黎明期に試行錯誤していた残り香のようなもので、これから見ていくZWJシーケンスたちが現在の絵文字の主流となっています。実際、Unicode 15で収録された絵文字のうち、新規のコードポイントに伴う肌のバリエーション以外はすべてZWJシーケンスです。旗やタグシーケンスは追加されていません。Unicode 15.1に至っては、新規に追加された絵文字はすべてZWJシーケンスです。
これまで断りなくZWJ(U+200D)を使ってきましたが、これはZero Width Joinerの略で、日本語に無理やり訳すと、「幅ゼロの結合子」を意味します。簡単に言うと、両隣を結合させるための幅ゼロの文字です。このZWJですが、基本的に絵文字っぽい2つの文字をくっつけられます。きっとある日Unicodeは思いついちゃったんでしょう。「ヤバイ、絵文字のバリエーションめっちゃ増えてる。このままやと空いてる領域を食いつぶしてしまう。せや!2つの絵文字をZWJでくっつけて一つの絵文字にしたら少ないコードポイントでいろんな表現ができるやん!」と。まぁそうなのですが、ほんとに規格にしちゃうあたりすごいなぁと思います。実際際限なくコードポイントを消費しつくされるよりはマシかもしれません。100万個追加であるとはいえ、限りはありますからね。かくして絵文字たちはZWJで無理やり悪魔合体させられるのでありました。
ZWJを使った合成ですが、前述のモディファイヤーシーケンスとの合わせ技になることもあります。構造としては、まず絵文字のコアとなるシーケンスというものが定義されています。具体的には、単一の絵文字コードポイント、絵文字と異体字セレクタのペア、モディファイヤーシーケンスはすべて絵文字のコアシーケンスとなりえます。そしてそれらのコアシーケンスをZWJでつなぐことができるとされています。
つまり、
{単一絵文字コードポイント} ZWJ {単一絵文字コードポイント}
{単一絵文字コードポイント} ZWJ {絵文字と異体字セレクタのペア}
{絵文字と異体字セレクタ} ZWJ {モディファイヤーシーケンス} ZWJ {絵文字と異体字セレクタのペア}
はすべて合法なZWJシーケンスとなります。逆に
{単一絵文字コードポイント} ZWJ {異体字セレクタ}
{単一絵文字コードポイント} ZWJ {単一モディファイヤー}
{単一絵文字コードポイント} ZWJ {ひらがな}
{単一絵文字コードポイント} ZWJ
みたいなのはZWJの両端でつないでいるものが絵文字のコアシーケンスではないので、違法なZWJシーケンスとなります。

ちなみに、ZWJは絵文字用に開発されたものではなく、昔から存在しており、主にアラビア語のように、文字が繋がっているかどうかで文字の形状が変わる言語で使用されてきました。なので、逆の意味のZWNJ、Zero Width Non Joinerなる「幅ゼロの非結合子」なんて文字もあります。これを使うと「この文字の両端で結合しないで!」という意味になりますが、今の所絵文字での用途はありません。
絵文字と文字数
これまで絵文字の構造について説明してきました。絵文字は単一のコードポイントであるほうがもはや珍しく、基本的には複数のコードポイントが結合されて一つの絵文字となっていることを見てきました。こうなってくると、単一コードポイントのときは意識しなかった問題がいくつか浮上してきます。一番最初に思いつく問題としては、「絵文字を含んだ文字列の文字数はいくつなのか?」という問題です。そもそも「文字数」や「文字の長さ」というもの自体が曖昧なものなので、そこから定義して話をしないといけないのですが、それを話し始めると、それも長大な文章になりそうなので、ここでは文字数として以下の2つの指標を考えてることにします。
コードポイント数
グラフィムクラスタ数
コードポイント数とは文字通り与えられた文字列に含まれているコードポイントの数です。直感的にはこれを文字数として使えそうな気がしますよね。でも絵文字だとこの予想は簡単に裏切られます。例えば、😝だと1コードポイントなので良さそうですが、☝🏻だと指差しの絵文字とモディファイヤーで2コードポイントですし、長いのだと🧑🏻❤️💋🧑🏼は10コードポイントで構成されています。さすがにこの状況で、1コードポイントが1文字だという主張は直感に反してますよね。もしコードポイント数を文字数だとしてしまうと、🧑🏻❤️💋🧑🏼は10文字です。140文字制限だった某SNSだと「🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼」で文字数オーバーです。「🧑🏻❤️💋🧑🏼🧑🏻❤️💋🧑🏼」は「吾輩は猫である。名前はまだない。」よりも長い文字列ですと言われたら、違和感バリバリですね。なのでコードポイント数は我々の思う文字数とは違うのです。ちなみに、このキスの絵文字、現在のUnicode 15.1の環境では最長のシーケンス絵文字で、なんとUTF-16で保存すると、50bytesも使用します。UTF-8だと35bytes。1文字に50byte・・・贅沢ですね。
さて、コードポイントが文字数として直感に反しているということで、Unicodeがもっと人間の直感に近い文字の区切り方を発明してくれました。それがグラフィムクラスタです。日本語では書記素・・・でいいんですかね?Unicodeはグラフィムクラスタを以下のように説明しています。
These user-perceived characters are approximated by what is called a grapheme cluster, which can be determined programmatically.
直訳は「(前の文章を受けて)これらのユーザーが考える文字というのは、プログラムで決定されるグラフィムクラスタと呼ばれているもので近似されています。」となります。要は「グラフィムクラスタは大体ユーザーの考える1文字になってるはずだよ!」ってことです。このグラフィムクラスタを用いると、😝も☝🏻も🧑🏻❤️💋🧑🏼も1クラスタとなります。また、グラフィムクラスタはカーソルを置ける位置を計算するのにも使われているので、カーソルが置ける境界がグラフィムクラスタの境界、すなわち感覚的な文字の境界になっています。これがおそらく文字数として使うには最も良い指標でしょう。このグラフィムクラスタという概念は絵文字のみのものではなく、全言語に対して一般的に適用できる概念です。例えば先程見てきた異体字セレクタや日本語の濁点なんかもグラフィムクラスタを使用して直感的な文字数を取得することができます。

実際にグラフィムクラスタを計算するには、Unicodeの文字データベースから文字情報を引っ張ってきて、ごにょごにょする必要があるのですが、当然自力でやるモチベーションは現在では皆無なので、おとなしくAPIを呼んでください。以下のサンプルコードはグラフィムクラスターの境目に”|”を入れて出力するサンプルです。
val it = BreakIterator.getCharacterInstance()
it.setText(text)
var i = 0
var out = "|"
while (i != BreakIterator.DONE) {
val next = it.following(i)
if (next != BreakIterator.DONE) {
out += text.substring(i, next) + "|"
}
i = next
}
Log.d("Debug", "$out")かくして、文字数を数えるときはグラフィムクラスタを使えばよいということになりそうです。めでたしめでたし。
グラフィムクラスタの余談1:グラフィムクラスタの注意点
めでたしめでたしなのですが、万能に見えるグラフィムクラスタですが、いくつか注意すべき点があります。まず、グラフィムクラスタはUnicodeのデータベースに依存するということです。Unicodeは毎年新しいバージョンが出ます。そして新しい文字は当然新しいUnicodeのデータベースにしか存在しません。通常、UnicodeのデータベースはICU(International Component for Unicode)と呼ばれるライブラリを介して参照するので、同じ文字列をバージョンの違うICUでカウントすると別の文字数(グラフィムクラスタ数)になる、なんていうことが起こっていました。Androidで言えば、古いOSと新しいOSでは同じ文字列なのに文字数が違う!という現象が起こるわけです。ただ、これは昨今ではあまりおこらなくなってきています。なぜなら、Unicodeが、将来絵文字に割り当てるであろう領域を予め予約してExtended Pictographicという属性をつけたからです。現在の絵文字のセグメンテーションルールはそのExtended Pictographicという属性を参照する形で実装されていますので、新しい絵文字が予約されている領域に収録されている限り、古い実装でも問題なく動くことが期待できます。例えばマラカスの絵文字はUnicode 15で追加されましたが、当然ですがUnicode 14の時点ではマラカスは存在していません。ですが、マラカスのコードポイントU+1FA87はすでにExtended PictographicとしてUnicode 14に登録されていました。なので新しい絵文字マラカスが、古いUnicodeのデータベースを持つ環境でもあたかも最新の絵文字がサポートされているかのように動いてくれます。もっとも、グラフィムクラスタに関する挙動だけで、実際にはフォントが古けれマラカスではなくTofuが表示されているでしょう。
もう一つ、グラフィムクラスタを使う上で注意しておいたほうがいいことがあります。グラフィムクラスタはUnicodeのコードポイントからのみ決まる値であると説明しました。つまり、実際に表示されている文字の見た目を反映していないかもしれないのです。例えば、絵文字シーケンスは、表示ができなかった場合、フォールバックとして結合されていない状態の絵文字を表示します。例えばキスの絵文字の場合、古い絵文字フォントしかなくて、表示ができなかった場合、「🧑🏻❤️💋🧑🏼」の代わりに4つの絵文字「🧑🏻❤️💋🧑🏼」を出力します。これは見た目は4文字ですが、グラフィムクラスタはその定義上、フォントの状態など知らないので、1つだと主張するでしょう。実際、カーソルを置く位置の計算では、このフォールバックした絵文字であっても、一つの文字として扱います。なぜならそれは、たとえフォールバックした表記でも、そのシーケンスの途中にカーソルを置いてはならないとUnicodeの規格に定められているからです。でも直感的には1文字じゃないですよね。ちなみに逆の場合もあります。絵文字ではないですが、英語などではリガチャと呼ばれる、複数の文字をつなげたスタイルを使用することがあります。たとえば、”fi”の文字でiの点がfに吸収されたような字形を取ることがあります。
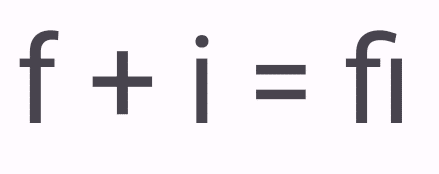
これはフォントの機能なので、コードポイントからだけでは判断ができません。”fi”の場合はリガチャになっても2文字だろうと思えるので良いのですが、世の中にはもっとアグレッシブなリガチャをするフォントがあります。プログラム用のフォントで”!=”を”≠”とリガチャしてしまうようなフォントもあります。”!=”と”≠”はさすがに文字数が変わってますよね。

正直、この状態になると、実際にプログラムを書いている人が要求事項に応じて文字数の定義を決め、それに合うような指標を選択しなければなりません。例えば、バックエンドサーバーが1024バイト分しか容量がなければコードポイントどころではなく、UTF-8なりUTF-16なりでエンコードした際のサイズが必要でしょう。ポリシー的理由で文字数制限が必要なのであれば、その趣旨に合わせてコードポイントかグラフィムクラスターかを決めてしまえば良いでしょう。画面上の幅の問題で文字数を制限する場合は、文字数なんてものは使わず、実際に測るのがよいでしょう。いずれにせよ、文字数まわりのプログラムを書く際に銀の弾丸は存在しないので、慎重な設計が要求される、非常に難しい問題です。
グラフィムクラスタの余談2:旗シーケンスの複雑さ
ここからの話はグラフィムクラスタの実装に踏み込んだマニアックな話なのでグラフィムクラスタの内部実装に興味がない方は次の節へスキップしてください。グラフィムクラスタの実装は、ある文字と文字の間が、その周辺の文字の属性を見て、グラフィムの「境界である」、「境界でない」というのを判定しています。例えば、モディファイヤシーケンスである、U+261D U+1F3FBの場合、後ろのU+1F3FBは合成文字の属性を持っているので、U+261DとU+1F3FBの間はグラフィムの境界ではない。というような判定を行います。

この例だと、モディファイヤーの前では切らず、モディファイヤーの後、通常絵文字の前で切っている。
通常は、ある場所が境界であるかどうかを見るためにはその境界の前後の文字をみるだけで十分なのですが、一個だけ例外があります。旗シーケンスです。
旗シーケンスは前で見たように2つで1セットの旗を作りますが、その2つの文字にはサロゲートペアのように「前専用の文字」や「後ろ専用の文字」のような違いがありません。ではどうやって2文字づつ旗にしているのかというと、実装上は前から2つづつ区切って旗の絵文字にしていきます。例えば、RIのJに相当する文字をと、Pに相当する文字をとして、

という文字列があった場合、テキストの描画エンジンは前から順番に

であると解釈して、日本の国旗を6個ならべます。ですが、これが行えるのは前から順番に処理をしているからです。グラフィム判定のように、ランダムな場所で「ここはグラフィム境界ですか?」という質問に応えようと思うと、指定された場所だけでは判定ができず、遡って最初まで行き、指定された場所から前に偶数個のRIがあった場合はグラフィム境界、奇数個のRIがあった場合はグラフィム境界ではない、という判定をせざるを得ません。これはつまり、最悪ケースで指定の位置がグラフィム境界であるかを判定するのにすべてのテキストを走査する必要があることを意味します。

なんでサロゲートペアみたいに1文字目と2文字目でグループを分けなかったのかとか、なんで間にZWJ入れなかったのかとか色々と後出しジャンケンはできますが、残念ながら今から変えることはできないので、ぐぬぬと言いながら実装しましょう。
Android Mの頃はこれに起因したおもしろバグもあったのですが、今となってはAndroid Mのデバイスを手に入れるのも大変でしょうし、他のプラットフォームも正しくハンドルしていて、なかなかお目にかかることもなくなってしまいましたね。嬉しいような寂しいような。なのでエミュレーターで実験して録画しておきました。
この例では、インドの国旗をしめすIとNが無数に繰り返されています。そして動画ではカーソル位置からデリートキーを何度も押しています。そうするとなぜかインドの国旗がニカラグアの国旗に変わってしまっています。中で何が起こっているのかを見ていきましょう。まず初期状態ではこのようなコードポイント列になっています。

ここで、描画エンジンは前から処理を行い、

このように、2個づつ区切ることで、IN、つまりインドの国旗を出力していました。
しかしここで、デリートキーを押すことで変なことが置きます。AndroidMのころのデリートキーの実装は1コードポイント消すというものだったので、ここでは最初のIのみを消してしまいました。その結果描画エンジンは

文字列をこのように解釈して、NIの国旗、ニカラグアの国旗を出力したというわけです。
AndroidはAndroid Nからグラフィムクラスタを認識して、デリートキーはちゃんと1グラフィムクラスタ分消すようになったので、このバグはもはや再現しなくなりました。Androidに限らず、最近のアプリケーションは正しく絵文字をハンドルできるものが多いので、このような珍妙なバグはもはやレアな存在となってしまいましたが、昔はUnicodeの実装が透けて見えるようなバグが結構見つかっていました。
絵文字とOSのバージョン
ここからはAndroid特有の問題について説明していきます。Androidは絵文字を当然サポートしていますが、サポート状況はOSによって異なります。そのなかで一番大きな問題は、最新の絵文字が表示されないという問題でしょう。古いOSで最新の絵文字を表示できないのは、システムにインストールされているフォントが古いのが原因です。ですがAndroidセキュリティの仕様、システムにインストールされているフォントファイルのアップデートは容易ではありません。フォントファイルはその性質上、ハイリスクなファイルであり、しかもシステム権限で動いているプロセスも文字を書くためにフォントを使う必要があります。ですので、システムにインストールされているフォントファイルには高い安全性が求められてきました。実際に、システムにインストールされているフォントファイルは、他のOSソフトウェアと同様にファイルの改ざん等がないことが常にチェックされ、安全であることが検証されています。しかしその反面、フォントファイルがシステムの一部であるがゆえ、それをアップデートするにはOSまるごとのアップデート以外不可能でした。ですので、Androidは長らく、OSのアップデートが終了した端末で最新の絵文字を表示することができませんでした。この問題はAndroid12以降では、新しいカーネルの機能を使うことでシステムにインストール済みのフォントファイルも更新できるようになって解決されました。しかし、いかんせん世界中のデバイスがAndroid 12になるまでにはまだ少し時間がかかります。ですので開発者の皆さんには、ぜひEmojiCompatの利用を検討してもらいたいです。EmojiCompatは最新の絵文字を古いOS、具体的にはAPI19以降のOSで表示させることが可能です。もしAppCompatをすでにお使いでしたら、自動的に使用されていますので安心ですが、使用されていない場合はぜひご一考ください。詳細については長くなりますので、こちらのページを参照してください
最新の絵文字状況
ここからは、絵文字のここ数年に起こった最新の情報をお届けしようと思います。
カラー絵文字フォント
まず近年、絵文字を表示する技術の中核となるカラーフォントに大きな変化がおきました。フォントファイルにはOpenTypeという規格があるのですが、そのOpenTypeのバージョン1.9が2021年の12月に出ました。このOpenType1.9から新しいカラーフォントのフォーマットであるCOLRv1が登場しました。そして実際にAndroidの13からこのCOLRv1のフォントが使用されるようになりました。
もともとカラーフォントの実装にはいくつかの規格があり、有名なところでは以下のようなものがあります。
CBDT/CBLC
CBDT/CBLCとはOpenTypeのフォントで使用されているテーブルの名前です。このフォーマットは主にGoogleの製品群で使用されており、実装は単純にPNGファイルが埋め込まれています。ほんとにPNGファイルがPNGファイルの構造そのまま埋め込まれています。昔、白黒フォントにもビットマップフォントという、ビットマップが直接埋め込まれたフォント形式がありました。それのカラー版ですね。特徴としては実装が容易な反面、フォントのファイルサイズが肥大化してしまうこと、拡大すると画質が荒くなってしまうなどの弱点があります。画像ファイルの宿命ですね。AndroidではAPI19からサポートされています。
COLR/CPAL
このフォーマットは主にMicrosftが使用していました。近年の白黒フォントと同じようにベクターデータの字形情報に加えて、指定色での塗りつぶしが行えるのが特徴でした。ただし、Version 0と呼ばれる初期のCOLR/CPALは単一色で塗りつぶしていくことができるだけの簡素なものでした。これがOpenType1.9にVersion 1として様々なグラフィックオペレーションがサポートされ、グラデーションによる塗りつぶしなども行えるようになりました。これに伴い、Androidで使用しているNotoColorEmojiもCOLRv1に移行し、API33からはプラットフォームがCOLRv1をサポートしたこともあり、システム標準の絵文字はこの形式のものになりました。
SVG
字形データとしてSVGが入っている形式です。あまり詳しくないのですが、<text>や<font>といったSVGの機能は使えないみたいです。そりゃそうですよね、フォントがフォントを呼び出すとか、何その無限ループになっちゃいます。
Unicode 15.1で追加予定の絵文字
次に、最新のUnicode 15.1の紹介をします。Unicodeは年に一度新しいバージョンをリリースしており、今年はUnicode15.1でした。Unicode 15.1には新しい単一コードポイントの絵文字は追加されず、118個のRGIのZWJシーケンスが追加されました。これを執筆しているのは12月2日なのですが、つい3日前の11月30日にUnicode 15.1で新規に追加された絵文字を収録したNotoColorEmojiがリリースされました。
https://github.com/googlefonts/noto-emoji/releases
大きな変更としては、絵文字の向いている方向を制御するための仕組みが入ったことでしょうか。ただ、方向の制御と言っても、標準で左を向いている絵文字を右向きシンボル➡(U+27a1)とZWJで引っ付けて別の絵文字にしているだけです。それに伴って108個のRGI ZWJシーケンスが追加されているので、真新しい絵文字は実質10個ほどということになります。いくつかピックアップしてみましょう。




興味を惹いたのは、ライムを単一のコードポイントにしないで、「レモン」と「緑の四角」の絵文字のZWJシーケンスとしたことくらいですね。「緑のレモンはライムなのか?」という論争が起きそうです。しかし、これだけアグレッシブにZWJシーケンスを使っているところを見ると、新しいコードポイントはなるべく避けたいというポリシーが見え隠れしていますね。
終わりに
最後に私が昨今の絵文字事情について思うことの雑感を述べさせていただきたいなと思います。私は絵文字がカラーになり始めた頃から絵文字関連の仕事をしておりますが、その頃はほぼ毎年絵文字に関するアップデートがあり、毎年実装の変更やバグの修正を行っていました。その頃に比べると、最近ではUnicodeの規格に振り回されるという機会はほぼなくなってきたように感じます。それだけ絵文字の規格が安定しており、成熟してきたのかなという気がしてきています。ただ、規格としては安定していても、毎年毎年新しい絵文字が登場しますし、COLRv1のような新しい技術も登場してきています。絵文字はこれからもまだまだ進化をしていくとは思いますが、黎明期のドタバタしていた頃からは一段ステージが変わったような感覚があります。次に絵文字の革命が起こるとしたら何でしょうかね。絵文字がアニメーションするようになるかな?ユーザーが自分で作った絵文字が使えるようになるかな?数万個の絵文字が突然増えるようなことがあるのかな?正直予想がつきませんね。これからの絵文字の未来はどうなるんでしょう。楽しみでもあり、私の仕事が増えそうで、困ってしまいそうでもあります。
それでは2万字を超える長文に付き合っていただいてありがとうございます。最後に私が気に入っている絵文字を紹介して終わりにしたいと思います。みなさんのお気に入りの絵文字はなんですか?私は以下の3つの絵文字がお気に入りです。
📛:UnicodeではName Badge(名札)という名前で登録されています。日本人には、幼稚園児がつけるチューリップの名札であると瞬時にわかります。しかし海外では馴染みがなく、この見た目から「Tofu on fire(火に焚べられている豆腐)」と呼ばれているとかなんとか。私がまだアメリカにいた頃、日本人の同僚が日本に一時帰国して、お土産にこの名札を買ってチームへのプレゼントにしていたのを思い出します。
🦙:リャマの絵文字です。アルパカの絵文字でもあります。え?何言ってるのかって?Unicodeのプロポーザルには、「親戚みたいなもんだし、この絵文字はリャマ、アルパカを指すことにします」、って書いてあるんですよ。実際CLDRにはこの絵文字のキーワードとしてリャマとアルパカが登録されています。なかなか思い切ったことをするなと思った記憶があります。とはいえ、実際は他の絵文字にも近いものはあったりします。バイソンの絵文字のキーワードとしてバッファローが登録されていたり、かと思ったらトラとヒョウが別の登録だったり。Unicodeのカオスっぷりが伺える絵文字となっております。
https://www.unicode.org/L2/L2017/17266-llama-emoji.pdf
🍔:ハンバーガーの絵文字。Googleでは色んな意味で有名な絵文字です。
Will drop everything else we are doing and address on Monday:) if folks can agree on the correct way to do this! https://t.co/dXRuZnX1Ag
— Sundar Pichai (@sundarpichai) October 29, 2017
それではみなさん、よい絵文字ライフを!
参考文献
Unicode UTS#51
Unicode絵文字の規格を読むならこれ。ここに書いた内容はだいたいこれに全部書いてあります。
Unicode UAX#29
Unicodeのセグメンテーションルールが書かれています。グラフィムクラスタの計算方法や改行位置の計算方法が載っています。
Unicode Character Database
Unicodeの文字情報のデータベースがWebからアクセスできます。
Unicode 15.1 Emoji Release Note
Unicode 15.1で追加された絵文字の概要が見られます