
【最新AIニュースをお届け】Qwen2.5-Max:大規模 MoE モデルの知能を探る

ポイント
Qwen2.5-Maxは、20兆トークン以上のデータと高度な後処理トレーニング手法を活用した超大規模MoEモデル。
業界主要モデル(DeepSeek V3、GPT-4o、Claude-3.5-Sonnetなど)と比較し、多くのベンチマーク(Arena-Hard、LiveBench、LiveCodeBenchなど)で優れた性能を発揮。
オープンソースのベースモデル比較でも、DeepSeek V3やLlama-3.1-405Bを上回る結果を示した。
Qwen ChatやAPI経由で利用可能で、APIはOpenAI APIと互換性あり。
今後はスケーリング技術と強化学習への投資を進め、人間を超える知能の実現を目指す。
本文
かつて、データ規模やモデルパラメータの規模を継続的に拡大することが、汎用人工知能(AGI)への可能な道の一つであるという見解が存在していた。しかし、大規模モデルのコミュニティ全体では、超大規模なモデルのトレーニング(密結合モデルやMoEモデルのいずれも含む)に関する経験が相対的に不足しているのが現状である。最近では、DeepSeek V3 の発表により、超大規模なMoEモデルの効果と実現方法が明らかになった。一方で、Qwenも超大規模MoEモデル「Qwen2.5-Max」の開発を進めており、20兆トークンを超えるプレトレーニングデータと慎重に設計された後処理トレーニング手法を用いてトレーニングを行っている。本日は、Qwen2.5-Maxが現在達成している成果を共有できることを非常に喜ばしく思う。APIを通じてアクセスしたり、Qwen Chatにログインして体験することが可能である。
Qwen2.5-Maxの性能評価
私たちは、業界をリードするモデル(オープンソース・クローズドソースを問わず)とQwen2.5-Maxを、広く注目されている一連のベンチマークテストで比較評価した。これらのベンチマークには、大学レベルの知識をテストするMMLU-Pro、プログラミング能力を評価するLiveCodeBench、包括的な能力を評価するLiveBench、そして人間の嗜好に近い評価を行うArena-Hardが含まれている。評価結果は、ベースモデルとインストラクションモデルの性能スコアを網羅している。
インストラクションモデルの比較
まず、インストラクションモデル(ユーザーと直接対話可能なモデル)の性能を比較した。Qwen2.5-Maxは、DeepSeek V3、GPT-4o、Claude-3.5-Sonnetといった業界を代表するモデルと比較された。その結果、Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamondなどのベンチマークテストで、Qwen2.5-MaxはDeepSeek V3を上回る性能を示した。また、MMLU-Proなどの他の評価でも非常に競争力のある成績を収めた。
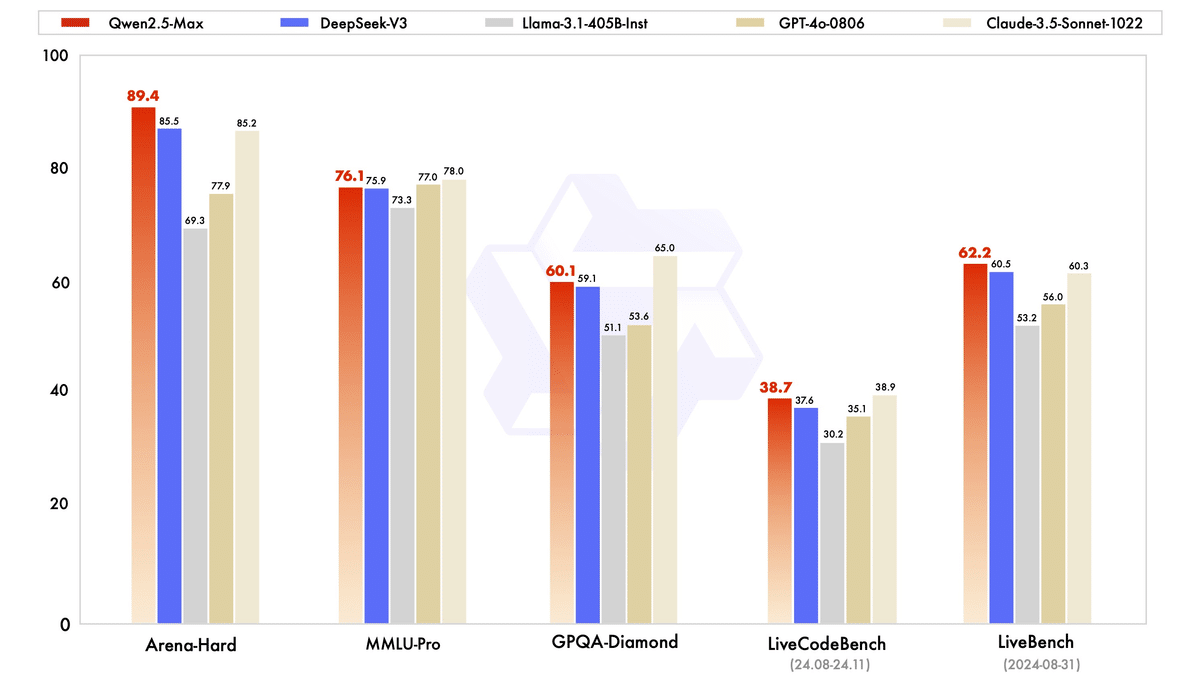
ベースモデルの比較
ベースモデルの比較においては、GPT-4oやClaude-3.5-Sonnetなどのクローズドソースモデルのベースモデルにアクセスできないため、Qwen2.5-Maxを現在のオープンソースの主力MoEモデルであるDeepSeek V3、最大のオープンソース密結合モデルであるLlama-3.1-405B、そして同じくオープンソース密結合モデルのトップに位置するQwen2.5-72Bと比較した。その結果は以下の図に示されている。私たちのベースモデルは、多くのベンチマークで顕著な優位性を示した。後処理トレーニング技術がさらに進歩することで、次のバージョンのQwen2.5-Maxがさらに高いレベルに達するだろうと期待されている。

Qwen2.5-Maxの利用方法
現在、Qwen ChatでQwen2.5-Maxを使用してモデルと直接対話したり、artifactsや検索機能を利用することができる。
Qwen2.5-MaxのAPI(モデル名:qwen-max-2025-01-25)も公開されている。阿里雲(Alibaba Cloud)のアカウントを登録し、阿里雲の大規模モデルサービスプラットフォームを有効化した後、コンソールでAPIキーを作成する必要がある。QwenのAPIはOpenAI APIと互換性があるため、OpenAI APIを利用する際の通常の方法で呼び出しが可能である。以下にPythonを使用したQwen2.5-Maxの呼び出し例を示す。
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-max-2025-01-25",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Which number is larger, 9.11 or 9.8?'}
]
)
print(completion.choices[0].message)今後の展望
データ規模とモデルパラメータの規模を拡大することは、モデルの知能レベルを効果的に向上させる手段であることが示されている。今後は、プレトレーニングにおけるスケーリングの継続的な探求に加えて、強化学習のスケーリングにも大きく投資し、人間を超える知能の実現を目指す。これにより、AIが未知の領域を探求する力をさらに高めたいと考えている。
もしQwen2.5が役立つと感じられた場合、以下の論文を引用してほしい。
@article{qwen25,
title={Qwen2.5 technical report},
author={Qwen Team},
journal={arXiv preprint arXiv:2412.15115},
year={2024}
}元記事
https://qwenlm.github.io/zh/blog/qwen2.5-max/