
#31 Wx、Eyの再計算、推計値と統計値の再比較

#30で、移輸入や移輸出、消費や固定資本、在庫を考慮に入れていないことが判明しました。
今回は、上記の項目を考慮に入れて、最適化する前の段階、つまり、重量単価初期値における推計値と統計値の比較を再度行います。
x産業の廃棄物発生量Wxを推計(ver2.0)
産業連関表の金額フローを物質フローに変換し、廃棄物発生量Wxを推計しました。
投稿#30にて、産業を1つに固定して算出した例を紹介しましたが、今回は全187産業において廃棄物発生量Wxを算出しました。
for x in range(len(df_price_per_ton.index)):
# 投入量を計算
input = 0 # 投入分
output = 0 # 産出分
fuel = 0 # 燃料使用分
waste = 0 # 廃棄物発生量
from_other_industry = 0 # 他産業からの投入
same_industry = 0 # 同産業
to_other_industry = 0 # 他産業への産出
iyunyu = 0 # 移輸入
iyushutsu = 0 # 移輸出
consume = 0 # 消費
fixed_capital = 0 # 固定資本
stock = 0 # 在庫
Ux = df_price_per_ton.iat[x, 0]
xcode = df_price_per_ton.index[x]
for i in range(187):
for k in range(len(df_price_per_ton.index)):
Ui = df_price_per_ton.iat[k, 0]
if df_price_per_ton.index[k] == '0131': # 0131(農業サービス)からの投入は考慮しない
continue
if df_price_per_ton.index[k] == df_iotable.index[i]:
from_other_industry += df_iotable.iat[i, x] * 1000000 // Ui
# 燃料使用分を計算
if df_price_per_ton.index[k] == '2121': # 石炭製品の燃料使用分
fuel += df_iotable.iat[i, x] * 1000000 // Ui
# 石油化学系基礎製品への石油製品の投入ではない場合
if df_price_per_ton.index[k] == '2111':
if df_iotable.columns[x] != '2031':
fuel += df_iotable.iat[i, x] * 1000000 // Ui # 石油製品の燃料使用分
# 産出量を計算
if df_price_per_ton.index[x] == '0131': # 0131(農業サービス)の産出は考慮しない
output = 0
same_industry = 0
to_other_industry = 0
consume = 0
fixed_capital = 0
stock = 0
iyushutsu = 0
iyunyu = 0
else:
for i in range(187):
if i == x:
same_industry = df_iotable.iat[x, i] * 1000000 // Ux
else:
to_other_industry += df_iotable.iat[x, i] * 1000000 // Ux
ctuple = ('7111', '7211','7212', '7311', '7321')
for c in ctuple:
consume += df_iotable.loc[xcode, c] * 1000000 // Ux
ftuple = ('7411', '7511')
for f in ftuple:
fixed_capital += df_iotable.loc[xcode, f] * 1000000 // Ux
stock = df_iotable.loc[xcode, '7611'] * 1000000 // Ux
iyushutsu = df_iotable.loc[xcode, '8100'] * 1000000 // Ux
iyunyu = -(df_iotable.loc[xcode, '8700']) * 1000000 // Ux
input = from_other_industry + iyunyu
output = same_industry + to_other_industry + iyushutsu + consume + fixed_capital + stock
waste = input - output - fuel
# 計算結果をdf_estimateに格納
df_estimate.iat[x, 0] = int(waste)
df_estimate.iat[x, 1] = int(input)
df_estimate.iat[x, 2] = int(output)
df_estimate.iat[x, 3] = int(fuel)
df_estimate.head(n=10)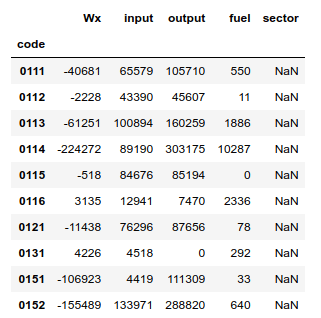
重量単価初期値における推計値と統計値の比較表作成
続いて、産業連関表の187分類の廃棄物発生量Wxを、廃棄物実態調査の28分類Eyに対応させて、統計値Syと比較する表を作成しました。
df_before_compare = df_statistics.copy()
df_before_compare['input'] = 0
df_before_compare['output'] = 0
df_before_compare['fuel'] = 0
df_before_compare['Ey'] = 0
df_before_compare = df_before_compare[['input', 'output', 'fuel', 'Ey', 'Sy']]
for i in range(len(df_before_compare)):
for sector, group in df_estimate.groupby('sector'):
if sector == df_before_compare.index[i]:
df_before_compare.iat[i, 0] = group['input'].sum()
df_before_compare.iat[i, 1] = group['output'].sum()
df_before_compare.iat[i, 2] = group['fuel'].sum()
df_before_compare.iat[i, 3] = group['Wx'].sum()
df_before_comparedf_before_compareをcsv形式で書き出して、列名を加工して一覧表にしてみました。

12業種で、推計値が負の値となっています。その中でも、化学、飲料・飼料、はん用機器が大きくずれています。
重量単価初期値における推計値と統計値の相関
重量単価初期値における推計値と統計値の相関を示すと、以下のようになります。以下のグラフは0以下の値は考慮していません。相関係数は、0.461となりました。

いいなと思ったら応援しよう!
