
『Python実践データ分析100本ノック』ノック31〜35

今回は、『Python実践データ分析100本ノック』で学んだことをアウトプットします。
クラスタリングで顧客をグループ化する
顧客の月内利用履歴に関するデータであるmean、median、max、min、membership_periodをクラスタリングの変数に用いることにします。
標準化
「mean、median、max、min」と「membership_period」ではデータが大きく異なり、前者は、月内の利用回数なので、1〜8程度ですが、後者は最大値が47となっています。
その場合、membership_periodに引っ張られてしまうので、標準化という手順が必要となります。
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
customer_clustering_sc = sc.fit_transform(customer_clustering)
kmeans = KMeans(n_clusters=4, random_state=0)
clusters = kmeans.fit(customer_clustering_sc)
customer_clustering['cluster'] = clusters.labels_
print(customer_clustering['cluster'].unique())
customer_clustering.head()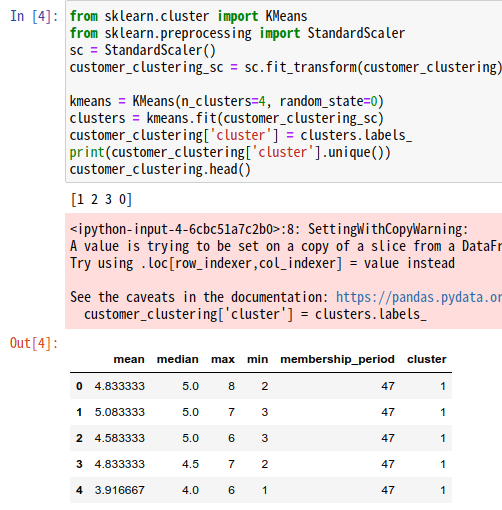
1,2行目でK-means法や標準化を使用するために、scikit-learnというライブラリをインポートしています。
3,4行目は標準化を実行。
標準化はscikit-learnで実装されていて、StandardScalerを用います。
まず3行目で、標準化器を作成しています。
続く4行目で、標準化を行い、customer_clustring_scに格納しています。
クラスタリング実行
空行を挟んで、K-meansのモデル構築を行っています。
まず、クラスタ数に4を指定し、作成するモデル定義を行います。引数のrandom_stateは、乱数のシードを固定する場合に指定します。
その後、データを代入し、実際にクラスタリングを実行(モデル構築)しています。
最後に、もとのデータ(customer_clustring)にクラスタリング結果を反映させています。
0〜3の4つのグループが作成されており、先頭5行の結果のように、各顧客データにグループが割り振られているのが確認できます。
クラスタリング結果を可視化する
今回、クラスタリングに使用した変数は5つでした。5つの変数を二次元上にプロットする場合、次元削除を行います。
次元削除とは、教師なし学習の一種で、情報をなるべく失わないように変数を削減して、新しい軸を作り出すことです。これによって、5つの変数を2つの変数で表現することができ、グラフ化することが可能となります。
ここでは、主成分分析という手法を用います。
主成分分析を行う際にも、標準化したデータを用います。
from sklearn.decomposition import PCA
X = customer_clustering_sc
pca = PCA(n_components=2)
pca.fit(X)
x_pca = pca.transform(X)
pca_df = pd.DataFrame(x_pca)
pca_df['cluster'] = customer_clustering['cluster']import matplotlib.pyplot as plt
%matplotlib inline
for i in customer_clustering['cluster'].unique():
tmp = pca_df.loc[pca_df['cluster'] == i]
plt.scatter(tmp[0], tmp[1])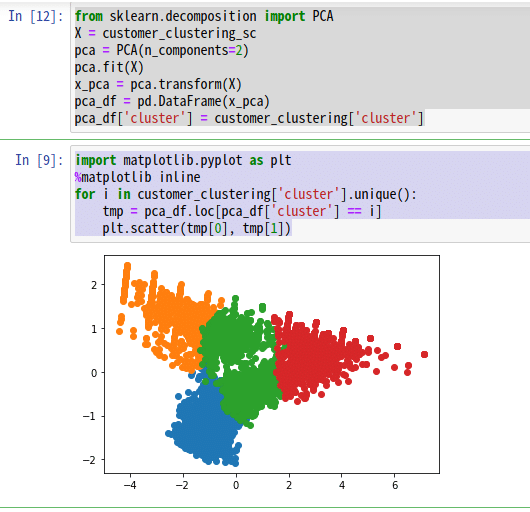
主成分分析
前半のコードブロックでは、主成分分析を行っています。1行目で主成分分析のライブラリをインポートしています。3行目でモデルを定義し、4,5行目で主成分分析を実行しています。
2次元に削減したデータをpca_dfとしてデータフレームに格納し、上記で作成したクラスタリング結果を付与しています。
matplotlibによる可視化
後半のコードブロックでは、matplotlibによる可視化を行っています。3行目からのfor文でグループごとに散布図をプロットすることで、色分けしたグラフを表示しています。
ノック35で直面したエラーと解決方法
ノック35にて、本書と同じコードを実行すると、
ValueError: Grouper for 'is_deleted' not 1-dimensionalと出て困ってしまいました。
グーグル先生に聞いてみると、まさに同じエラーに直面した方が解決コードを書いてくださっていました。参考にしたのは、こちら。
ぐぐるとどうやら"is_deleted"というカラムがpandasのdataframeの中に重複してできているのが原因らしい。
head()関数で確認してみると、確かにis_deletedという名前のカラムが重複してできていました。
カラム名の重複を削除
カラム名の重複を削除するコードは、こちらのサイトの記事が参考になりました。
#重複してないカラム名のみ選択
df.loc[:,~df.columns.duplicated()]なので、本書のコードを以下のように修正してみました。
customer_clustering = pd.concat([customer_clustering, customer], axis=1)
customer_clustering = customer_clustering.loc[:,~customer_clustering.columns.duplicated()]
customer_clustering.groupby(['cluster', 'is_deleted'], as_index=False).count()[['cluster', 'is_deleted', 'customer_id']]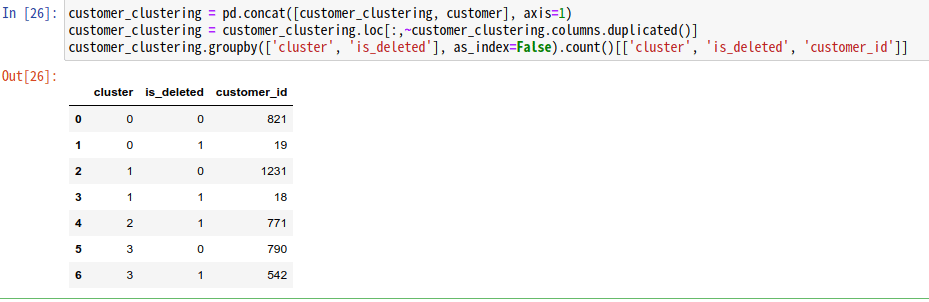
無事に、グループごとの退会/継続顧客の集計ができました♪
今回の学びのまとめ
○特徴量のスケールを合わせる方法として、標準化がある
○3つ以上の変数を二次元上にプロットする場合、次元削除を行う。次元削除とは、教師なし学習の一種で、情報をなるべく失わないように変数を削減して、新しい軸を作り出すこと。
○次元削除の方法の一つが、主成分分析。主成分分析を行う際にも、標準化したデータを用いる。
○カラム名の重複を削除するコード
df.loc[:,~df.columns.duplicated()]いいなと思ったら応援しよう!
