
【Stable Diffusion】あなただけのAI美女の作り方@Google Colab

画像生成AIで美女を愛でている(@Toshimaruちゃん)です。
今回は、Google Colab上でStable Diffusion web UIを動かす方法を紹介します。
【重要追記事項】
昨今の画像生成ブームの影響を受け、Google ColabでのStable Diffusionの利用が制限を受ける可能性があると発表がありました。ただし、有料版は、これに該当しないとのことです。無料で利用することは現状できますが、リスクがあることをご認識ください。
目次(今回できるようになること)
1.Google Colab上でStable Diffusion web UIを動かす
2.LoRAファイルを使っての追加学習
3.ControlNetを使って生成した画像にポーズをつける
4.ControlNet-m2mで生成画像を動かしてみる
それでは早速、AI美女をつくってみましょう。
1.Google Colab上でStable Diffusion web UIを動かす
★Google Colab とは
Pythonをブラウザ上で実行できるサービスです。ハイスペックPCを持っていない方にオススメです。Google Colabでは、無料(制限あり)で利用することができます。有料プランに申し込むことでもっと良い環境で作業可能になります。
Google Colabを利用するには、Googleアカウントの作成が必要なので、アカウントを持っていな方は、作成しておきましょう。
★Stable Diffusion web UI とは
Stable Diffusion WebUIはAUTOMATIC1111さんが作成したブラウザ上で操作できるインターフェイスのことです。
ⅰ)Google Colab上でStable Diffusion web UIを動かすオススメの方法
今回推奨する方法は、Google Colaboratory上でGoogle Driveをマウントして、Drive上のフォルダからデータをダウンロードしてくる方法です。
※Google Driveの容量が必要になります。
まず自身のGoogle Driveを開き、マイドライブの中にStableDiffusionのフォルダを作成しましょう。
今回は、モデルとして【Chilloutmix】をベースに説明していきます。
下記の用にフォルダを作成します。
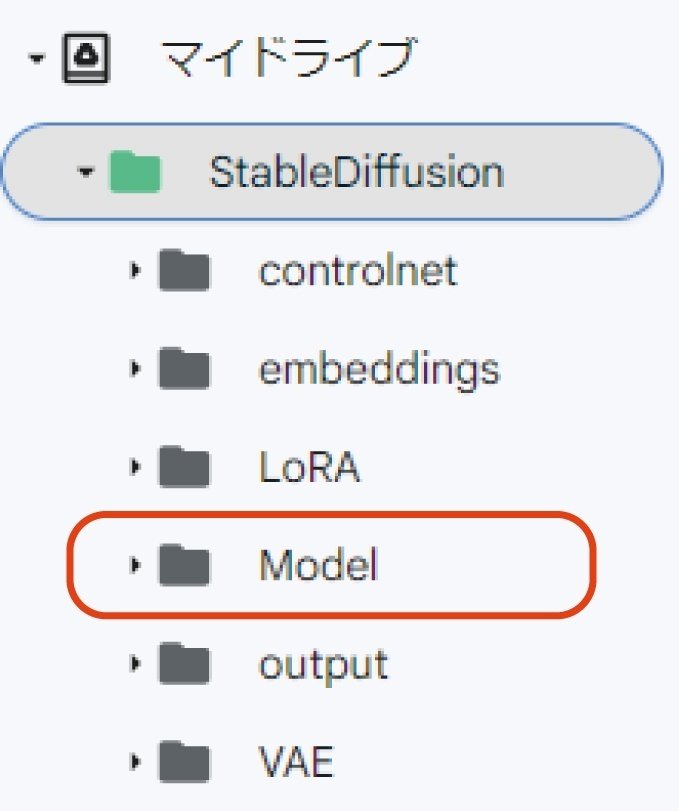
作成出来たら、【civitai】 というサイトから、Chilloutmix のモデルデータをダウンロードしてください。
■Chilloutmix ダウンロード
※civitaiのアカウントが必要です。
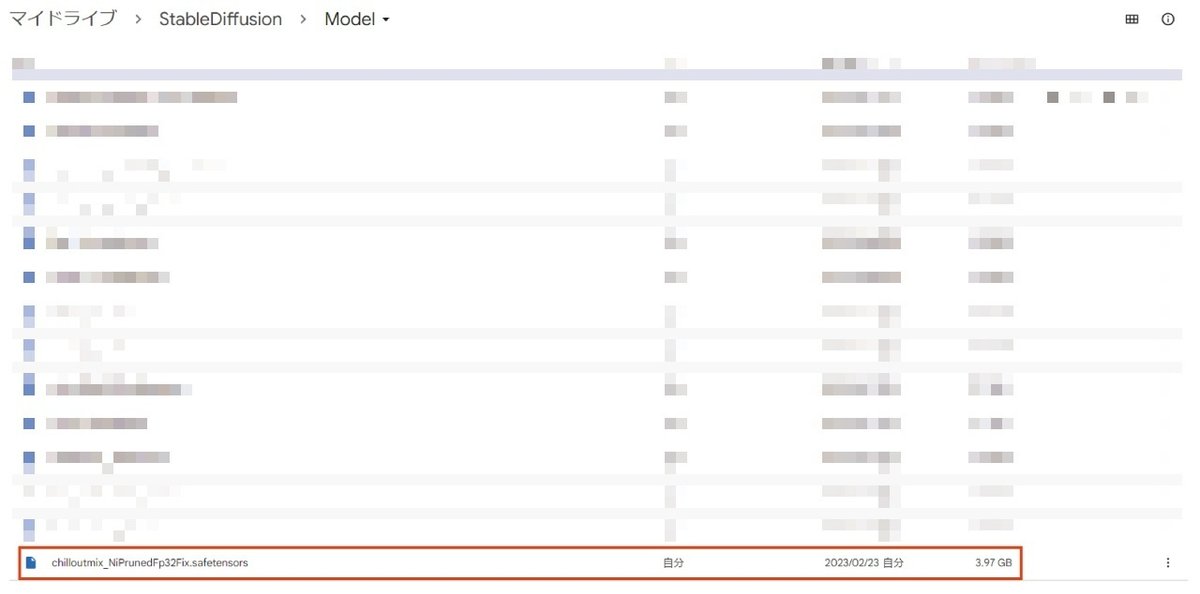
ダウロード出来たら、Google Drive内の【マイドライブ/StableDiffusion/Model】にアップロードしておいてください。
次に、AUTOMATIC1111のGitHubページに移動し「maintained by Akaibu」をクリックしてください。
※maintained by AkaibuのノートブックをGoogle Colabで使用します。

自動的にGoogle Colaboratoryのノートブックが立ち上がります。
※自分好みにコードを追記してくので
「ファイル」→ 「ドライブにコピーを保存」からノートブックをドライブ内に保存して編集します。

それでは、実際にノートブックを編集していきましょう。
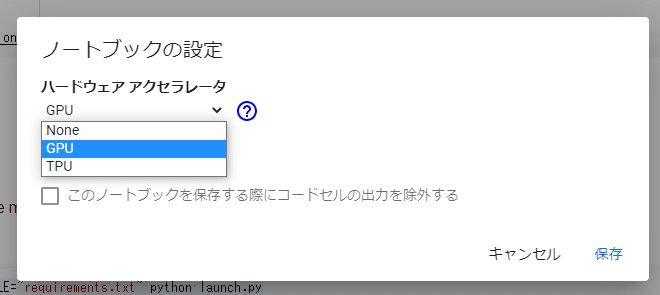
まず初めに、Google Colaboratoryの「ランタイム」をGPUに変更します。
次に、ドライブをマウントするため下記のコードを追加します。
from google.colab import drive
drive.mount('/content/drive')
このコードを実行することで、Google Colaboratory上でGoogle Driveのフォルダを読み込むことができるようになります
次に、SD1.5セル内の不要コードをコメントアウトします。

元のコードはこちら、コメントアウトするのは下3行
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
#@title SD1.5
# get a token from https://huggingface.co/settings/tokens
user_token = "" #@param {type:"string"}
user_header = f"\"Authorization: Bearer {user_token}\""
!wget --header={user_header} https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt -O /content/stable-diffusion-webui/model.ckpt!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
#@title SD1.5
# get a token from https://huggingface.co/settings/tokens
#user_token = "" #@param {type:"string"}
#user_header = f"\"Authorization: Bearer {user_token}\""
#!wget --header={user_header} https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt -O /content/stable-diffusion-webui/model.ckpt上記のように、コードの先頭に#を付けてください。

※このセルでは、Googlr Colab上でWebUIを起動するのに必要なファイルをgithubからダウンロードしています。
次に、上記のセルの下部に、モデルデータをダウンロードするセルを作成します。
また、「+コード」をクリックし、セルを追加します。
ここでようやく最初にダウンロードしておいた【Chilloutmix】の出番です。
下記のコードをセルに入力してください。
!cp /content/drive/MyDrive/StableDiffusion/Model/chilloutmix_NiPrunedFp32Fix.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/
※コメントアウトされているコードは、私の性癖がもろに出ているモデルたちですね(-v-;)
※モデルと合わせてVAEをダウンロードすると良いものもありますので、後程説明します。今回使用するChilloutmixはVAEの推奨はありません。
◆VAEやEmbeddingsについては、後日また記事にします。
最後に、AIイラストの生成速度を早くするコマンドを一番下のセル内にあるCOMMANDLINE_AGES=””の中に、追記しておきましょう。
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py追記するコマンド:--xformers
追加したコードはこちら
!COMMANDLINE_ARGS="--share --gradio-debug --xformers --gradio-auth me:qwerty " REQS_FILE="requirements.txt" python launch.py
ここまでで、一旦の準備は完了したので上からセルを実行していきましょう。
特にエラーがなければ、最後に出現するpublic URLをクリックして「Stable Diffuison WebUI」を起動しましょう。


username:me パルワード:qwerty で入れます。
※ここは、変更できます。
◆注意
RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA versions. PyTorch has CUDA Version=11.7 and torchvision has CUDA Version=11.8. Please reinstall the torchvision that matches your PyTorch install.上記のようなエラーが表示されてしまう場合があります。
この際はノートブックの一番上に新しくセルを追加し、下記のコマンドを実行してください。
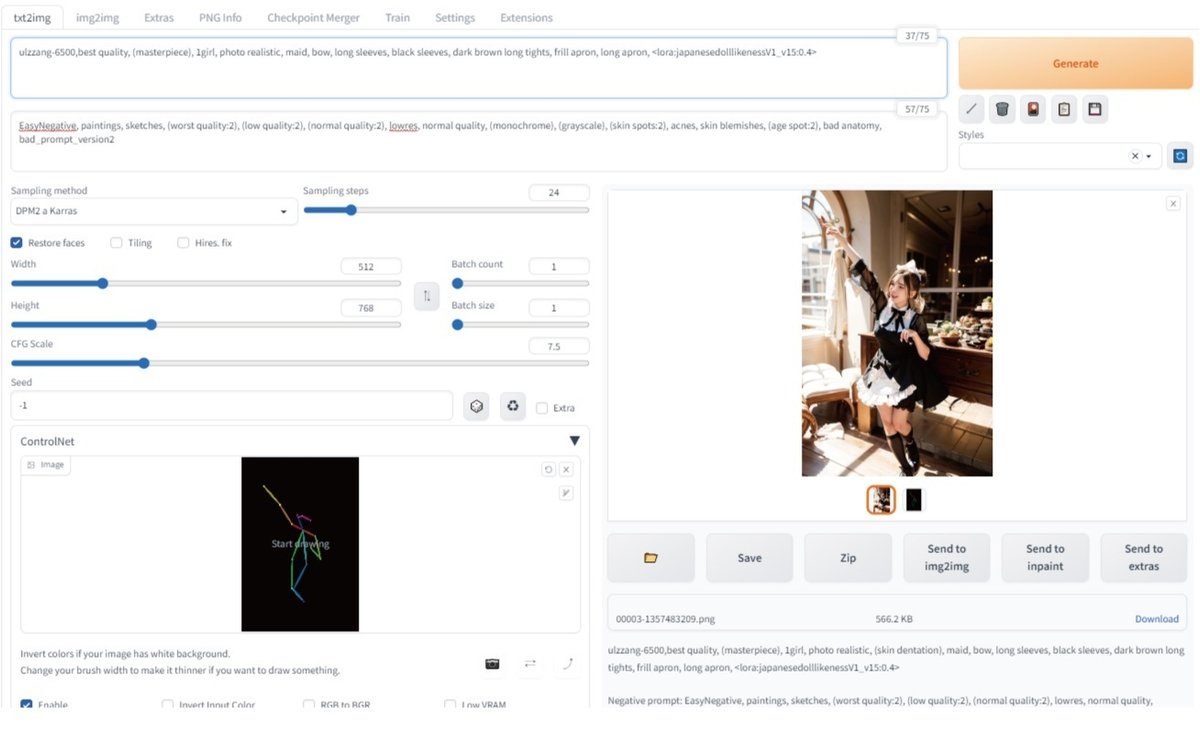
%pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchtext==0.14.1 torchaudio==0.13.1 torchdata==0.5.1 --extra-index-url https://download. pytorch.org/whl/cu117Stable Diffusion WebUIの超ざっくり使用説明は下の画像をチェック

【Hires,fix】で解像度を上げるのがベター。
2.LoRAファイルを使っての追加学習
次に、LoRAを使用して生成する画像を目的のイメージに合わせる方法を紹介します。
★LoRAとは
学習済みモデルに対して追加学習し、その差分を適用する技術です。
例えば、〇〇のキャラクターのような画像を生成したいと考えた場合、プロンプトだけで生成するには限界があります。その際、該当するLoRAで追加学習を行うことでイメージに近い画像を生成することが可能となります。
※LoRAの利用については、ダウンロード元の使用要件などについて必ず確認してください。
それでは、LoRAデータの追加方法について説明します。
今回は、【japanesedolllikenessV1_v15】というLoRAを使用します。
まず、モデルデータ同様に、【civitai】より上記のLoRAデータをダウンロードしてきます。
ダウンロードできたら、Google Drive内のStableDiffusionフォルダに“LoRA”というフォルダを作成してください。
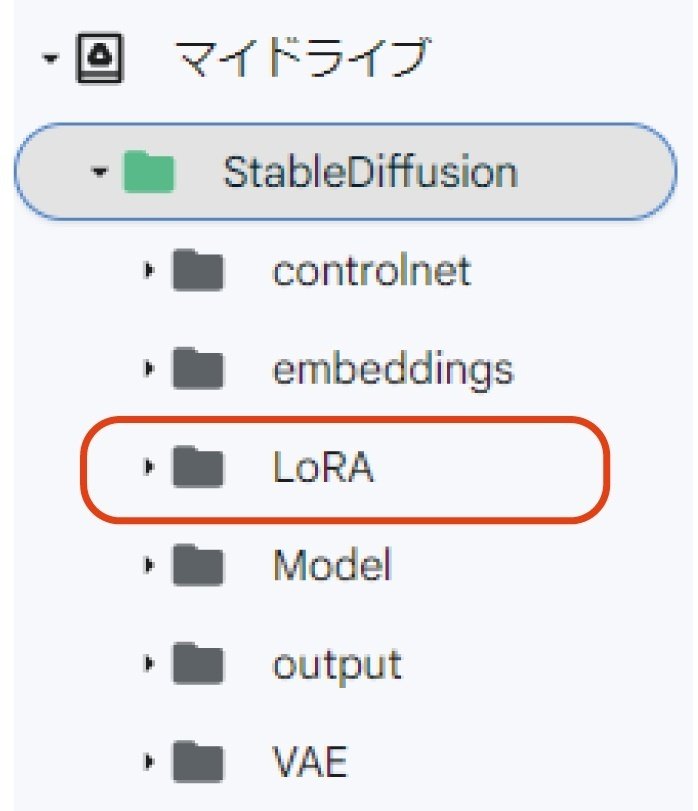
さきほどのLoRAデータを上記にアップロードしておいてください。
ここまで完了したら、さきほどのノートブックに
1.Google Colab上でStable Diffusion web UIを動かす
で説明した、モデルデータをダウンロードするセルの下部に、LoRAデータをダウンロードするセルを作成します。

LoRAデータのセルを作成します。
# Loraディレクトリ
%mkdir -p /content/stable-diffusion-webui/models/Lora/
#LoRAデータ
!cp /content/drive/MyDrive/StableDiffusion/LoRA/japanesedolllikenessV1_v15.safetensors /content/stable-diffusion-webui/models/Lora/ここまで記述できたら、先ほどと同じように、上から順にセルを実行していくだけです。
※LoRAなどを追加した場合は、webuiの再起動が必要です。
LoRAの追加学習を反映させるためには、プロンプト内にトリガーとなるプロンプトの記述、さらには<lora: japanesedolllikenessV1_v15:1.0>などというようなプロンプトを入れる必要がありますのでご注意ください。
※トリガープロンプトなどは、ダウンロード元に記述されています。

3.ControlNetを使って生成した画像にポーズをつける
次に、ControlNetを使って任意のポーズを生成画像に適応させる方法を紹介します。
★ControlNetとは
ニューラルネットワークを使って、イラスト生成AIであるStable Diffusionを制御する手法で、ControlNetが入力された画像を解釈し、その画像を元にしたイラストを生成するようにStable Diffusionをコントロールする仕組みです。
※ControlNetは、特定のモデル(SD1.5/SD2.1)をベースにしているモデルを使用しないと制御できないとされています。(違ったらごめんなさい)
ControlNetは元画像の様々な要素を分析して、その要素を生成する画像に適用できます。
構図分析・線画・直線・物体の距離・輪郭なども検出し、生成する画像に適用することができます。
今回紹介するのは、【openpose】という頭の位置、肩、手などの人間のキーポイントを検出する手法です。
それでは、ControlNetの導入について説明します。
まず初めに、ノートブック上部のSD1.5セルに、下記のコードを追加します。

!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
この上のコードの下に下記のコードを入れる
#controlnet
!git clone https://github.com/Mikubill/sd-webui-controlnet.git /content/stable-diffusion-webui/extensions/sd-webui-controlnet※今回は、Mikubill氏の学習データを使用します。
次に、ControlNet用のモデルデータ【openpose】をダウンロードします。
※合わせてcanny(線画抽出)やdepth(物体距離)などのモデルも合わせてダウンロードしても良いでしょう。
■openpose ダウンロード
ダウンロードできたら、Google Drive内のStableDiffusionフォルダに“ControlNet”というフォルダを作成してください。

さきほどのControlNet用のモデルデータを上記にアップロードしておいてください。
アップロードできたら、先ほど追加したセルの下部に、下記のコードを追加します。
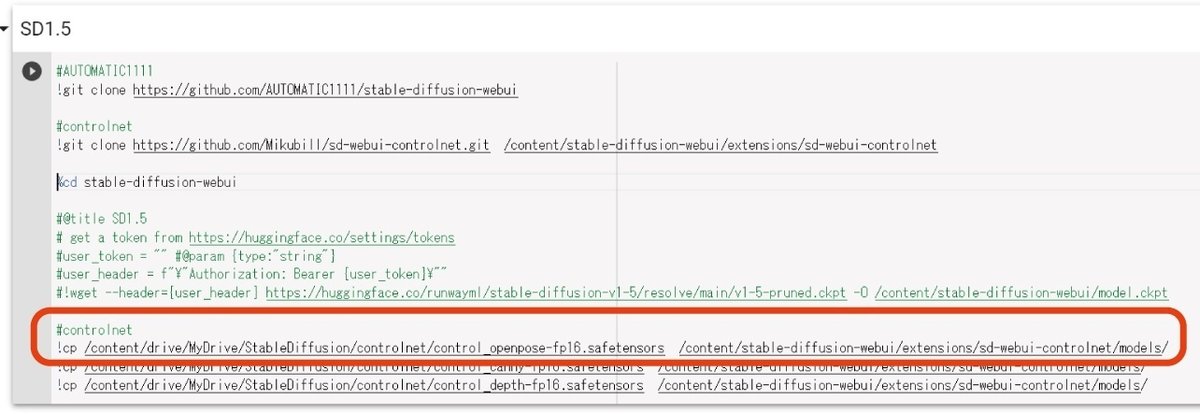
#controlnet用モデルデータ
!cp /content/drive/MyDrive/StableDiffusion/controlnet/control_openpose-fp16.safetensors /content/stable-diffusion-webui/extensions/sd-webui-controlnet/models/ここまで出来たら、上から順にセルを実行してください。
※ControlNetを追加した場合は、webuiの再起動が必要です。
stable-diffusion-webuiを起動するとControlNetが追加された状態になっています。

ControlNetを導入するとtxt2imgタブとImg2imgタブ、それぞれの画面の下に「ControlNet」が追加されます。
こちらをクリックするとControlNetオプションが展開されます。
★それでは実際に画像にポージングさせてみましょう!
まず初めにポーズの参考にしたい画像をイメージエリアにドロップします。

次に、オプション内の“Enable”をチェックするとControlNetが有効になります。
プリプロセッサは、「Openpose」を指定します。
※構図指定時はOpenpose推奨
モデルも「Openpose」を指定します。
※基本的にプリプロセッサとモデルは同じものを指定
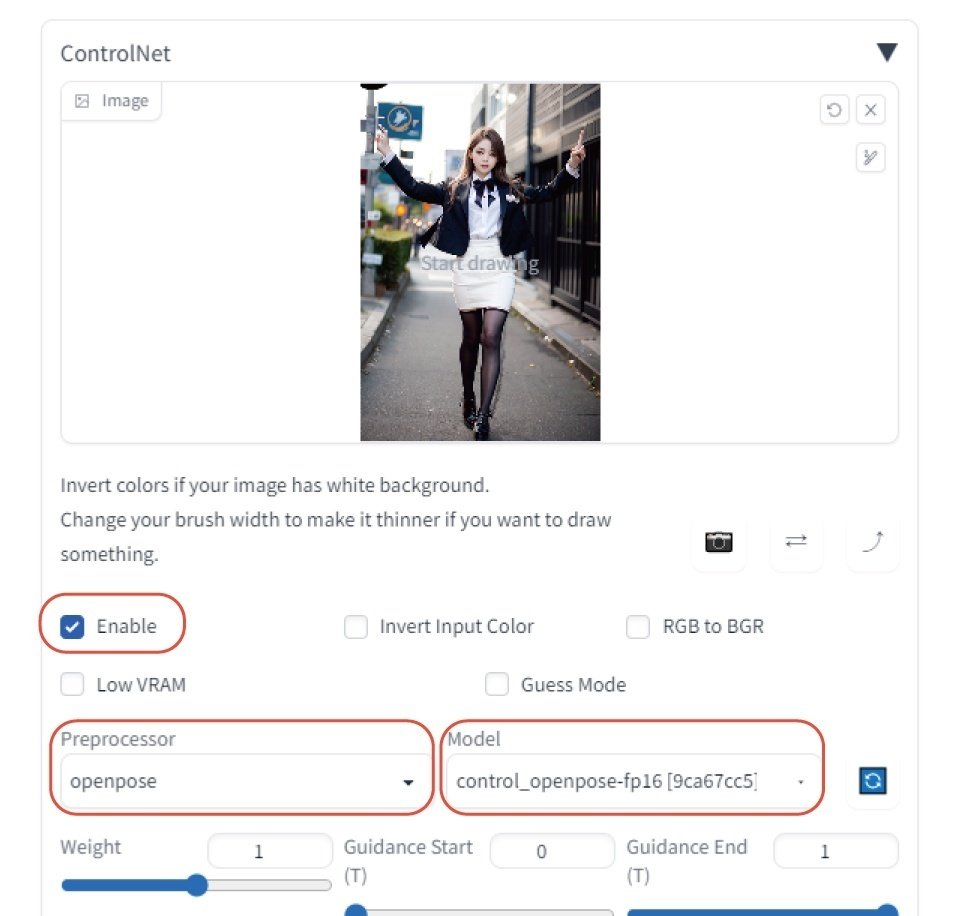
そして、通常通りプロンプト内に任意のプロンプトを入力します。画像サイズなども設定してください。
設定が済んだら生成ボタンを押して画像生成します。
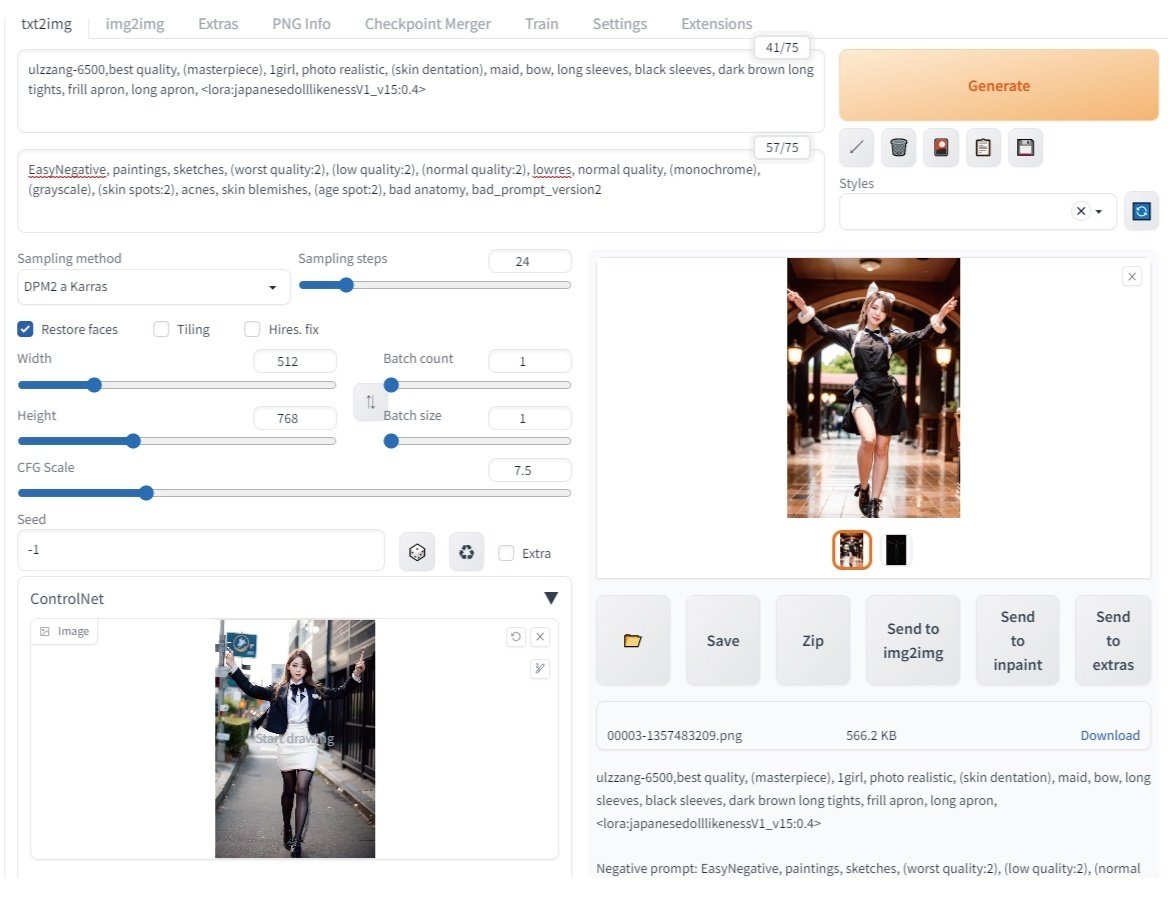
★ポーズ画像(棒人間画像)から画像生成する場合
ポーズ画像(棒人間画像)をControlNetのイメージエリアにドロップします。
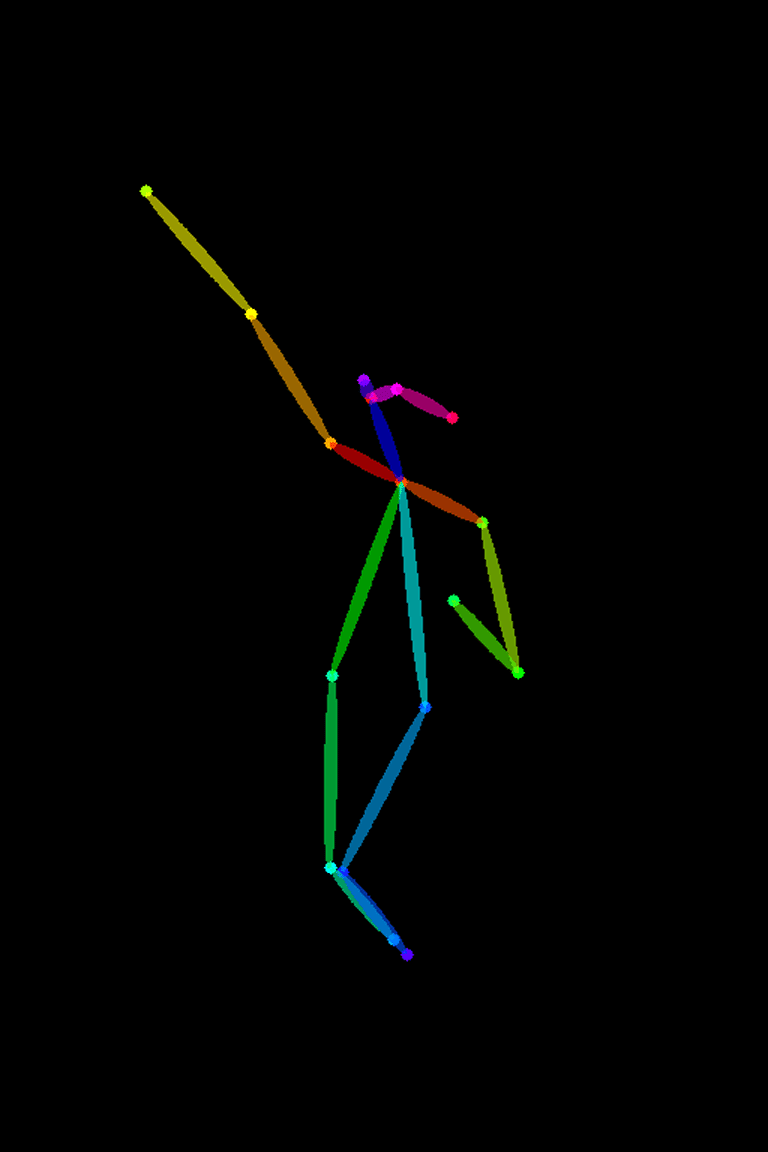
その際、プリプロセッサとモデルを下記のようにセットします。
プリプロセッサを「none」
ControlNetモデルを「Openpose」

※プリプロセッサは、画像から棒人間画像を抽出するプロセスです。
棒人間画像から画像を生成するときは、プリプロセッサは不要なので「None」になります。
リアル系のポージングは顔などが崩れやすいのでも難しい印象です。
イラスト系モデルの方が相性良いかも。
※単なる実力不足の可能性大・・・
ControlNetの細かい設定は、また後日別の記事にします!
4.【応用編】ControlNet-m2mで生成画像を動かしてみる
最後に、ControlNetに最近追加された拡張機能、m2mにチャレンジします。
※私もあまり成功したという実感がないのでお手柔らかに・・・
導入方法は、ControlNetを導入する手順で問題ありません。
★有効化する方法
Webuiを起動後 →Settings → ControlNet → Allow other script to control this extension
をONにして、ページ上部にある Apply setting を押す。

そして、3.ControlNetを使って生成した画像にポーズをつける で説明したようにControlNetの設定(プリプロセッサやControlNetモデル)を行う。
次に、ControlNetタブの下部にScript(none)になっている箇所があるので、クリックして【controlnet m2m】を選ぶ。

すると、イメージエリア(動画をドロップできる)が出てくるのでこちらに任意の動画をドロップする。
イメージエリアの下部に【Duration設定】があるのですが、Durationは1枚のフレームを表示する時間をミリ秒単位で調整できるので、ゆっくり画像を動かしたい場合は大きめの値を設定してもらえればと思います。
※ただし、莫大な時間がかかります・・・
生成された動画ファイルは
/stable-diffusion-webui/outputs/txt2img-images/controlnet-m2m/
配下にgif動画として書き出されますので
# ディレクトリを作成するパスを指定
%mkdir -p /content/stable-diffusion-webui/outputs/txt2img-images/controlnet-m2m/上記のコードでディレクトリを作成しておきましょう。
※手作業で作成してもOK
動画の秒数が長いと生成画像の枚数が莫大になりますので、最初は2~3秒の動画から始めてみてください。
★個人的な動画化のオススメソフトウェア
上記で生成されたgifでも良いのですが、gif化される前の画像(outputs/txt2img-images 内にたくさん生成されています)を「Flowframes(フリーソフト)」というソフトで画像間のコマ補正をしながら動画化する方法が最も良い結果になるかと思います。
Flowframes(フリーソフト)の使い方は下記のサイトをご確認ください。
※https://www.gigafree.net/media/me/Flowframes.html
以上、駄文でしたがご理解いただけましたでしょうか。
まずはいろいろチャレンジしてみてください。