
「ToyADMOS:異常音検知」:AutoEncoder

「ToyADMOS:異常音検知」手法比較:CNN+DNN と AutoEncoder の続きです。AutoEncoderのコードと実行結果サンプルを以下に示します。
概要
この例では、オートエンコーダーをトレーニングして異常を検出します。
データセットは、ToyADAMOSのToyCar、Case4、CH1です。
このデータセットには、1335 の正常データ、263個の異常データが含まれ、それぞれに 528000 のデータポイントがあります。各例には、0(正常音)または1(異常音)のいずれかのラベルが付けられています。ここでは正常音、異常音の分類します。
目的は、ラベルが使用できない、より大きなデータセットに適用できる異常検出器を作成することです。(たとえば、数千の正常データがあり、異常なデータが少数しかない場合 や 未知の異常を検出する場合)。
オートエンコーダーは正常データでのみトレーニングし、モデルを使用してデータを再構築し、正常データの再構成エラーより閾値を設定します。異常波形の再構成エラーは正常データより大きいと仮定し、再構成エラーが閾値を超えた場合、オーディオデータを異常として分類します。本例では閾値を再構成エラーの平均+2σとしています。
1.データセット:
ToyADAMOS:ToyCar, case4, CH1
2.コード(AutoEncoder)
モジュールのインポート
import os
import pathlib
import glob
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers, losses
from tensorflow.keras.models import Model
import seaborn as sns
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)データセットやドライブの設定
# 対象を選択
detect_target = "car" # {"car": 'ToyCar', "conv":'ToyConveyor', "train":'ToyTrain'}
detect_case = "case4"
METHOD = 'AutoEncoder_'
# 対象の辞書
detect_targets_dict = {"car": 'ToyCar', "conv":'ToyConveyor', "train":'ToyTrain'}
detect_cases_dict = {"case1":'case1', "case2":'case2', "case3":'case3', "case4":'case4'}
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')
#print("カレントワーキングディレクトリは[" + os.getcwd() + "]です")
_colab_dir = "/content/drive/MyDrive"
_colab_dir_program = _colab_dir+"/Anomaly_Detection/program"
_colab_dir_data = _colab_dir+"/Anomaly_Detection/data/"+detect_targets_dict[detect_target]+"/"+detect_cases_dict[detect_case]+"/ch1"
_folder_save = _colab_dir+"/Anomaly_Detection/result/CNN_DNN/"
os.chdir(_colab_dir_program)
print("カレントワーキングディレクトリは[" + os.getcwd() + "]です")
print("データディレクトリは[" + _colab_dir_data + "]です")
# サウンドデータセットをインポートするフォルダ
DATASET_PATH = _colab_dir_data
data_dir = pathlib.Path(DATASET_PATH)データセットのオーディオクリップは、正常・異常コマンドに対応する2つのフォルダに保存されています:
# データセットのオーディオクリップは、
# 各サウンドに対応する2つのフォルダに保存されます:
# 'NormalSound_IND' 'AnormalousSound_IND'
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = sorted(commands, reverse=True) #
print('Commands:', commands)
オーディオファイルの読込
# オーディオクリップをfilenamesというリストに抽出します
filenames = glob.glob(str(data_dir) + '/*/*')
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of NormalSound_IND per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Number of AnomalousSound_IND label:',
len(tf.io.gfile.listdir(str(data_dir/commands[1]))))
print('Example file tensor:', filenames[0])
オーディオファイルとそのラベルを設定
各ファイルの親ディレクトリを使用してラベルを作成する関数を定義します。
# 各ファイルの親ディレクトリを使用してラベルを作成する関数
def get_label_id(file_path):
parts = file_path.split('/')
label = parts[-2] # 最下層から2番目のフォルダ名を取得
label_id = commands.index(label) # インデックスを取得
return label_idデータセットを作成
filenamesをシャッフルして、トレーニング、テストセットに、それぞれ80:20の比率で分割します。
files_ds = tf.data.Dataset.from_tensor_slices(filenames)
file_labels = list(map(get_label_id, filenames))
train_data, test_data, train_labels, test_labels = train_test_split(
list(filenames), file_labels, test_size=0.2, random_state=seed) #
train_data_normal = []
train_data_anomaly = []
test_data_normal = []
test_data_anomaly = []
[train_data_normal.append(s) for s in train_data if "NormalSound_IND"in s]
[train_data_anomaly.append(s) for s in train_data if "NormalSound_IND"not in s]
[test_data_normal.append(s) for s in test_data if "NormalSound_IND"in s]
[test_data_anomaly.append(s) for s in test_data if "NormalSound_IND"not in s]
print("num of train_data_normal: ", len(train_data_normal))
print("num of train_data_anormaly: ", len(train_data_anomaly))
print("num of test_data_normal: ", len(test_data_normal))
print("num of test_data_anormaly: ", len(test_data_anomaly))
# オーディオファイルの形状を確認
test_file = tf.io.read_file(filenames[0])#DATASET_PATH+'/NormalSound_IND/1200010001_ToyCar_case2_normal_IND_ch1_0001.wav')
test_audio, sampling_rate = tf.audio.decode_wav(contents=test_file)
# tf.audio.decode_wavによって返されるテンソルの形状は[samples, channels]
# channelsはモノラルの場合は1 、ステレオの場合は2
test_audio.shape
# Audio Setting
Data_num = test_audio.shape[0]
Sampling_freq = sampling_rate.numpy()
time_length = Data_num / Sampling_freq
print("Data数:", Data_num)
print("サンプリング周波数[Hz]:", Sampling_freq)
print("時間窓長[sec]:", time_length)
print("分析周波数レンジ[Hz]:", Sampling_freq / 2)
次に、データセットの生のWAVオーディオファイルをオーディオテンソルに前処理する関数を定義。
# データセットの生のWAVオーディオファイルをオーディオテンソルに前処理する関数を定義
# normalized to the [-1.0, 1.0] range
def decode_audio(audio_binary):
audio, _ = tf.audio.decode_wav(contents=audio_binary)
return tf.squeeze(audio, axis=-1) # モノラル信号のため、チャンネル軸を除去すべてをまとめる別のヘルパー関数get_waveformを定義します。
# すべてをまとめる別のヘルパー関数get_waveformを定義
# 入力はWAVオーディオファイル名です。
# 出力は、教師あり学習の準備ができているオーディオテンソルを含むタプルです。
def get_waveform(file_path):
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform音声とラベルのペアを抽出するためのトレーニングセットを作成します。後で同様の手順を使用して、検証セットとテストセットを作成します。
AUTOTUNE = tf.data.AUTOTUNE
# 前に定義したget_waveform使用して、
# Dataset.from_tensor_slicesとDataset.mapを使用してtf.data.Datasetを作成します。
files_ds = tf.data.Dataset.from_tensor_slices(train_data)
waveform_ds = files_ds.map(
map_func=get_waveform,
num_parallel_calls=AUTOTUNE) # トレーニングセット作成いくつかのオーディオ波形をプロット。
# いくつかのオーディオ波形をプロット
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label_id) in enumerate(zip(waveform_ds.take(n), train_labels)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = commands[label_id]
ax.set_title(label)
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + '_wave.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
波形をFFT変換する
時間領域で表されたデータセット内の波形の高速フーリエ変換(FFT)を計算して波形を周波数領域に変換します。
時間領域信号 ⇒ 周波数領域信号(トレーニング)
周波数はlog10スケールに変換しています。また、データ点数が時間領域の半分になります。
波形をFFTに変換するためのユーティリティ関数を作成します。
# 波形をフーリエ変換
# 周波数はlog10スケールに変換
def get_fft(waveform):
waveform = tf.complex(waveform, 0.0)
fft = tf.signal.fft(waveform)
fft = tf.abs(fft)
# Convert the frequencies to log scale and transpose
fft_log_spec = tf.experimental.numpy.log10((fft + 2.2204460492503131e-16) / 2.2204460492503131e-16)
fft_log_spec = fft_log_spec[0:len(fft)//2]
return fft_log_specデータの調査を開始します。 1つの例のテンソル化された波形と対応するFFT変換後の形状を印刷し、元のオーディオを再生します。
for waveform in waveform_ds.take(1):
#label = label.numpy().decode('utf-8')
# spectrogram = get_spectrogram(waveform)
fft = get_fft(waveform)
#print('Label:', label)
print('Waveform shape:', waveform.shape)
#print('Spectrogram shape:', spectrogram.shape)
print('FFT shape:', fft.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=Sampling_freq))
時間の経過に伴う例の波形と対応するフーリエ変換結果をプロットします。
# 時間波形と周波数波形をプロット
timescale = np.arange(Data_num) #len(waveform)
timescale = timescale/Sampling_freq
freq = np.arange(Data_num//2) * Sampling_freq / Data_num
fig, axes = plt.subplots(2, figsize=(12, 10))
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, Data_num/Sampling_freq]) # [0, Data_num]
axes[0].set_xlabel("time[sec]")
axes[0].grid()
axes[1].plot(freq/1000, fft)
axes[1].set_title('FFT')
axes[1].set_xlabel("frequency[kHz]")
axes[1].set_ylabel("[dB]")
axes[1].grid()
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + '_wave_spect.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
モデルを構築してトレーニングする
検証セットとテストセットでトレーニングセットの前処理を繰り返します。
# AudioファイルをFFTへ変換
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform,
num_parallel_calls=AUTOTUNE
)
output_ds = output_ds.map(
map_func=get_fft,
num_parallel_calls=AUTOTUNE
)#.batch(len(files))
return output_ds波形データセットをFFTデータセットに変換します
# 各データリストをFFTへ変換
train_ds = preprocess_dataset(train_data_normal)
test_ds = preprocess_dataset(test_data)
test_ds_normal = preprocess_dataset(test_data_normal)
test_ds_anomaly = preprocess_dataset(test_data_anomaly)
train_ds = list(train_ds)
test_ds = list(test_ds)
test_ds_normal = list(test_ds_normal)
test_ds_anomaly = list(test_ds_anomaly)データを [0,1] に正規化します。
# FFTの値を[0,1]の範囲へnormarization
min_val = tf.reduce_min(train_ds) # trainデータセットの最小値取得
max_val = tf.reduce_max(train_ds) # trainデータセットの最大値取得
train_ds = (train_ds - min_val) / (max_val - min_val) # [0,1]へ正規化
test_ds = (test_ds - min_val) / (max_val - min_val) # [0,1]へ正規化 ※ trainデータの最小値・最大値を使用
test_ds_normal = (test_ds_normal - min_val) / (max_val - min_val) # [0,1]へ正規化 ※ trainデータの最小値・最大値を使用
test_ds_anomaly = (test_ds_anomaly - min_val) / (max_val - min_val) # [0,1]へ正規化 ※ trainデータの最小値・最大値を使用
train_ds = tf.cast(train_ds, tf.float32) # 型の変換
test_ds = tf.cast(test_ds, tf.float32)
test_ds_normal = tf.cast(test_ds_normal, tf.float32)
test_ds_anomaly = tf.cast(test_ds_anomaly, tf.float32)input shapeを取得します。
input_shape = train_ds.shape
input_shape = input_shape[1]
print('Input shape:', input_shape)Input shape: 240000
モデルでは、周波数領域に変換したオーディオファイルをAutoEncoderで学習します。
autoencoder = tf.keras.Sequential([
layers.Dense(528, activation="relu"),
layers.Dense(128, activation="relu"),
layers.Dense(64, activation="relu", name = 'encoder'),
layers.Dense(128, activation="relu"),
layers.Dense(528, activation="relu"),
layers.Dense(input_shape, activation="sigmoid")]) # 出力は(0,1)Adamとクロスエントロピー損失を使用してKerasモデルを構成します。
最適化関数:Adam(モーメンタム×RMSProp)
平均絶対誤差(MAE:Mean Absolute Error):データに対して「予測値と正解値の差(=誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を出力する関数
autoencoder.compile(optimizer='adam', loss='mae') オートエンコーダは正常のオーディオファイルのみを使用してトレーニングします。評価は、完全なテストセット(正常&異常)を使用して行います。
モデルを20エポックまでトレーニングします。
%%time
# オートエンコーダは正常の オーディオファイル のみを使用してトレーニング、
# 完全なテストセットを使用して評価されることに注意。
EPOCHS = 20
history = autoencoder.fit(train_ds, train_ds,
epochs=EPOCHS,
batch_size=512,
validation_data=(test_ds, test_ds),
shuffle=True,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
オートエンコーダのサマリを表示します。
autoencoder.summary()
トレーニングと検証の損失曲線をプロットして、トレーニング中にモデルがどのように改善されたかを確認します。
fig = plt.figure(figsize=(10, 8))
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + '_loss.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
テストセットからの正常な オーディオファイル、オートエンコーダーによりエンコードおよびデコードされた後の再構成、および再構成エラーをプロットします。
# 正常なテストサンプル
decoded_data = autoencoder(test_ds_normal).numpy()
fig = plt.figure(figsize=(10, 8))
plt.plot(test_ds_normal[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(input_shape), decoded_data[0], test_ds_normal[0], color='lightcoral') #
plt.legend(labels=["Input", "Reconstruction", "Error"])
#plt.xlabel('frequency[Hz]')
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'input_resonstruction_normal.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
テストセットからの異常な オーディオファイル、オートエンコーダーによりエンコードおよびデコードされた後の再構成、および再構成エラーをプロットします。
# 異常なテストサンプル
decoded_data = autoencoder(test_ds_anomaly).numpy()
fig = plt.figure(figsize=(10, 8))
plt.plot(test_ds_anomaly[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(input_shape), decoded_data[0], test_ds_anomaly[0], color='lightcoral') #
plt.legend(labels=["Input", "Reconstruction", "Error"])
#plt.xlabel('frequency[Hz]')
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'input_resonstruction_anomaly.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
再構成エラーが分かりにくいので、横軸を限定してプロットします。
# 拡大
start = 50000
length = 100
end = start + length
fig = plt.figure(figsize=(10, 8))
plt.plot(np.arange(start,end), test_ds_anomaly[0][start:end], 'b')
plt.plot(np.arange(start,end), decoded_data[0][start:end], 'r')
plt.fill_between(np.arange(start,end), decoded_data[0][start:end], test_ds_anomaly[0][start:end], color='lightcoral') #
plt.legend(labels=["Input", "Reconstruction", "Error"])
#plt.xlabel('frequency[Hz]')
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'input_resonstruction_anomaly_mag.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
異常を検出します
再構成損失がしきい値より大きいかどうかを計算することにより、異常を検出します。トレーニングセットから正常なサンプルの平均平均誤差を計算し、再構成誤差が平均+2σよりも大きいサンプルを異常として分類します。
トレーニングセットの正常オーディオファイル の再構成エラーをプロットします
reconstructions = autoencoder.predict(train_ds)
train_loss = tf.keras.losses.mae(reconstructions, train_ds)
fig = plt.figure(figsize=(10, 8))
plt.hist(train_loss[None,:], bins=50)
plt.xlabel("Train loss")
plt.ylabel("No of examples")
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'hist_train_normal.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
平均+2標準偏差をしきい値とします。
# 平均+2×標準偏差をしきい値とします。
threshold = np.mean(train_loss) + np.std(train_loss) * 2
print("Threshold: ", threshold)
テストセットの異常なサンプルの再構成エラーを調べると、ほとんどの場合、再構成エラーはしきい値よりも大きいことがわかります。しきい値を変更することで、分類器の精度とリコールを調整できます。
# テストセットの異常なサンプルの再構成エラーを調べます。
# しきい値を変更することで、分類器の精度とリコールを調整できます。
reconstructions = autoencoder.predict(test_ds_anomaly)
test_loss_ab = tf.keras.losses.mae(reconstructions, test_ds_anomaly)
reconstructions = autoencoder.predict(test_ds_normal)
test_loss_no = tf.keras.losses.mae(reconstructions, test_ds_normal)
fig = plt.figure(figsize=(16,6))
plt.subplot(1,2,1)
plt.hist(test_loss_no[None, :], bins=50)
plt.vlines(threshold, 0, 40, 'r', 'dashed')
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.title("Normal data of Testset")
plt.subplot(1,2,2)
plt.hist(test_loss_ab[None, :], bins=50)
plt.vlines(threshold, 0, 10, 'r', 'dashed')
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.title("Anomalous data of Testset")
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'hist_test_anomaly.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)
テストデータセット全体のヒストグラムを確認します。
reconstructions = autoencoder.predict(test_ds)
test_loss = tf.keras.losses.mae(reconstructions, test_ds)
fig = plt.figure(figsize=(10, 8))
plt.hist(test_loss[None, :], bins=100)
plt.vlines(threshold, 0, 125, 'r', 'dashed')
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.show()
# ファイルを保存
fname = METHOD + detect_target + "_" + detect_case + 'hist_test_all.png'
path_save = _folder_save + fname
fig.savefig(path_save, dpi=64) #facecolor="lightgray", tight_layout=True)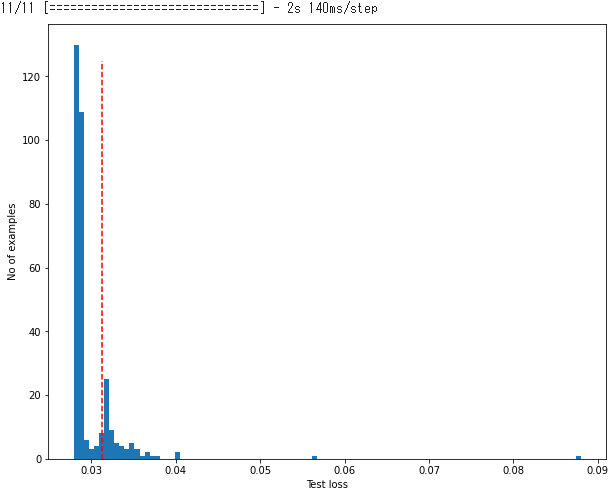
モデルのパフォーマンスを評価する
再構成エラーがしきい値よりも大きい場合は、オーディオファイル を異常として分類します。
# しきい値が再構成エラーよりも大きい場合は、オーディオファイル を異常として分類します。
def predict(model, data, threshold):
reconstructions = model(data)
loss = tf.keras.losses.mae(reconstructions, data)
return tf.math.less(threshold, loss)テストセットでモデルを実行し、モデルのパフォーマンスを確認します。
preds = predict(autoencoder, test_ds, threshold) precisioin(適合率)、recall(再現率)、f1-score(f1スコア)のレポート表示
fname = METHOD + detect_target + "_" + detect_case + '_classification_report.csv'
path_save = _folder_save + fname
print(classification_report(test_labels, preds,
target_names=commands))
report = classification_report(test_labels, preds,
target_names=commands, output_dict=True)
report_df = pd.DataFrame(report).T
report_df.to_csv(path_save)
混同行列を表示する
混合行列を使用して、モデルがテストセット内の各コマンドをどの程度適切に分類したかを確認します。
# 混同行列を表示する
confusion_mtx = tf.math.confusion_matrix(test_labels, preds)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g',annot_kws={"fontsize":17})
plt.xlabel('Prediction',fontsize=17)
plt.ylabel('Label',fontsize=17)
plt.show()