
[Rによるデータ分析入門]東大社研パネル非制限公開疑似データ

本コラムはRによるデータ分析入門のWEBサポートとして作成されています。
本コラムでは東大社研パネル非制限公開データを紹介します。
東大社研若年者パネルとは
東大社研若年者パネルとは、東京大学社会科学研究所が実施するパネル調査です。2006年12月末現在で20歳から34歳のいわゆる「若年層」を対象に調査が開始され、同一個人を時系列で追跡する調査です。本調査のデータは匿名処理を施したものを学術利用目的する場合に限り、研究・教育目的で二次利用することができます。利用には申請手続きが必要なので、東京大学社会科学研究所データアーカイブ研究センターのWEBサイトを参照してください。
https://csrda.iss.u-tokyo.ac.jp/
東大社研パネル非制限公開データとは
東大社研若年者パネルの2007年のデータをもとに作成された、擬似データです。1,000ケースを無作為抽出したうえで、変数を大幅に減らし、回答には無作為にノイズを混入させています。利用資格に制限はなく、誰でも利用できます。
CSRDA:非制限公開擬似データの提供 (u-tokyo.ac.jp)
念のため、データと調査票をここに置いておきます。
調査票 u001c.pdf
データ u001.csv
非制限公開データを加工してみよう
このデータを分析しやすいように加工する方法を紹介します。まずu001.csvをEXCELで開いてみたのが以下です。sexは性別、ybirthとmbirthは生まれ年と月であることは想像できそうですが、ZQ03やJC_1は何かの記号のようです。
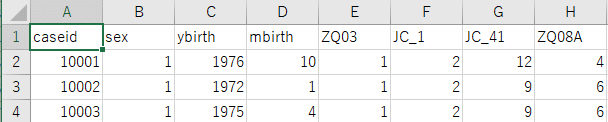
そこで調査票を参照します。ZQ03は問3の回答に対応することがわかります。
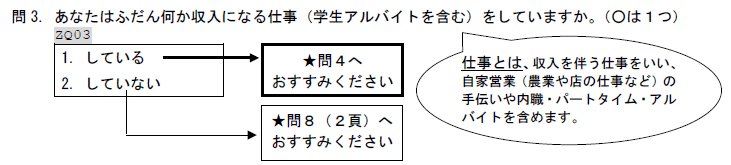
JC_1とJC_41は問4に対応します。

このデータを使いやすくするためにはJC_1などをわかりやすい変数名に変更し、必要に応じてダミー変数などを作成する必要があります。
たとえばデータを読み込み、sexとybirthを参照して、女性ダミーfemaleと年齢ageを作成する場合、以下のようなスクリプトを作成します。
library(tidyverse)
#データファイルを読み込む
dataf <- readr::read_csv("u001.csv")
#女性ダミーと年齢を作成する
#性別の元の変数はsex 1 男性、2 女性
#年齢ageは2007からybirth(生年)を引く
dataf <- dataf %>%
dplry::mutate(
female = if_else(sex == 2,1,0),
age = 2007 - ybirth
)mutateとif_else()を組み合わせると、
mutate([新しい変数]=if_else([条件式], [真], [偽]))
と書くことで、[条件式]が成り立てば[新しい変数]に[真]を代入、
[条件式]が成り立たなければ[新しい変数]に[偽]を代入、
という意味になります。
女性ダミーはdplyr::mutate()とcase_when()を使って作成することもできます。
dataf <- dataf %>%
dplry::mutate(female = case_when(sex == 2~1,
sex != 1~0)mutateとcase_when()を組み合わせると、
mutate([新しい変数]=case_when([条件式1]~[結果1]),
[条件式2]~[結果2])
と書くことで、[条件式1]が成り立てば[新しい変数]に[結果1]を代入、
[条件式2]が成り立てば[新しい変数]に[結果2]を代入、
という意味になります。
同様に年収の情報も整理してみましょう。年収は問47、ZQ47A~47Cです。ZQ47Aが「あなた個人」、ZQ47BとZQ47Cがそれぞれ「配偶者」と「世帯全体」に対応します。たとえば、incomeという変数を作成し、3と回答した人は年収25~75万円なので中央の値である50、同様に4と回答した人は100万円前後なので100という数値に置き換えれば、incomeという変数は連続した数値になります。
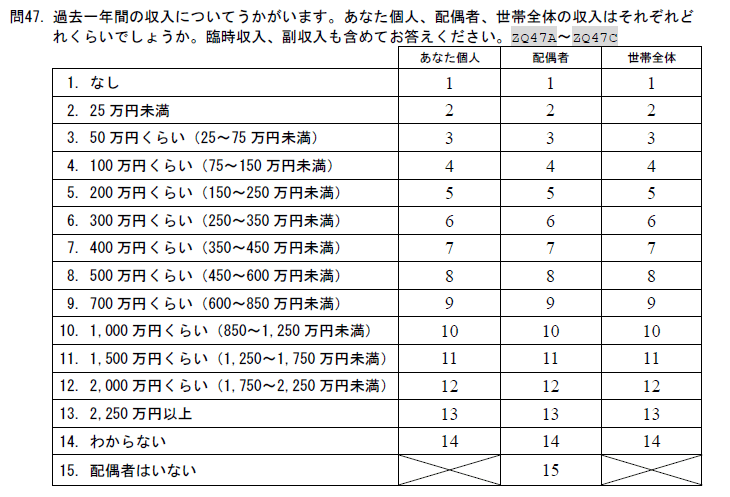
加工する前にtable()関数でZQ47Aの回答状況をみてみました。1が113となっていますが、「所得なし」が113人いることを占めいます。そして、注意してほしいのが99が33人いること。ZQ47Aの選択肢は1~14で99はありません。33人は、この項目に回答しなかった回答拒否サンプルだと考えられます。また14も所得の情報がないので、ZQ47Aが14と99になっている人は、この項目を「欠損値」として扱うことにします。
> # income 本人の年収ZQ47A、カテゴリー変数なので具体的な数値を入れる
> table(dataf$ZQ47A)
1 2 3 4 5 6 7 8 9 10 11 12 14 99
113 61 60 133 163 176 118 76 16 7 1 1 42 33 case_when()関数を使ってincomeという変数を作成してみましょう。
dataf <- dataf %>%
dplyr::mutate(
income = case_when(
ZQ47A == 1 ~ 0,
ZQ47A == 2 ~ 25,
ZQ47A == 3 ~ 50,
ZQ47A == 4 ~ 100,
ZQ47A == 5 ~ 200,
ZQ47A == 6 ~ 300,
ZQ47A == 7 ~ 400,
ZQ47A == 8 ~ 500,
ZQ47A == 9 ~ 700,
ZQ47A == 10 ~ 1000,
ZQ47A == 11 ~ 1500,
ZQ47A == 12 ~ 2000,
ZQ47A == 13 ~ 2250
))case_whenでは条件に該当しないサンプルにはNA(欠損値フラグ)が割り当てられます。以下ではincomeが欠損値であるサンプルに限定(filter(is.na(income)))して、ZQ47Aとincomeを表示させてみましょう: select(ZQ47A,income)
> # case_whenでは条件に該当しないサンプルにはNA(欠損値フラグ)が割り当てられる
> # 以下ではincomeが欠損値であるサンプルに限定(filter(is.na(income)))して、
> # ZQ47Aとincomeを表示させる: select(Q47A,income)
dataf %>% filter(is.na(income)) %>% select(ZQ47A,income)
# A tibble: 75 × 2
ZQ47A income
<dbl> <dbl>
1 99 NA
2 99 NA
3 99 NA
4 14 NA
5 99 NA
6 14 NA
7 14 NA
8 14 NA
9 14 NA
10 14 NA
# ℹ 65 more rows
# ℹ Use `print(n = ...)` to see more rowsたしかにZQ47Aで14か99と回答した人のincomeは”NA”(欠損値)に置き換わっています。ついでにincomeの記述統計量も出してみましょう。平均所得は227.2万円、最大値は2000万円であることがわかります。NA's75というのは14あるいは99と回答した人が合計で75人いることを示します。
> summary(dataf$income)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.0 50.0 200.0 227.2 300.0 2000.0 75 同様で他の変数も加工していきます。スクリプト例として、WS-Todai-Youth-Panel.Rを以下に置いておきますので活用してください。
本コラムは「Rによるデータ分析入門」のWEBサポートページとして作成されました。WEBサポートの一覧は以下を参照してください。
WEBサポートの一覧は以下を参照してください。