
[Rによるデータ分析入門]データ読み込みのトラブルシューティング

本コラムではRでデータ読み込む際に生じうるいくつかのトラブルの解決策を紹介します。
桁の大きな数値が入ったCSVファイルを読み込むと文字列として認識されてしまう
桁の大きな数値が入ったデータをCSVファイルに変換し、Rで読み込もうとすると文字列として認識されることがあります。次の例は、世界銀行のWorld Development Indicatorから取得した世界各国のGDPのデータでCSVファイルに変換してあります。たとえばE+11は10の11乗で、一見数値が入っているように見えます。
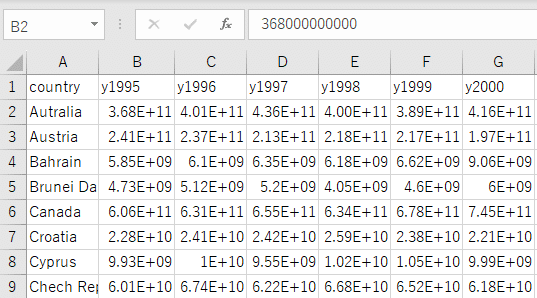
しかし、これをRで読み込むとy2012以降が<chr>になっており、数値が””で囲まれています。
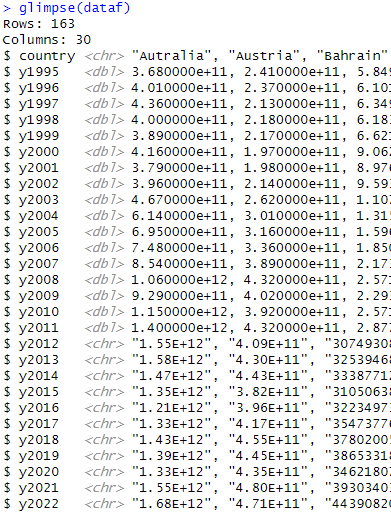
原因は、EXCELからCSVファイルに変換する際に「表示形式」を変換しておかないと「2.00E+11」などの省略表示になる場合があり、一部がCSV上で文字列になり、またこれをRで読むと文字列扱いになります。対処法は2つあります。
対処法1:以下の記事等を参考にEXCELで書式を数値にしてからCSVで保存
対処法2:元のデータがEXCELファイルなら、EXCELファイルから直接読み込む。Rではread_xlsx()という関数でEXCELから直接読み込むことができます。
なお、World Development IndicatorでGDPを取得すると欠損値は".."と表記されるので、これを空白セルにするには、EXCELの「置換」の検索する文字列を..にし、置換後の文字列のところは何も記入しないで全て置換すると簡単に".."を消せます。
Rに読み込ませるためにUTF-8に変換したCSVファイルを再度EXCELで開くと文字化けする
Rで(漢字カナを含む)CSVファイルを読み込む場合、通常CSVファイルはShit-JISとう形式で文字コードが保存されているので、readr:read_csv()で読み込む際にはオプションを付けるか、EXCELでCSVファイルを保存する際にUTF-8形式で文字コードを保存しておく必要があります。
しかし、後者の対処方法をとった場合、CSVファイルを加工するためにEXCELで開くと、今度はEXCEL上で文字化けすることがあります。
そのような場合は、EXCELにファイルがUTF-8形式の文字列を含むことを認識させて開く必要があります。詳しい手順は以下のサイト等を参照してください。
なお、こうした問題が発生するのは漢字カナを含むCSVファイルのみです。トラブルを避けるためにはデータファイルに漢字カナをいれないようにしておくことを薦めます。
本コラムは「Rによるデータ分析入門」のWEBサポートページとして作成されました。WEBサポートの一覧は以下を参照してください。
WEBサポートの一覧は以下を参照してください。