
「AIが数学オリンピック銀メダル」の記事から次世代の生成AIを予測してみた

生成AIは数学が苦手と言われています。簡単な小学生程度の算数でも間違えることがあります。そんな中、Google DeepMindから「AIが数学オリンピック銀メダル相当のスコアを記録」とのリリースがありました。本日はこの記事を基にして、将来の次世代の生成AIを予測してみたいと思います、それでは始めていきましょう。
1、どうやって数学の難問を解いたのか?
今回の成果は以下の通りです。
「私たちは、新しい強化学習ベースの形式的数学推論システムであるAlphaProofと、幾何問題解決システムの改良版であるAlphaGeometry 2を発表します。これらのシステムは、今年の国際数学オリンピック(IMO)の問題6問のうち4問を解き、初めて競技で銀メダリストと同等のレベルを達成しました。」
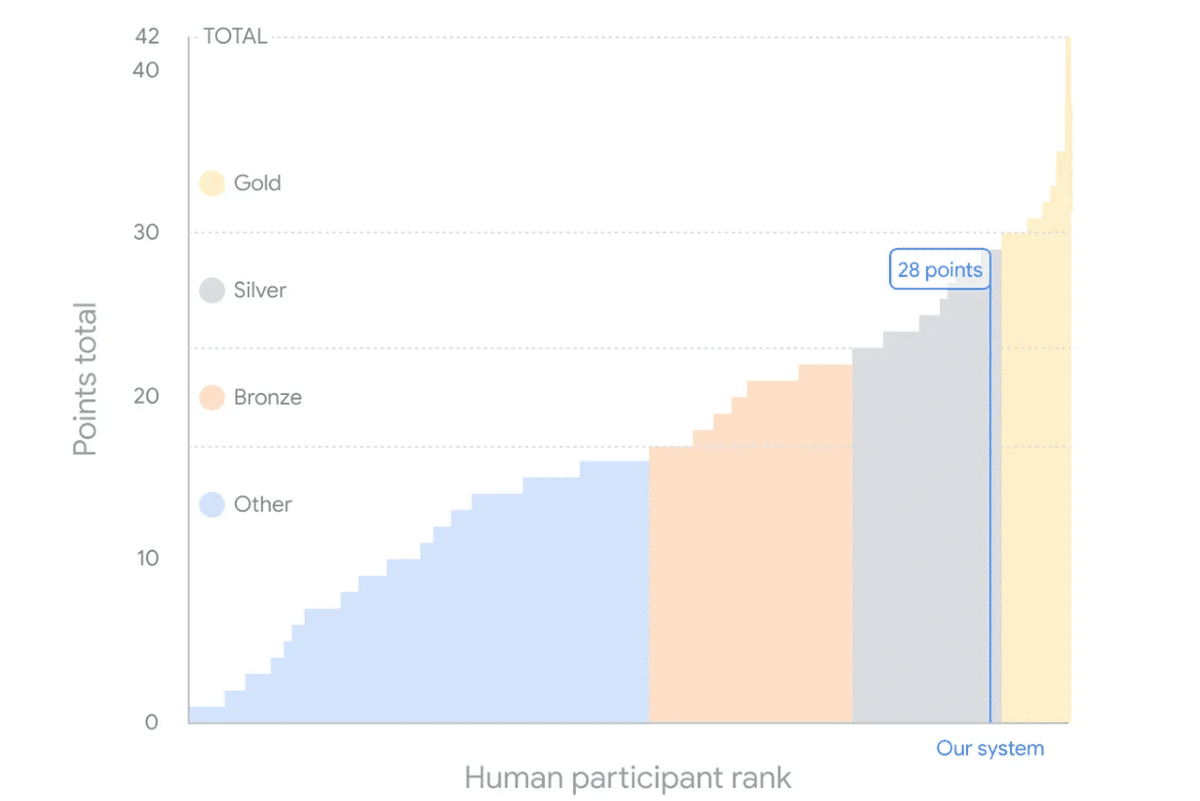
すごいスコアですね。金メダル一歩手前です。今回は2つあるモデルのうち推論システムのAlphaProofを取り上げたいと思います。
AlphaProofは以下の様に説明されています。
「AlphaProofは、形式言語Leanで数学的命題を証明するように自身を訓練するシステムです。これは、事前に訓練された言語モデルと、以前チェス、将棋、囲碁の習得を自身で行ったAlphaZero強化学習アルゴリズムを組み合わせたものです。」
ざっくり言うと、普通の言葉で書かれた数学の問題はデータが沢山あって使いやすいのですが、生成AIはもっともらしく間違えるので(ハルシネーションと呼ばれます)うまく使えない。そこで、Googleの生成AIであるGeminiを使って、数学の問題を一旦形式言語Leanに翻訳し、その形式で、長期の計画・推論が得意なAlphaZeroに取り込んで計算した、といったところでしょうか。下期のチャートがわかりやすいと思います。

AlphaZeroは囲碁をはじめとしたボードゲームでその推論能力を証明済みなので、その能力をうまく数学の世界に持ち込むことができたという訳ですね。凄い !
2、AlphaZeroからのimplication
それでは久しぶりに登場した「AlphaZero」(3)について簡単に復習しておきましょう。RL(強化学習)とMCTS(モンテカルロ・ツリーサーチ)を組み合わせた画期的なAIで、初代のモデルは2016年3月に世界で初めて囲碁棋士のトッププロを破ったAIとして有名になりました。ここで強調したいのは、AlphaZeroは人間が作成データは必要なく、自ら生成したデータで自身を訓練して、人間を超える能力を得たことです。最初にこれを聞いたとき、「どうやってそんなことができるの?」と皆さんきっと不思議に感じることでしょう。AlphaZeroは自分が自分と対戦するというself-playを使って大量の訓練データをを作り出し、それを可能にしています。詳しくはリサーチペーパーを御覧ください。ちなみにAlphaGoはAlphaZeroの最初のバージョンと考えて下さい。
3、現行の生成AIとAlphaGoが融合するとき
実はGoogle DeepMind CEOのDemis Hassabis氏が最近、自社の生成AIの将来像を少し語っています(3)。そのポイントは以下になります。
AIのGeminiは生まれながらのマルチモーダルモデル
言語・画像・映像・音声と、あらゆる世界を理解できる
現行モデルは長期的な計画を立てて、解くことはできない
DeepMindにはこの分野で培った技術(AlphaGo)がある
次世代モデルはGeminiとAlphaGoを融合したagentになる
今回、数学オリンピックで銀メダルを取ったプロジェクトも生成AIが「長期の計画が苦手」なところを克服していく過程の一コマと考えるのが自然なのかも知れません。ただ、「融合と言ってもどうやって?」 と皆さん考えるでしょう。そこで、今年6月に出た有名な長編論文(4)にそのヒントがありそうです。
ステップ1では、AlphaGoは人間の専門家の囲碁の棋譜を模倣学習によって訓練されました。これが基礎となりました。
•ステップ2では、AlphaGoは何百万回も自分自身と対戦しました。これにより、囲碁で人間を超越することができました。イ・セドルとの対戦における有名な 37手目を思い出してください。これは非常に珍しいながらも素晴らしい手で、人間なら決して打たなかったでしょう。 LLM(大規模言語モデル)にとって、ステップ 2に相当するものを開発することは、データの壁を克服するための重要な研究課題です(さらに、最終的には人間レベルの知能を超えるための鍵となります)。
AlphaGoは途中からself-playにより、訓練データそのものも自身で生成してしまい、人間からのinputを必要としなくなりました。「強化学習とMCTS」を組み合わせた素晴らしい成果だと思います。生成AIをこのメカニズムでどう訓練できるかに次世代AIの趨勢がかかってきそうですね。
いかがでしたでしょうか? 長期的な計画が実行できればいろんなことが可能になります。例えば投資のための長期的な戦略策定も可能になるでしょう。裁判での法務アドバイザーなど長期的な議論・ディベートに基づく考えが必要なタスクも得意になると予測されます。世の中が変わっていくことは間違いないでしょう。今からとても楽しみですね。
それでは、今日はこのへんで。Stay tuned!
1) AI achieves silver-medal standard solving International Mathematical Olympiad problems, Google DeepMind, 25 JULY 2024
2)Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, Google DeepMind, 5 DEC 2017
3)Unreasonably Effective AI with Demis Hassabis, Google DeepMind, 14 AUG 2024 (around 18:00)
4) SITUATIONAL AWARENESS p28, The Decade Ahead, Leopold Aschenbrenner, June 2024
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.