
OpenAI o1-previewを見ていると、 「強化学習が、AI開発の主役に躍り出るかも」と思いました!

OpenAI 01 previewが新しい生成AIのパラダイムを拓いて3週間が経過しました。推論時の論理タスクの精度は素晴らしいものがあります。残念ながらそのメカニズムは公開されてませんが、関連する最先端の技術はどうなっているか知りたいですね。幸いなことにヒントになるリサーチペーパー(1)がUniversity of California, Berkeley・Google DeepMindから出ておりましたので、ここでご紹介し、01 previewのメカニズムを想像してみたいと思います。では始めましょう!
OpenAI 01 previewからわかった事、そして最新リサーチペーパー
OpenAI公式サイト(2)によると、2つのことがわかりました。一つは01 previewは「強化学習」を使って機能強化していること。もう一つは「思考の連鎖」を重視し、test time computingを重視していることです。でもこれだけでは、実りある技術論が展開できません。そこで「強化学習」で自然言語処理を行っている最新のリサーチペーパーを見ることにしましょう。いくつかあるリサーチペーパーから、「階層型強化学習」に関連するものを選んでみました。会話が長く続く「マルチターン」の場合にうまく適用できるアルゴリズムだそうです。皆さんもご経験あるかと思いますが、ChatGPTなどを使って情報を取得する場合、一回で希望する結果を得られることはあまり無く、何度か生成AIとやりとりすることが多くなります。こういった場合、生成するtokenあるいは単語数がどんどん増えていきますが、生成AIを効率的に訓練するには難しい状況になってしまいます。そこを新しいアルゴリズムで解決しようという訳です。適用例としては「生成AIアシスタントとの複数ターンにわたる会話終了時の顧客満足度を最大化する」タスクが考えられます。
2.Hierarchical Reinforcement Learning (階層型強化学習)
今回のペーパー(1)で紹介されているアルゴリズムは、「階層型強化学習」と呼ばれ、以下のような階層を持つことが特徴です。
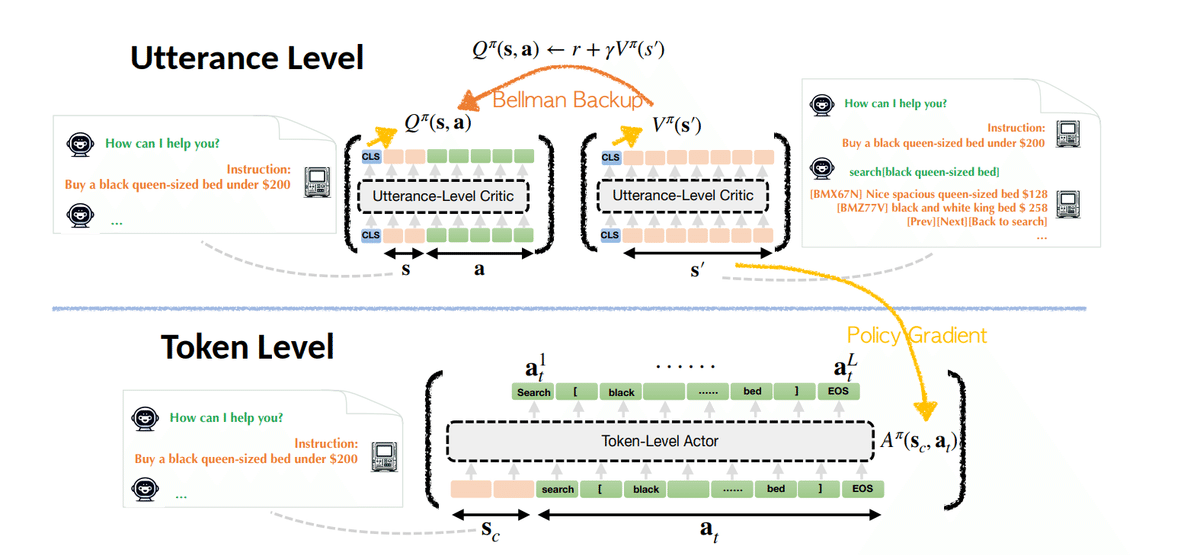
ここで最も注目すべきことはUtterance(発話)レベルとtoken levelといった2層構造になっているところです。発話レベルの言語処理と個々の最小単位のアクションであるtoken levelの処理を分離することは、効率的な訓練を実施するのに大変有効ということです。通常生成AIは"next token prediction"と言われるように、promptの指示を受けて、どんな単語が次に来れば良いかを一生懸命予測しています。その精度は素晴らしく私よりも綺麗な日本語を生成します。ただし、発話が連続する「マルチターン」の場合は、tokenの数が多くなるため訓練が難しくなります。そこでUtterance(発話)レベルの強化学習を行い、報酬はUtterance(発話)レベルで考えます。例えば「webサイトを探索して、必要な情報が取れたら+1、とれなかったら 0」とするなど効率的な訓練ができるように工夫しています。この報酬をもとに、行動価値関数を計算し、それを用いてtoken levelの強化学習を行います。これで大変効率的な訓練が可能になるとのことです。詳細は(1)を御覧ください。
3.「強化学習」設計の自由度
これまで見てきましたように、階層型強化学習は柔軟性があり、設計の自由度がとても大きいと思います。今回は発話レベルの分析とtokenレベルの分析を分離するために使われましたが、その他の機能強化のためにも使われていているようです。例えばGoogle DeepMindから出ているリサーチペーパー(3)は
"大規模言語モデル(LLM)の自己修正能力は非常に望ましいものですが、現代のLLMではあまり効果的でないことが分かっています。既存の自己修正の訓練方法は、複数のモデルを必要とするか、より高性能なモデルやその他の形式の教師データに依存しています。そこで我々は、完全に自己生成データを用いてLLMの自己修正能力を大幅に向上させる、SCoReと呼ばれる複数ターンのオンライン強化学習(RL)手法を開発しました。"
と自己修正能力向上のために、階層型強化学習を使っています。これからも様々なユースケースが出てきそうで期待出来ますね。詳しくは(3)を御覧ください。
いかがでしょうか? o1-previewの評価は日増しに高まっている様子です。今後そのメカニズムの詳細が明らかになる可能性は小さいですが、外部からそれを推測することは、AGIを考える上で大切なことだと思います。次回はo1-previewの適用事例について考えてみたいと思います。それでは今日はこのへんで。Stay tuned!
1) ArCHer: Training Language Model Agents via Hierarchical Multi-Turn, Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, Aviral Kumar, University of California, Berkeley, 1Google DeepMind, Feb 29,2024
2) Introducing OpenAI o1, OpenAI, Sep 12, 2024
3) Training Language Models to Self-Correct via Reinforcement Learning, Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, JD Co-Reyes , Avi Singh , Kate Baumli , Shariq Iqbal , Colton Bishop , Rebecca Roelofs , Lei M Zhang , Kay McKinney , Disha Shrivastava , Cosmin Paduraru , George Tucker , Doina Precup , Feryal Behbahani, Aleksandra Faust, Google DeepMind, Sep 19,2024
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.