BLIP-2を使ってみる

様々なVisual and LanguageのタスクでSoTAを達成しているBLIP-2を試してみたのでメモ。
BLIP-2の概要
Q-FormerというImage EncoderとLLMの橋渡し役を学習させることで両者のギャップを埋める手法。
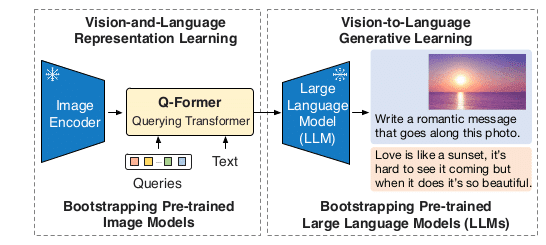
Image EncoderとLLMのレイヤーを凍結させることで他のVision and Languageの手法に比べて低コストで学習可能にも関わらず様々なタスクでSoTAを達成。

実装
transformersにサンプルコードがあったのでそれを参考に以下の画像でBLIP-2を試してみる。
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
if __name__ == '__main__':
model_name = "Salesforce/blip2-opt-6.7b"
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained(model_name)
model = Blip2ForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16
).to(device)
image = Image.open("../data/woman.jpg")
prompt = "Question: What is this person's gender? Answer:"
print(prompt)
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16) # prompt有り
#inputs = processor(images=image, return_tensors="pt").to(device, torch.float16) # promptなし
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)サンプル画像としてphotoACから人差し指を立てて考え事をする若い女性を使用。

結果
blip2-opt-2.7bとblip2-opt-6.7bで試してみた結果です。
blip2-opt-6.7bはメモリの関係上fp16でロードしています。

多少間違えはあるものの画像の特徴を捉えられていることが分かります。
今回の画像やプロンプトではopt-2.7bとopt-6.7bの出力は差が少なく比較になりませんでした…。
所感
シンプルな発想だがかなりいい感じの出力がでる
物体検出と組み合わせたらリッチなラベルが作れそうで面白そうだけど推論時間の関係でリアルタイム処理は難しい