
ControlNet-LLLite学習メモ④

いよいよラフから線画を作るControlNet-LLLite学習チャレンジです。
と、いう予定だったのですがいまいちなんかこう、良い感じになりませんでした。
まぁなんか・・・私には難しかったみたいです。誰かいい感じになんとかしてほしい(他力本願)
そもそもAIくんは線より塗の方が得意ということは前々から言われていましたし、現行AIくんに線画関係のあれこれしてもらおうとするのは酷だったのかもしれません。なにもわからん。
というわけで次作るものはAIが得意なもの、塗を生かせるControlNet-LLLiteを作ろう!ということにしました。
しかし既にcannyはControlNet-LLLiteの産みの親であるKohyaさんが公開してらっしゃいます。
だったらそれと被らないネタ・・・。そうだな、『線を出力しないcannyなんてどうだ!?』となりました。
私のスタンスは基本「AIを手書きお絵描きの補助ツールにしたい」なのですが、現状、AIを使って塗をさせると、元の線画とcannyによって出力された線画がズレます。これは従来のControlNetでもそうでした。
これをなんとか「塗りのみ出力させる機能を持ったcanny」を作れないか実験してみました。
これに必要な画像は
①ベースとなる線画あり画像1000枚
②ベースから抽出した塗りのみ画像1000枚
③ベースから作成したcanny画像
が最低でも必要になります。一番の課題が②でなんとか同じ画像の線画のみ消す方法を探っていたのですが、
AdobePhotoshopの「コンテンツに応じた塗りつぶし」が私の求めている機能に近い、ということがわかりました。しかし私は貧乏人、Adobe税を払っていないのでPhotoshopが使えません。
というわけで何か無料で代用できそうなものを探したところみつけました。
の、ですがライセンスをよくみてみるとCC BY-NC。権利回りがややこしそうです。
ぐぬぬ、となるとしょうがない、払うか!!Adobe税!!!
というわけでAdobeのフォトプラン1か月分を購入しました。サブスクが増えるの嫌だなぁ。
それでは今回のデータセット作成についてまとめていきます。
今回使ったモデルやデータセット
モデル本体
素人が変にマージしたりするよりシンプルな方が良さそうな気がしたからご本家を使用。
LoRAモデル
線画を強調する為に使用
データセット
①ランダムに画像を生成する
python sdxl_gen_img.py --ckpt "C:\stable-diffusion-webui\models\Stable-diffusion\CounterfeitXL-V1.0.safetensors" --n_iter 1 --scale 10 --steps 36 --outdir "D:\desktop\line2shadow\original" --xformers --W 1024 --H 1024 --original_width 2048 --original_height 2048 --bf16 --sampler ddim --batch_size 4 --vae_batch_size 2 --images_per_prompt 512 --max_embeddings_multiples 1 --prompt "((((lineart)))),{ portrait| digital art| anime screen cap| detailed illustration} of { shirt and pants 1girl |sailor uniform 1girl|blazer 1girl |casualwear 1girl |1girl |shirt andpants man, 1boy |school uniform man, 1boy | casualwearl man, 1boy |formalwear man, 1boy |man, 1boy },{standing|contrapposto|sitting|walking|running|dancing} on ((((lineart)))) {mountain|river|forest|cave|lake|waterfall|castle|desert|park|garden|porch of a Japanese house|japanese-style room|shrine|temple|classroom|living|kitchen|bedroom|cafe|hospital|church|library|office|librarystreet|beach|pool|indoors|outdoors|cage|workshop|abandoned house|abandoned factory|penthouse|conservatory|staircase|tavern|medieval tavern|proscenium theater|arena|entrance hall|dance hall|japanese bar|concert hall|night club|diner|restaurant|Jewelry store|fashion boutiques|apparelshop|convenience store|supermarket|indoor pool|conference hall|shopping mall|prison|operating room|auction|Basement,crypt,cellar|Japanese hotel|bookstore|stage|casino|in the movie theatre|mixing_console|laboratory|mansion|jail bars|dungeon|pedestrian deck|terrace|amusement park|pastoral|tunnel|brick pavement|gazebo|water front|water garden|hedge|row of cherry trees|wheat field|paddy field|vegetation|subway station platform|train station platform|steps|festival|palace|rubble ruins|alleyway|frost covered trees|mediterranean|bamboo grove|jungle|underwater|nebula|Cyberpunk|_background,simple_background}, {looking at viewer|looking away|looking at another}, (((solo))), teen age, {0-1$$smile,|blush,|kind smile,|expression less,|happy,|sadness,} {0-1$$upper body,|full body,|cowboy shot,|face focus,} trending on pixiv, {0-2$$depth of fields,|8k wallpaper,|highly detailed,|pov} beautiful face { |, from below|, from above|, from side|, from behind|, from back} --n ((((black tone))), bad anatomy, long_neck, long_body, longbody, deformed mutated disfigured, missing arms, extra_arms, mutated hands, extra_legs, bad hands, poorly_drawn_hands, malformed_hands, missing_limb, floating_limbs, disconnected_limbs, extra_fingers, bad fingers, liquid fingers, poorly drawn fingers, missing fingers, extra digit, fewer digits, ugly face, deformed eyes, partial face, partial head, bad face, inaccurate limb, cropped" --network_module networks.lora --network_weights "C:\stable-diffusion-webui\models\Lora\test-boldline.safetensors" --network_mul 1.0
②画像の線画を抽出する
第一回のMangaLineExtraction_PyTorchを利用するコードを再利用します。
線画抽出できました。

③フォトショップで線なし画像を一括生成する
事前に画像のマスク画像黒い部分を選択するアクションとコンテンツに応じた塗りつぶしを実行するアクションを用意しておきます。

以下のコードを実行。
BatchContentAwareFill.jsx
// フォルダパスを設定
var originalFolder = new Folder("D:/desktop/line2color/original");
var maskFolder = new Folder("D:/desktop/line2color/line");
var outputFolder = new Folder("D:/desktop/line2color/noline");
// 各フォルダ内のPNGファイルを取得
var originalFiles = originalFolder.getFiles("*.png");
var maskFiles = maskFolder.getFiles("*.png");
// ファイル数を確認
if (originalFiles.length !== maskFiles.length) {
alert("Original and mask files count do not match!");
exit();
}
for (var i = 0; i < originalFiles.length; i++) {
// 元画像を開く
var originalDoc = open(originalFiles[i]);
var maskDoc = open(maskFiles[i]);
// 現在のアクティブレイヤーを保存
var originalActiveLayer = originalDoc.activeLayer;
// maskDocで選択してコピー
app.activeDocument = maskDoc; // maskDocをアクティブにする
maskDoc.selection.selectAll();
maskDoc.selection.copy();
// originalDocにペーストしてレイヤーを作成
app.activeDocument = originalDoc; // originalDocをアクティブにする
var newLayer = originalDoc.artLayers.add(); // 新しいレイヤーを追加してその参照をnewLayerに格納
originalDoc.paste(); // コピーした内容をペースト
// 新しくペーストしたレイヤーをアクティブにする
originalDoc.activeLayer = newLayer;
// アクションセットとアクションの名前
var actionSetName = "Noline";
var actionName = "sentaku";
// アクションを実行
app.doAction(actionName, actionSetName);
// 新しいレイヤーを削除
originalDoc.activeLayer.remove();
// 元のアクティブレイヤーを再度アクティブにする
originalDoc.activeLayer = originalActiveLayer;
// コンテンツに応じた塗りつぶしの処理
var actionSetName = "Noline";
var actionName = "Noline";
// アクションを実行
app.doAction(actionName, actionSetName);
// 変更を保存
var outputFile = new File(outputFolder + "/" + originalDoc.name);
originalDoc.saveAs(outputFile, new PNGSaveOptions(), true, Extension.LOWERCASE);
// ドキュメントを閉じる
originalDoc.close(SaveOptions.DONOTSAVECHANGES);
maskDoc.close(SaveOptions.DONOTSAVECHANGES);
}
3時間くらい放置して1096枚の処理終了。結構時間がかかる&CPU負荷が大きいので余裕があるときにやりましょう。

なお後で確認した所、フォトショがなくてもwebUIのインペイント機能使えば似たようなことができました・・・!まぁ今回はフォトショ使っちゃったので・・・!
自分の用途だと色情報は不要なのでグレスケにしました。
import os
import cv2
def convert_to_grayscale(input_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for filename in os.listdir(input_dir):
input_path = os.path.join(input_dir, filename)
if not filename.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
continue
image = cv2.imread(input_path)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
output_path = os.path.join(output_dir, filename)
cv2.imwrite(output_path, gray_image)
if __name__ == "__main__":
input_directory = "D:\\desktop\\noline_canny\\noline"
output_directory = "D:\\desktop\\noline_canny\\grayscale"
convert_to_grayscale(input_directory, output_directory)

④キャプションを生成する
以下のようなスクリプトでキャプションファイルを作成する。(『lineart』という文字列を除去している)
import glob
import os
from PIL import Image
IMAGES_DIR = "D:\\desktop\\noline_canny\\original"
def remove_special_chars(text, char):
# 指定された文字を削除
return text.replace(char, '')
img_files = glob.glob(IMAGES_DIR + "/*.png")
for img_file in img_files:
cap_file = img_file.replace(".png", ".txt")
if os.path.exists(cap_file):
print(f"Skip: {img_file}")
continue
print(img_file)
img = Image.open(img_file)
prompt = img.text["prompt"] if "prompt" in img.text else ""
if prompt == "":
print(f"Prompt not found in {img_file}")
# 特定の文字列を削除
prompt = remove_special_chars(prompt, '{')
prompt = remove_special_chars(prompt, '}')
prompt = remove_special_chars(prompt, '(')
prompt = remove_special_chars(prompt, ')')
prompt = remove_special_chars(prompt, ' ')
prompt = remove_special_chars(prompt, ' ')
prompt = remove_special_chars(prompt, ' ')
prompt = remove_special_chars(prompt, 'lineart,')
prompt = remove_special_chars(prompt, 'lineart ')
prompt = prompt.replace(',,', ',')
prompt = prompt.replace(' ,', ',')
with open(cap_file, "w") as f:
f.write("monochrome, greyscale, "+prompt + "\n") # 改行文字は "\n" です⑤cannyを作成する
上記のスクリプトそのまんま採用。①の生成画像から抽出しました。
import glob
import os
import cv2
import numpy as np
from PIL import Image
IMAGES_DIR = "D:/desktop/line2color/original"
CANNY_DIR = "D:/desktop/line2color/canny"
os.makedirs(CANNY_DIR, exist_ok=True)
img_files = glob.glob(IMAGES_DIR + "/*.png")
for img_file in img_files:
print(img_file)
img = cv2.imread(img_file, cv2.IMREAD_GRAYSCALE) # グレースケールで画像を読み込む
# Cannyエッジ検出を適用
edges = cv2.Canny(img, 50, 110)
# 出力ファイルのパスを作成
file_name = os.path.basename(img_file)
canny_file = os.path.join(CANNY_DIR, file_name)
# 画像を保存
cv2.imwrite(canny_file, edges)
⑥sd-scriptsで学習


上記二種類の画像1000枚セットをそれぞれ、image_dir、conditioning_data_dirに設定して、この二つの画像から制御を学習します。
学習環境作りはControlNet-LLLite学習メモ③を参照。noline_canny_config.toml
pretrained_model_name_or_path = "C:/stable-diffusion-webui/models/Stable-diffusion/CounterfeitXL-V1.0.safetensors"
max_train_epochs = 40
max_data_loader_n_workers = 4
persistent_data_loader_workers = true
seed = 42
gradient_checkpointing = true
mixed_precision = "bf16"
save_precision = "bf16"
full_bf16 = false
optimizer_type = "adamw8bit"
learning_rate = 2e-4
xformers = true
output_dir = "C:/sd-scripts/models/noline_canny"
output_name = "noline_canny"
save_every_n_epochs = 1
save_state = true
save_model_as = "safetensors"
vae_batch_size = 4
cache_latents = true
cache_latents_to_disk = true
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = true
network_dim = 64
cond_emb_dim = 32
dataset_config = "noline_canny_dataset.toml"noline_canny_dataset.toml
[general]
flip_aug = false
color_aug = false
resolution = [1024,1024]
[[datasets]]
batch_size = 16
enable_bucket = false
[[datasets.subsets]]
image_dir = "D:/desktop/CounterfeitXL-V1.0_canny_noline_dataset/grayscale"
caption_extension = ".txt"
conditioning_data_dir = "D:/desktop/CounterfeitXL-V1.0_dataset_canny_noline/canny"sdxl_train_control_net_lllite_alt.pyを使用。
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_control_net_lllite_alt.py --config_file nl_canny_config.tomlRTX3090で40epoch。6時間ほど待ちます。
⑦推論
以下の条件で推論します。

Prompt
monochrome, greyscale, 1girl, solo, breasts, looking_at_viewer, smile, short_hair, full_body, pants, coat, waving, simple_background, white_background --n black, bad anatomy,long_neck,long_body,longbody,deformed mutated disfigured,missing arms,extra_arms,mutated hands,extra_legs,bad hands,poorly_drawn_hands,malformed_hands,missing_limb,floating_limbs,disconnected_limbs,extra_fingers,bad fingers,liquid fingers,poorly drawn fingers,missing fingers,extra digit,fewer digits,ugly face,deformed eyes,partial face,partial head,bad face,inaccurate limb,croppedpython sdxl_gen_img.pyを以下のようなオプションで実行
python sdxl_gen_img.py --ckpt "C:\stable-diffusion-webui\models\Stable-diffusion\CounterfeitXL-V1.0.safetensors" --control_net_lllite_models "C:\sd-scripts\models\nl_canny\nl_canny-000040.safetensors" --guide_image_path "D:\desktop\tori29umai_line_canny\1_canny.png" --outdir "output" --from_file "D:\desktop\tori29umai_line_canny\1.txt" --bf16 --xformers --seed 1234 --W 768 --H 1344
うんうん。学習できています。ただ若干制御が足りていない感じかも?



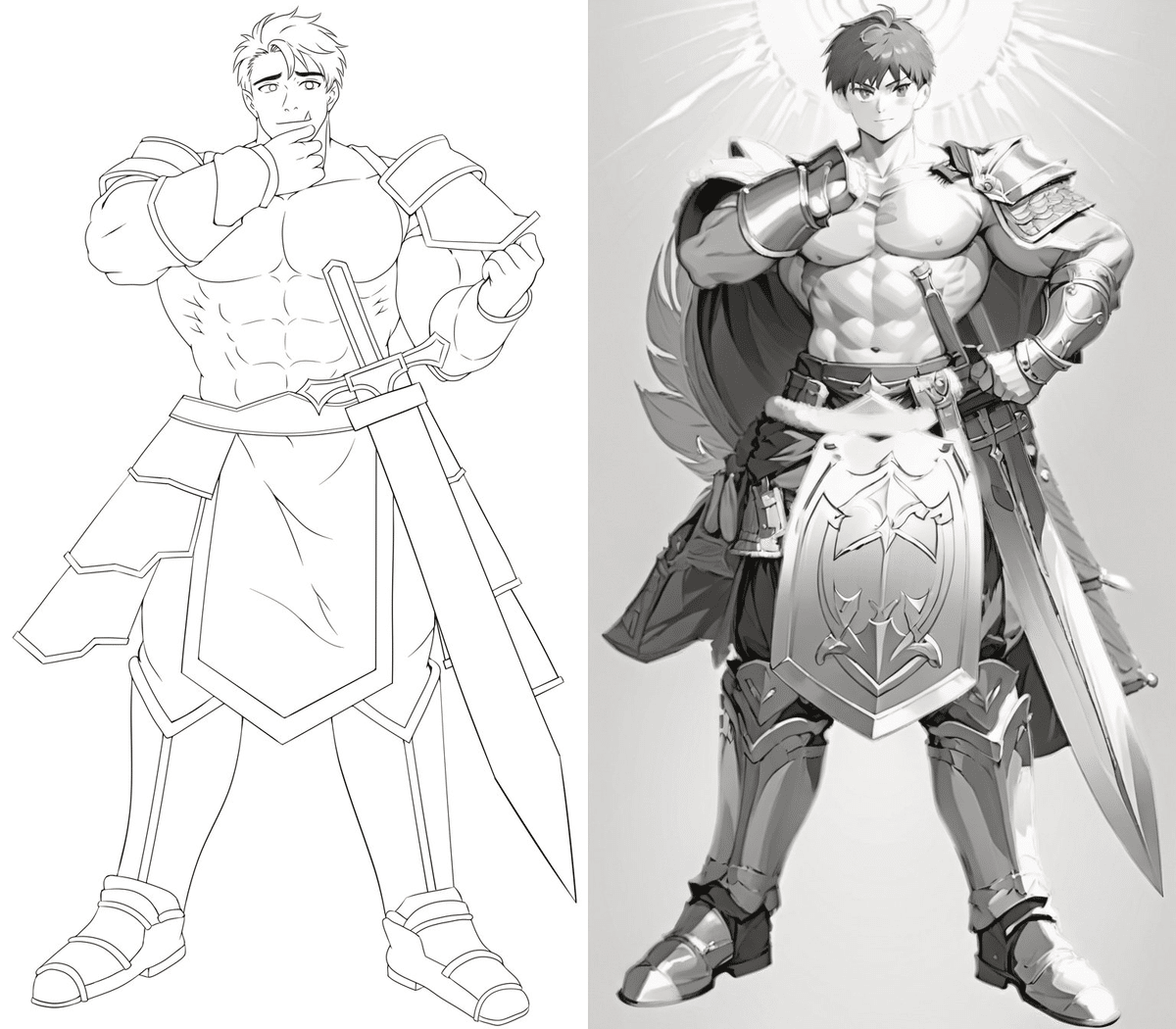


うーーーーーん、この・・・・・・そうじゃないんだよ感・・・・・・。
とりあえず、110epochになるまでぶん回してみました。
結果、ダメでした。理由はおそらく過学習。
ううううーん。もうここは既存のcannyに線画を無くすLoRAを掛け合わせてみますか(ついでにマイナス適用で書き込みもさせるLoRAも)
python sdxl_gen_img.py ^
--ckpt "C:\stable-diffusion-webui\models\Stable-diffusion\CounterfeitXL-V1.0.safetensors" ^
--control_net_lllite_models "C:\sd-scripts\models\controllllite_v01032064e_sdxl_canny_anime.safetensors" ^
--guide_image_path "D:\desktop\tori29umai_line_canny\1_canny.png" ^
--outdir "output" ^
--from_file "D:\desktop\tori29umai_li1ne_canny\1.txt" ^
--bf16 ^
--xformers ^
--seed 1234 ^
--W 768 ^
--H 1344 ^
--textual_inversion_embeddings "C:\stable-diffusion-webui\embeddings\negativeXL_D.safetensors" ^
--image_path "D:\desktop\tori29umai_line_canny\base.png" ^
--network_module networks.lora networks.lora ^
--network_weights "C:\stable-diffusion-webui\models\Lora\test-noline.safetensors" "C:\stable-diffusion-webui\models\Lora\test-flat.safetensors" ^
--network_mul 2.5 -1.5結果
あーーーーかなりよいなこれ pic.twitter.com/kVSOVOZsJl
— とりにく (@tori29umai) September 3, 2023
ケモみが強くなるのはプロンプトで調整かな?SDXLはpromptの影響が大きいな。
— とりにく (@tori29umai) September 3, 2023
もうちょいllliteの裁量が大きくなってほしい気もするが難しいんだろなまぁ陰影の下書きとしては十分 pic.twitter.com/LmkHq2QLSM
うんうん、あくまで下書きや参考用だね(光源の指定もできないし pic.twitter.com/BjOBbc5iOZ
— とりにく (@tori29umai) September 3, 2023
やっぱり男性陣は若干苦手な感じかな(美少女の方がデータ量多いんだろな pic.twitter.com/NY4CfNiIsF
— とりにく (@tori29umai) September 3, 2023
男性陣、やたらどすけべになるな・・・ pic.twitter.com/6IDse2Xgej
— とりにく (@tori29umai) September 3, 2023
君はむちむち筋肉にはならなくてちょっとほっとした(すきだけど pic.twitter.com/QbeFsedQxA
— とりにく (@tori29umai) September 3, 2023
結論
既存のcannyにLoRA掛け合わせた方がいい感じになるわ!!!!!!!!!!!!!!!!!!!!!!!!!!!!!