
自作ControlNetモデル開発記録①

そろそろ自分なりに知見がたまってきたので作り方をまとめます。
CotrolNet学習関係の過去記事は以下。
そもそもControlNetってなんぞやと滅茶苦茶簡単にいいますと、sourceフォルダに格納された画像とtargetフォルダの画像の関係性を学ぶ技術っぽいです。詳しくは知らんけど。
つまりこういう画像(ソースフォルダ)と

こういう画像(ターゲット)をセットで学習することで

ControlNetで線画を読み込めば
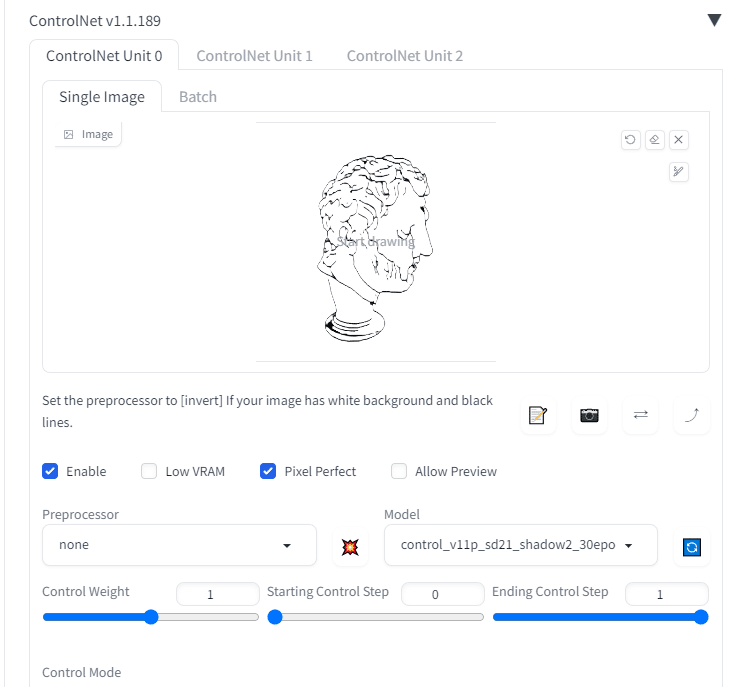
陰影を描いてくれる。そんな技術です。

このような学習をしてくれるのです。自分は前回までこういう光源の向きを意味する情報も一緒に紐づけて学習させようとしていたのですが、この光源の向き情報に関しては学習することはありませんでした。

故に順光、逆光、サイド光(左右)のレンダリング画像をそれぞれ別に学習させて、各種光の向きに特化したControlNetモデルを作ろう、というのが新しい目標です。
今回は順光(前からの光)のモデルを作っていく過程でControlNet学習の解説をしていきたいと思います。という訳でデータセット作成から書いていきたいと思います。
①CC0の3Dモデルを収集する
自分はMyMiniFactoryというサイトのCC0の彫刻3DモデルをDLしました。
配布されているモデル全てを利用したわけではなく、タペストリーや欠損の激しいもの、造形が抽象的なものは意図的に候補から外しました。
結果、
SMK-Statens Museum for Kunst様より267点
Nationalmuseum様より58点
ThorvaldsensMuseum56点
計381点の3Dモデルをお借りしました。
②stlからobjへの一括変換、及びサイズ変更
上記のサイトでこれらのモデルはstl形式で配布されているのですが、そのままでは撮影に使うUnityで読み込めません。
その為、obj形式に変換する必要があります。
obj形式に変換する為、以下のBlenderのPythonコンソールで動くコードで変換とモデルの座標と大きさの調整をしました。
381点もあると数時間かかるので気長に待ちましょう。
3D_conv.py
import bpy
import glob
import os
modelpath = 'D:/desktop/models/'
# modelpath フォルダ内の .stl、.fbx、.objファイルの絶対パスを取得
files = glob.glob(modelpath + '*.stl') + glob.glob(modelpath + '*.fbx') + glob.glob(modelpath + '*.obj')
outpath = 'D:/desktop/obj/'
# エクスポート先のフォルダが存在しない場合にのみ作成する
if not os.path.exists(outpath):
os.makedirs(outpath)
# Blenderのパフォーマンスを向上させる設定
bpy.context.scene.use_audio = False
bpy.context.scene.render.use_lock_interface = False
bpy.context.scene.render.use_simplify = True
total_files = len(files)
processed_files = 0
skipped_files = [] # スキップされたファイル名を格納するリスト
for file in files:
try:
print(f'Processing file {processed_files+1}/{total_files}: {file}') # 処理の進行状況を表示
# 出力ファイルのパスを生成する
name = os.path.splitext(os.path.basename(file))[0]
file_out = os.path.join(outpath, name + '.obj')
mtl_file_out = os.path.join(outpath, name + '.mtl')
print(' [export] ' + file_out)
# 出力先のファイルが既に存在する場合はスキップする
if os.path.exists(file_out):
print(' [skip] ファイルは既に存在しています。エクスポートをスキップします。')
processed_files += 1
continue
# コレクション内のオブジェクトをクリアする
bpy.ops.object.select_all(action='DESELECT')
bpy.ops.object.select_by_type(type='MESH')
bpy.ops.object.delete()
# ファイルをインポートする
if file.endswith('.fbx'):
bpy.ops.import_scene.fbx(filepath=file)
elif file.endswith('.stl'):
bpy.ops.import_mesh.stl(filepath=file)
elif file.endswith('.obj'):
bpy.ops.import_scene.obj(filepath=file)
obj = bpy.context.selected_objects[0] # 最初のオブジェクトを選択
# スケール変換のための比率を計算する
dimensions = obj.dimensions
if any(dim == 0.0 for dim in dimensions):
raise ValueError('Invalid dimensions')
scale_factor = 120.0 / max(dimensions)
# オブジェクトの寸法を変更する
obj.scale = (scale_factor, scale_factor, scale_factor)
# オブジェクトの原点をジオメトリの中心に移動する
bpy.ops.object.origin_set(type='ORIGIN_CENTER_OF_MASS', center='BOUNDS')
# オブジェクトの位置を調整する
obj.location = (0.0, 0.0, 0.0)
# オブジェクトを更新
obj.update_tag()
# シーンを更新
bpy.context.view_layer.update()
mesh = obj.data
vertices = [obj.matrix_world @ v.co for v in mesh.vertices]
min_z = min(vertices, key=lambda v: v[2])[2]
# オブジェクトを移動してz座標を0にする
obj.location.z += abs(min_z)
bpy.ops.object.transform_apply(location=True, rotation=True, scale=True)
# 3Dカーソルの座標を原点にする
bpy.context.scene.cursor.location = (0.0, 0.0, 0.0)
# obj形式でエクスポートする
bpy.ops.export_scene.obj(filepath=file_out)
# MTLファイルが存在する場合は削除する
if os.path.exists(mtl_file_out):
os.remove(mtl_file_out)
print(f' [deleted] MTLファイル: {mtl_file_out}')
# オブジェクトを削除する
bpy.ops.object.select_all(action='DESELECT')
bpy.ops.object.select_by_type(type='MESH')
bpy.ops.object.delete()
processed_files += 1
print(f'Processing file {processed_files}/{total_files}')
except Exception as e:
skipped_files.append(file)
print(f'Skipping file {processed_files+1}/{total_files}: {file} - Error: {str(e)}')
processed_files += 1
continue
print("done!")
print("Skipped files:")
for skipped_file in skipped_files:
print(skipped_file)
上記のコードの使い方は以下の記事が参考になると思います。
③変換したファイルをUnityに読み込む
Unityで新規3Dプロジェクトを立ち上げ、下記のリンクのリポジトリをコピーする。
Resourcesフォルダに以下の3つのobjファイルが格納されたフォルダをコピー(インポートするのに数時間かかりますので覚悟するように)。
SMK-Statens_Museum_for_Kunst
Nationalmuseum
ThorvaldsensMuseum

Unityに読み込まれたらProject画面を拡大して、何故か横向きに倒れているモデルを探します。

倒れているモデル名を手動で修正していきます。
CotrolNet_Shadowシーンを開き、
Hierarchy→System→LightCaptureから
outpath:画像の出力先(例:D:\desktop\output)
maxCount:出力画像枚数(例:10000)
Random_Capture:ランダム撮影するか(今回の用途だとチェックを入れる)
と設定してください。他はデフォルトでいいです。
設定ができたらシーンを実行。数時間かけて1万枚レンダリングされます。
設定したアウトプット先に
back(逆光)
front(順光)
left(左からの光)
right(右からの光)
の計4万枚の画像が格納されたフォルダができています。今回はfrontを学習させます。
"D:/desktop/output/front"の名前を"D:/desktop/output/target"に変えておきましょう。
④レンダリングした画像の線画を抽出する
線画抽出するのにinformative-drawingsを使う。
自分はなんとなくAnacondaを使いたくないのでvenvで仮想環境作成しました。
cd C:\
git clone https://github.com/carolineec/informative-drawings
cd C:\informative-drawings
python -m venv env
env\Scripts\activate.bat
python -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
pip install numpy scipy tensorboard pillow opencv-python scikit-learn oyaml dominate ninja ftfy tqdm regexC:\informative-drawings\checkpointsフォルダを作り、model.zipをDLし解凍。
画像のように配置する。
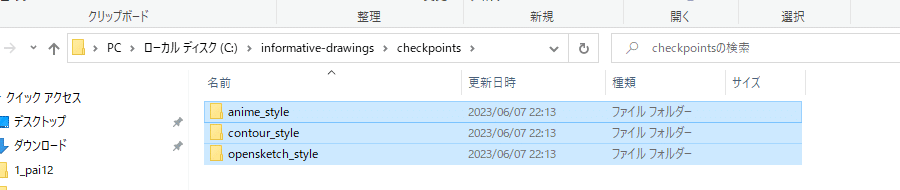
informative-drawingsフォルダに以下のスクリプトを配置
LineConvert.py
# -*- coding: utf-8 -*-
#!/usr/bin/python3
import cv2
import numpy as np
import argparse
import sys
import os
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torch
from model import Generator, GlobalGenerator2, InceptionV3
from dataset import UnpairedDepthDataset
from PIL import Image
import numpy as np
from utils import channel2width
parser = argparse.ArgumentParser()
parser.add_argument('--name', required=True, type=str, help='name of this experiment')
parser.add_argument('--checkpoints_dir', type=str, default='checkpoints', help='Where the model checkpoints are saved')
parser.add_argument('--results_dir', type=str, default='results', help='where to save result images')
parser.add_argument('--geom_name', type=str, default='feats2Geom', help='name of the geometry predictor')
parser.add_argument('--batchSize', type=int, default=1, help='size of the batches')
parser.add_argument('--dataroot', type=str, default='', help='root directory of the dataset')
parser.add_argument('--depthroot', type=str, default='', help='dataset of corresponding ground truth depth maps')
parser.add_argument('--input_nc', type=int, default=3, help='number of channels of input data')
parser.add_argument('--output_nc', type=int, default=1, help='number of channels of output data')
parser.add_argument('--geom_nc', type=int, default=3, help='number of channels of geometry data')
parser.add_argument('--every_feat', type=int, default=1, help='use transfer features for the geometry loss')
parser.add_argument('--num_classes', type=int, default=55, help='number of classes for inception')
parser.add_argument('--midas', type=int, default=0, help='use midas depth map')
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in first conv layer')
parser.add_argument('--n_blocks', type=int, default=3, help='number of resnet blocks for generator')
parser.add_argument('--size', type=int, default=512, help='size of the data (squared assumed)')
parser.add_argument('--cuda', action='store_true', help='use GPU computation', default=True)
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load from')
parser.add_argument('--aspect_ratio', type=float, default=1.0, help='The ratio width/height. The final height of the load image will be crop_size/aspect_ratio')
parser.add_argument('--mode', type=str, default='test', help='train, val, test, etc')
parser.add_argument('--load_size', type=int, default=512, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=512, help='then crop to this size')
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization')
parser.add_argument('--predict_depth', type=int, default=0, help='run geometry prediction on the generated images')
parser.add_argument('--save_input', type=int, default=0, help='save input image')
parser.add_argument('--reconstruct', type=int, default=0, help='get reconstruction')
opt = parser.parse_args()
print(opt)
opt.no_flip = True
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
def count_png_files(directory):
count = 0
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(".png"):
count += 1
return count
def thinning(image_path, output_path, kernel_size=(1, 1), iterations=2):
# 画像の読み込み (白背景に黒線の線画)
img = cv2.imread(image_path, 0)
# 反転処理
inverted = cv2.bitwise_not(img)
# カーネルの定義
kernel = np.ones(kernel_size, np.uint8)
# 収縮処理 (線を細くする)
erosion = cv2.erode(inverted, kernel, iterations=iterations)
# 反転処理
result = cv2.bitwise_not(erosion)
# 結果の保存
cv2.imwrite(output_path, result)
###################################
with torch.no_grad():
# Networks
net_G = 0
net_G = Generator(opt.input_nc, opt.output_nc, opt.n_blocks)
net_G.cuda()
net_GB = 0
if opt.reconstruct == 1:
net_GB = Generator(opt.output_nc, opt.input_nc, opt.n_blocks)
net_GB.cuda()
net_GB.load_state_dict(torch.load(os.path.join(opt.checkpoints_dir, opt.name, 'netG_B_%s.pth' % opt.which_epoch)))
net_GB.eval()
netGeom = 0
if opt.predict_depth == 1:
usename = opt.name
if (len(opt.geom_name) > 0) and (os.path.exists(os.path.join(opt.checkpoints_dir, opt.geom_name))):
usename = opt.geom_name
myname = os.path.join(opt.checkpoints_dir, usename, 'netGeom_%s.pth' % opt.which_epoch)
netGeom = GlobalGenerator2(768, opt.geom_nc, n_downsampling=1, n_UPsampling=3)
netGeom.load_state_dict(torch.load(myname))
netGeom.cuda()
netGeom.eval()
numclasses = opt.num_classes
### load pretrained inception
net_recog = InceptionV3(opt.num_classes, False, use_aux=True, pretrain=True, freeze=True, every_feat=opt.every_feat==1)
net_recog.cuda()
net_recog.eval()
# Load state dicts
net_G.load_state_dict(torch.load(os.path.join(opt.checkpoints_dir, opt.name, 'netG_A_%s.pth' % opt.which_epoch)))
print('loaded', os.path.join(opt.checkpoints_dir, opt.name, 'netG_A_%s.pth' % opt.which_epoch))
# Set model's test mode
net_G.eval()
transforms_r = [transforms.Resize(int(opt.size), Image.BICUBIC),
transforms.ToTensor()]
test_data = UnpairedDepthDataset(opt.dataroot, '', opt, transforms_r=transforms_r,
mode=opt.mode, midas=opt.midas>0, depthroot=opt.depthroot)
dataloader = DataLoader(test_data, batch_size=opt.batchSize, shuffle=False)
png_count = count_png_files(opt.dataroot)
digits = len(str(png_count)) # 桁数を取得
###################################
###### Testing######
full_output_dir = opt.results_dir
if not os.path.exists(full_output_dir):
os.makedirs(full_output_dir)
for i, batch in enumerate(dataloader):
if i > png_count:
break;
img_r = Variable(batch['r']).cuda()
img_depth = Variable(batch['depth']).cuda()
real_A = img_r
name = batch['name'][0]
input_image = real_A
image = net_G(input_image)
filepath = os.path.join(opt.results_dir, '%s.png' % name)
save_image(image.data, filepath)
thinning(filepath, filepath, kernel_size=(2, 2), iterations=2)
if opt.predict_depth == 1:
geom_input = image
if geom_input.size()[1] == 1:
geom_input = geom_input.repeat(1, 3, 1, 1)
_, geom_input = net_recog(geom_input)
geom = netGeom(geom_input)
geom = (geom+1)/2.0 ###[-1, 1] ---> [0, 1]
input_img_fake = channel2width(geom)
save_image(input_img_fake.data, os.path.join(opt.results_dir, '%s_geom.png' % name))
if opt.reconstruct == 1:
rec = net_GB(image)
save_image(rec.data, os.path.join(opt.results_dir, '%s_rec.png' % name))
if opt.save_input == 1:
sys.stdout.write('\rGenerated images %0{}d of %0{}d'.format(digits, digits) % (i, png_count))
sys.stdout.write('\rGenerated images %0{}d of %0{}d'.format(digits, digits) % (i, png_count))
sys.stdout.write('\n')
以下のコマンドを実行
python LineConvert.py --name contour_style --dataroot "線画にした画像のパス" --results_dir "出力フォルダ"具体例は以下。
python LineConvert.py --name contour_style --dataroot "D:/desktop/output/target" --results_dir "D:/desktop/output/source"これでD:/desktop/output/targetをベースにした線画がD:/desktop/output/sourceフォルダに出力されます。
これでControlNetの学習に使えるデータセットのtargetフォルダとsourceフォルダはそろいました。あとはprompt情報だけです。
【追記:2023/6/30】
10000枚以上の画像を処理しようとするとストップがかかる為、informative-drawings/dataset.pyの31行目
def make_dataset(dir, stop=10000):
を
def make_dataset(dir, stop=50000):
とでも変えておきましょう。
⑤promptを自動生成する
informative-drawingsフォルダに以下のスクリプトを配置
generate_prompt.py
import argparse
import csv
import os
import json
from PIL import Image
import cv2
import numpy as np
from tensorflow.keras.models import load_model
from huggingface_hub import hf_hub_download
from pathlib import Path
# from wd14 tagger
IMAGE_SIZE = 448
# wd-v1-4-swinv2-tagger-v2 / wd-v1-4-vit-tagger / wd-v1-4-vit-tagger-v2/ wd-v1-4-convnext-tagger / wd-v1-4-convnext-tagger-v2
DEFAULT_WD14_TAGGER_REPO = "SmilingWolf/wd-v1-4-convnext-tagger-v2"
FILES = ["keras_metadata.pb", "saved_model.pb", "selected_tags.csv"]
SUB_DIR = "variables"
SUB_DIR_FILES = ["variables.data-00000-of-00001", "variables.index"]
CSV_FILE = FILES[-1]
def preprocess_image(image):
image = np.array(image)
image = image[:, :, ::-1] # RGB->BGR
# pad to square
size = max(image.shape[0:2])
pad_x = size - image.shape[1]
pad_y = size - image.shape[0]
pad_l = pad_x // 2
pad_t = pad_y // 2
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode="constant", constant_values=255)
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
image = image.astype(np.float32)
return image
def load_wd14_tagger_model():
model_dir = "wd14_tagger_model"
repo_id = DEFAULT_WD14_TAGGER_REPO
if not os.path.exists(model_dir):
print(f"downloading wd14 tagger model from hf_hub. id: {repo_id}")
for file in FILES:
hf_hub_download(repo_id, file, cache_dir=model_dir, force_download=True, force_filename=file)
for file in SUB_DIR_FILES:
hf_hub_download(
repo_id,
file,
subfolder=SUB_DIR,
cache_dir=os.path.join(model_dir, SUB_DIR),
force_download=True,
force_filename=file,
)
else:
print("using existing wd14 tagger model")
# モデルを読み込む
model = load_model(model_dir)
return model
def generate_tags(image_path, model_dir, model):
with open(os.path.join(model_dir, CSV_FILE), "r", encoding="utf-8") as f:
reader = csv.reader(f)
l = [row for row in reader]
header = l[0] # tag_id,name,category,count
rows = l[1:]
assert header[0] == "tag_id" and header[1] == "name" and header[2] == "category", f"unexpected csv format: {header}"
general_tags = [row[1] for row in rows[1:] if row[2] == "0"]
character_tags = [row[1] for row in rows[1:] if row[2] == "4"]
tag_freq = {}
undesired_tags = ["monochrome", "lineart", "greyscale"]
def run_batch(path_imgs):
imgs = np.array([im for _, im in path_imgs])
probs = model(imgs, training=False)
probs = probs.numpy()
for (image_path, _), prob in zip(path_imgs, probs):
combined_tags = []
general_tag_text = ""
character_tag_text = ""
thresh = 0.35
for i, p in enumerate(prob[4:]):
if i < len(general_tags) and p >= thresh:
tag_name = general_tags[i]
if tag_name not in undesired_tags:
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
general_tag_text += ", " + tag_name
combined_tags.append(tag_name)
elif i >= len(general_tags) and p >= thresh:
tag_name = character_tags[i - len(general_tags)]
if tag_name not in undesired_tags:
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
character_tag_text += ", " + tag_name
combined_tags.append(tag_name)
if len(general_tag_text) > 0:
general_tag_text = general_tag_text[2:]
if len(character_tag_text) > 0:
character_tag_text = character_tag_text[2:]
tag_text = ", ".join(combined_tags)
return tag_text
b_imgs = []
image = Image.open(image_path) # Use absolute path
if image.mode != "RGB":
image = image.convert("RGB")
image = preprocess_image(image)
b_imgs.append((image_path, image))
tag = run_batch(b_imgs)
return tag
def generate_prompt_json(target_folder, prompt_file, model_dir, model):
image_files = [f for f in os.listdir(target_folder) if os.path.isfile(os.path.join(target_folder, f))]
image_count = len(image_files)
prompt_list = []
for i in range(1, image_count + 1):
filename = f"{str(i).zfill(5)}.png"
source_path = "source/" + filename
target_path = os.path.join(target_folder, filename) # Use absolute path
target_path2 = "target/" + filename
prompt = generate_tags(target_path, model_dir, model)
prompt_data = {
"source": source_path,
"target": target_path2,
"prompt": prompt
}
prompt_list.append(prompt_data)
print(f"Processed Images: {i}/{image_count}", end="\r", flush=True)
with open(prompt_file, "w") as file:
for prompt_data in prompt_list:
json.dump(prompt_data, file)
file.write("\n")
print(f"Processing completed. Total Images: {image_count}")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--target_folder', required=True, default=r'D:\desktop\output\Shadow_Front\target', type=str, help='画像ファイルが含まれるフォルダのパス')
parser.add_argument('--prompt_file', required=True, default=r'D:\desktop\output\Shadow_Front\prompt.json', type=str, help='prompt.json ファイルの保存先パス')
args = parser.parse_args()
target_folder = args.target_folder
prompt_file = args.prompt_file
model_dir = "wd14_tagger_model"
model = load_wd14_tagger_model()
generate_prompt_json(target_folder, prompt_file, model_dir, model)generate_prompt.pyを実行する前にライブラリをインストールする必要があります。
cd C:\informative-drawings
env\Scripts\activate.bat
python -m pip install "tensorflow<2.11"
pip install keras
pip install huggingface-hub上記ライブラリがインストールできたら、以下のコードを実行します。
python generate_prompt.py --target_folder ”元画像フォルダ” --prompt_file ”prompt.jsonの保存先”具体例
python generate_prompt.py --target_folder "D:/desktop/output/target" --prompt_file "D:/desktop/output/prompt.json"例によって数時間かかります。メンタルに悪い。
これでD:/desktop/outputフォルダに
targetフォルダ
sourceフォルダ
prompt.json
が生成されるので、上記のファイルをShadow_Front.zipという名前でzipにまとめ保存します。
これでようやくデータセットの準備が整いました。
次回に続く!!!