
電力会社からデータを取得してCSV形式で保存(Python WEBスクレイピング)

WEBから収集したデータを分析して、機械学習やマーケティングなどに活用できたら面白いなと思って、PythonでWEBスクレイピングをやってみました。
本記事では、電力会社から過去の電力使用実績データを取得してCSV形式で保存する内容をやっていきます。
開発環境
・windows 10(64bit)
・Visual Studio Code 1.48.0
・python 3.8.2(32bit版)
・Google Chrome
データ取得元
東京電力パワーグリッドから「過去の電力使用実績データ」を取得してCSVに保存します。今回は2019年の1年間における1時間ごとのデータを取得します。

実行結果
Python でWEBスクレイピングして電力使用データを取得してCSVに保存した結果が以下になります。日本語表記の部分が文字化けしていますが、この解決策は検討中です。こちらのページを参考にしましたが、上手くいきませんでした。とりあえず、欲しい数値データは取得できているので今回はOKとしました。
肝心のデータですが、2019年の1時間ごとの電力使用実績データが取得できています。本記事では行っていませんが、このデータをもとに機械学習などをやってみたいと考えています。

手順の解説
全体のソースコードは最後に添付します。ソースコードの各部を順番に解説していきます。
まず、必要なライブラリをインポートします。
# csvファイルライブラリ
import csv
# HTTP 通信ライブラリ
import requests
# HTMLデータ抽出ライブラリ
from bs4 import BeautifulSoup次に指定したURLからHTMLのデータを取得します。
# 指定したURLのHTML取得
urlName = "https://www.tepco.co.jp/forecast/html/images/juyo-2019.csv"
dataHTML = requests.get(urlName)そして、Beautiful SoupでHTMLを解析して、テキストのみを抽出します。
# Beautiful SoupでHTML解析
soup = BeautifulSoup(dataHTML.content, "html.parser")
# HTMLデータからテキストのみ抽出
data = soup.textここから、データを加工していきます。
なぜ、データを加工するのかというと、この状態で「print(data)」を実行して出力すると以下のようなデータが出力されます。このままCSVに書き込みしようとすると、1行にこれらのデータが入力されてしまいます。
2019/12/31,18:00,3311
2019/12/31,19:00,3302
2019/12/31,20:00,3263
2019/12/31,21:00,3182
2019/12/31,22:00,3077
2019/12/31,23:00,3029なので、空白文字でデータを分割してリスト化します。
# 空白文字でデータを分割してリスト化
dataList_brank = data.split()しかし、空白文字で分割するだけではダメです。
「print(dataList_brank)」を実行すると次のように出力されます。このままCSVに書き込みしようとすると、例えば「2019/12/31,23:00,3029」が全て1文字1セルに分割されてしまいます。
[(省略) '2019/12/31,22:00,3077', '2019/12/31,23:00,3029']空白文字で分割しただけの状態でCSVに書き込みした結果が次のようになります。1文字1セルに分割されています。
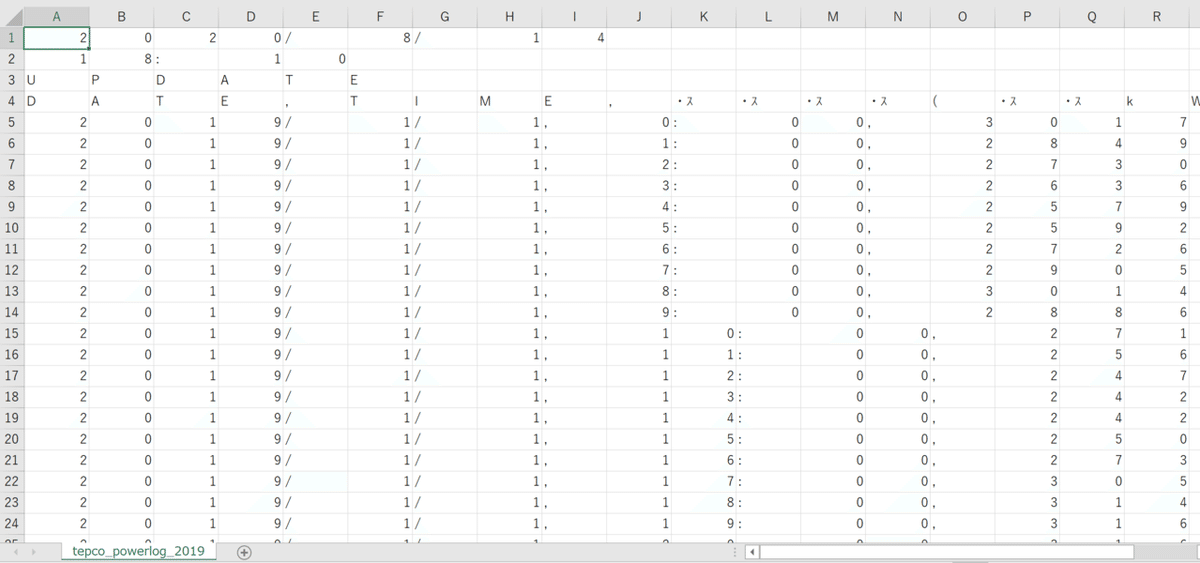
なので、次にカンマでデータを分割してリストに格納します。
# リスト初期化
dataList = [0 for i in range(nums)]
# カンマでデータを分割してリストに格納
for i in range(0, nums):
dataList[i] = dataList_brank[i].split(',')「print(dataList)」を実行すると次のように出力されます。この状態でCSVに書き込みすれば、「日付」「時刻」「電力量」で分割されたCVSデータとなります。
[(省略) ['2019/12/31', '22:00', '3077'], ['2019/12/31', '23:00', '3029']]最後に、CSVにデータを書き込みます。
# CSVにデータを保存
with open('tepco_powerlog_2019.csv', mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for i in range(0, nums):
writer.writerow(dataList[i])以上で完了です。これで前述した実行結果のCSVファイルを得ることができます。
全体ソースコード
全体ソースコードを以下に記載します。以降はここまでに分割して記載したソースコードをまとめただけで、ほぼ同じ内容です。ここからは有料に設定しますが、もしこの記事を気に入っていただいた方は、購入していただけると嬉しいです。
# =================================================
# ライブラリインポート
# =================================================
# csvファイルライブラリ
import csv
# HTTP 通信ライブラリ
import requests
# HTMLデータ抽出ライブラリ
from bs4 import BeautifulSoup
# =================================================
# メイン
# =================================================
# 指定したURLのHTML取得
urlName = "https://www.tepco.co.jp/forecast/html/images/juyo-2019.csv"
dataHTML = requests.get(urlName)
# Beautiful SoupでHTML解析
soup = BeautifulSoup(dataHTML.content, "html.parser")
# HTMLデータからテキストのみ抽出
data = soup.text
# 空白文字でデータを分割してリスト化
dataList_brank = data.split()
# リストの要素数取得
nums = len(dataList_brank)
# リスト初期化
dataList = [0 for i in range(nums)]
# カンマでデータを分割してリストに格納
for i in range(0, nums):
dataList[i] = dataList_brank[i].split(',')
# CSVにデータを保存
with open('tepco_powerlog_2019.csv', mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for i in range(0, nums):
writer.writerow(dataList[i])
print('----- END -----')以上
いいなと思ったら応援しよう!
