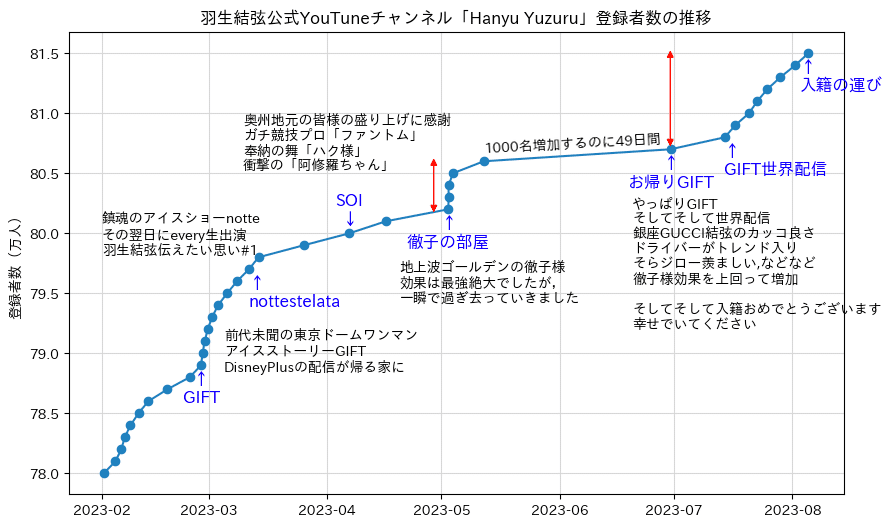
Python : Matplotlibでグラフ作成3(Google Colaboratory)

グラフ作成第3弾では、グラフ中に書き込むテキストにこだわってみました.
飛び飛びの日付に記録されている動画の登録者数を折れ線グラフにします.
データが飛び飛びなので,データがあるところにマーカを打つ
赤い矢印で強調したい量を示す
文字を自在に表示する
以上をテーマに,処理を書いていきます.
読み込んだCSVから不要部分を削除(不要な列とカットする行)
インデックス(行番号)をリセット
日時を日付型に変換(読み込んだままでは文字列)
グラフを描画
テキストを挿入
矢印を挿入
(1)グラフに日本語を表示させるためのライブラリをインストール
Colaboratoryは,Googleサーバ上の仮想環境なので,毎回のインストール作業が必要
!pip install japanize_matplotlibSuccesfullyと表示されれば,インストール成功
(2)ライブラリのインポートとデータの読み込み
ファイルはUTF-8 CSV形式で保存
必要なライブラリをインポートしておきます.
データを扱うためのPandas
グラフを描くためのMatplotlibと日本語対応
時刻を扱うためのDateTime
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import datetime
df = pd.read_csv('/content/データ.csv')
df.head()
(3)データの型変換とDataFrameの不要部分の削除
まずは不要な列を削除.dropで列名を指定.
列方向なので
axis=1
が必要です.
df = df.drop('Unnamed: 2' , axis=1)
df.head()
ファイルから読み込むと,文字列になってしまいます.
日付指定でデータの絞り込みをしたいので,
まずは,日付は日付型に,数値は数値型に変換します.
登録者数は3桁カンマがあると数値に変換できないので,「,」を取り除きます.
str型のメソッドを利用します.
str.replace('検索文字列' , '置換文字列')
replaceはstrに対するメソッドですが,ここでは、
df['登録者数']
つまりPandas.Seriesのすべての要素に適用する必要があります.
そういうときは「.str」strアクセサを利用します.
df['登録者数'].str.replace(',' , '')
によってカンマを排除した文字列を
pd.to_numeric( df['登録者数'].str.replace(',' , '') )
数値の変換して
df['n'] = pd.to_numeric(df['登録者数'].str.replace(',' , ''))
DataFrameの列に追加します.列名は「'n'」
X_dt = pd.to_datetime(df['日時'])
df['DateTime'] = X_dt
df['n'] = pd.to_numeric(df['登録者数'].str.replace(',' , ''))
df.head()
今回は,直近の変化を表現したく,2023年2月1日以降だけをグラフにしたいので,該当する部分をdf1に取り出します.
df1 = df[df['DateTime'] >= pd.to_datetime('2023/2/1')]
df1.head()
indexは以前のままなので、ゼロからにリセット
古いindexは要らないので,drop=Trueを指定
df1 = df1.reset_index(drop=True)
df1.head()
(4)グラフを描く
それでは,グラフを描きましょう.
fig , ax = plt.subplots(figsize=(10,6))
ax.plot(df1['DateTime'] , df1['n'] , marker='o')
ax.set_yticks(list(range(780000 , 820000 , 5000)) , ['{:.1f}'.format(i/10) for i in range(780 , 820 , 5)])
ax.set_ylabel('登録者数(万人)')
ax.set_title('羽生結弦公式YouTuneチャンネル「Hanyu Yuzuru」登録者数の推移')
ax.grid(color='lightgray')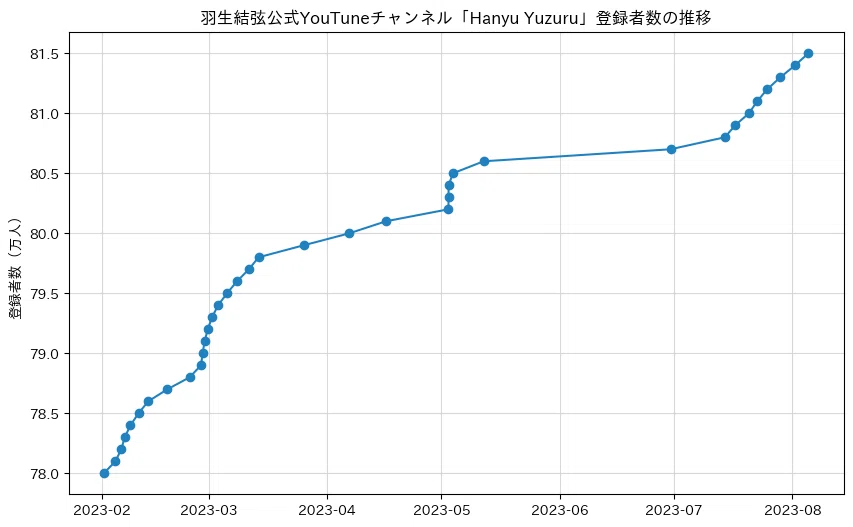
横軸は指定なしで収まりましたので,手を加えませんでした.
縦軸は単位を万人にし,5000人ずつ,少数第1位まで表示するために
ax.set_yticks([値] , [表示])
を用いて調整しました.
[値] : rangeで生成した数列をリスト化
list(range(780000 , 820000 , 5000)
[表示] : リスト内包表記で小数点以下を指定しますが,rangeは整数しか指定できないので,10倍の値で数列を発生させて10で割ってます.
['{:.1f}'.format(i/10) for i in range(780 , 820 , 5)]
マーカを記載するパラメータmarker を指定します
他のマークの形状はドキュメントを参照
(5)テキストを書き入れる
グラフは多かれ少なかれイベント事に連動することを表現したい.
例えば2023年2月26日のイベントがグラフではどこに当たるのか,できるだけ折れ線の近くに,できるだけ正確に表現したいところです.
x座標は日付がそのまま利用できます
import datetime
day0 = datetime.datetime(2023,2,26)
ここで、問題なのは,イベント当日にはデータがないことがある(むしろない事の方が多い)ことです.つまり,イベント当日のx座標は決定できますが,y座標がもともとのリストにはなく,どこにテキストを配置したらいいのかがわからないことです.
(注意)このデータは,チャンネル登録者数の推移が記録されていますが,YouTubeでは,1000名ごとに登録者数が更新されます.その結果,縦軸は1000名ごとにデータがありますが,横軸は、均等にはなりません.
1000名増加するのに49日かかったこともあれば,1日に2回1000名増えたこともあります.
そこで、直後のデータのy座標を利用することにします.
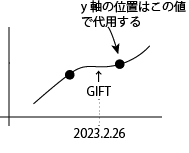
では、直後のデータはどこにあるのか?DataFrameをターゲットである日付以降に絞り込んだ新しいDataFrameを作ったときの最初の行が該当します.
dfx = df1[df1['DateTime']>=day0]
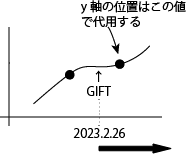
ただし、このままでは、indexがdf1のままなので、0からに更新する必要があります.
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
その結果
dfx.iloc[0]['n']
が該当するイベントのy軸の値になります.
実際には,表示する文字が折れ線グラフに重なってしまうと見づらいので、多少の調整は必要です
day0 = datetime.datetime(2023,2,26)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(day0 , dfx.iloc[0]['n'] -500, '↑\nGIFT' , va='top' , ha='center', size='large' , color='blue')文字の表示位置は指定の座標に対し、どのような配置にしたいのかを指定することができます。
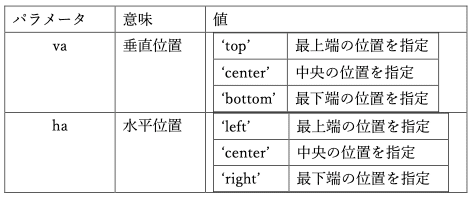
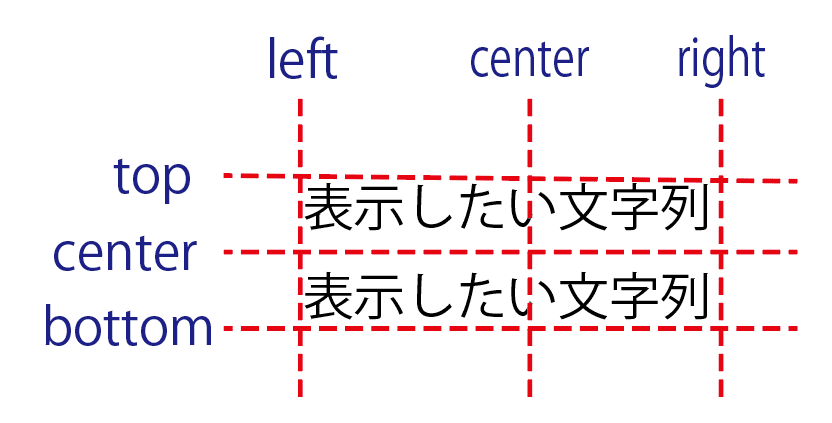
文字の大きさの指定は以下のとおり

他にptで指定する方法もあります.
文字列は傾けることもできます.
rotation=角度(度で指定)
fig , ax = plt.subplots(figsize=(10,6))
ax.plot(df1['DateTime'] , df1['n'] , marker='o')
ax.set_yticks(list(range(780000 , 820000 , 5000)) , ['{:.1f}'.format(i/10) for i in range(780 , 820 , 5)])
ax.set_ylabel('登録者数(万人)')
ax.set_title('羽生結弦公式YouTuneチャンネル「Hanyu Yuzuru」登録者数の推移')
ax.grid(color='lightgray')
day0 = datetime.datetime(2023,2,26)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nGIFT' , va='top' , ha='center', size='large' , color='blue')
day0 = datetime.datetime(2023,3,11)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nnottestelata' , va='top' , ha='left' , size='large' , color='blue')
day0 = datetime.datetime(2023,4,1)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] +500, 'SOI\n↓' , va='bottom' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,5,2)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\n徹子の部屋' , va='top' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,6,30)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nお帰りGIFT' , va='top' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,7,14)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(day0 , dfx.iloc[0]['n'] -500, '↑\nGIFT世界配信' , va='top' , ha='left' , size='large' , color='blue')
day0 = datetime.datetime(2023,8,3)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(day0 , dfx.iloc[0]['n'] -500, '↑\n入籍の運び' , va='top' , ha='left' , size='large' , color='blue')day0 = datetime.datetime(2023,5,12)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] +500, '1000名増加するのに49日間' , va='bottom' , ha='left' , rotation=3)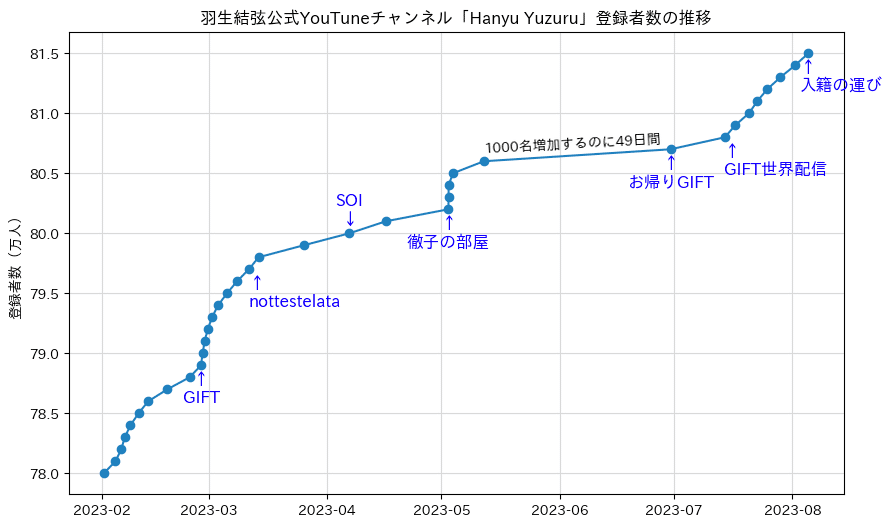
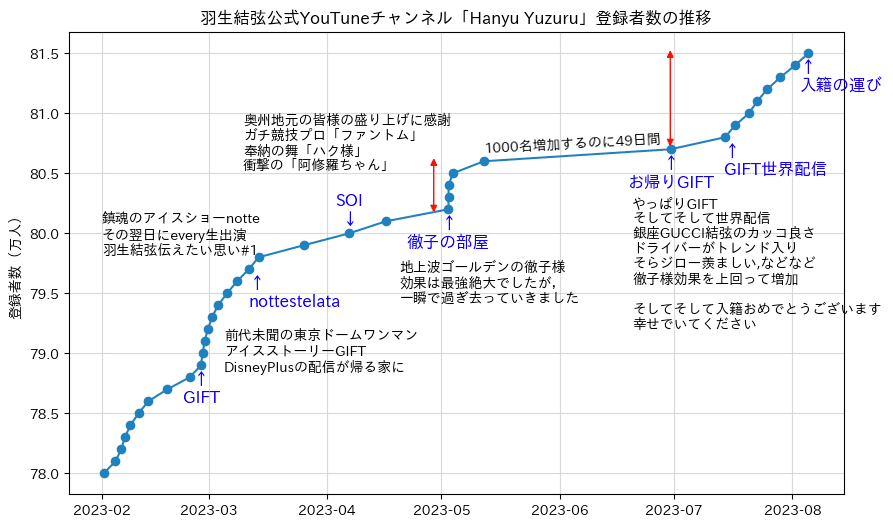
(6)矢印を書き入れる
本来は、矢印付きの注釈を入れるためのメソッドですが、注釈なしで矢印として利用しました.そのため,矢印が指定の座標より若干短く描画されます.
fig , ax = plt.subplots(figsize=(3,2))
x = [0 , 1 , 2 ]
y = [0 , 1 , 4 ]
ax.plot(x,y)
ax.annotate('' , (1,1) , (2 , 4) ,
arrowprops=dict(arrowstyle='<->' , color='red'))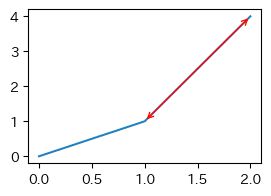
矢印の種類は以下のとおりです
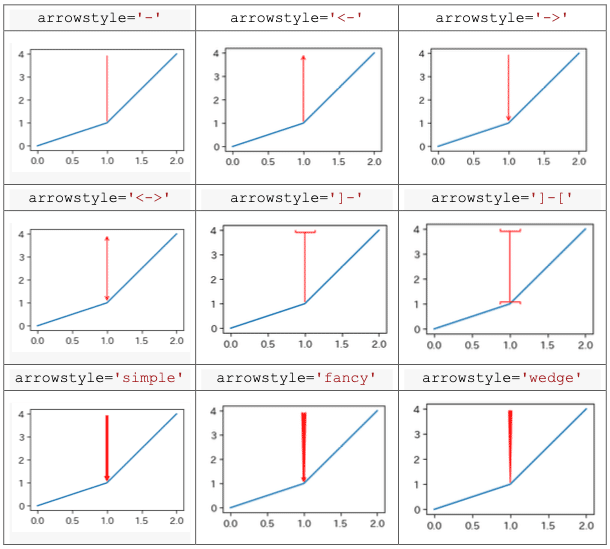
fig , ax = plt.subplots(figsize=(10,6))
ax.plot(df1['DateTime'] , df1['n'] , marker='o')
ax.set_yticks(list(range(780000 , 820000 , 5000)) , ['{:.1f}'.format(i/10) for i in range(780 , 820 , 5)])
ax.set_ylabel('登録者数(万人)')
ax.set_title('羽生結弦公式YouTuneチャンネル「Hanyu Yuzuru」登録者数の推移')
ax.grid(color='lightgray')
day0 = datetime.datetime(2023,2,26)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nGIFT' , va='top' , ha='center', size='large' , color='blue')
day0 = datetime.datetime(2023,3,11)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nnottestelata' , va='top' , ha='left' , size='large' , color='blue')
day0 = datetime.datetime(2023,4,1)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] +500, 'SOI\n↓' , va='bottom' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,5,2)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\n徹子の部屋' , va='top' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,6,30)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] -500, '↑\nお帰りGIFT' , va='top' , ha='center' , size='large' , color='blue')
day0 = datetime.datetime(2023,7,14)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(day0 , dfx.iloc[0]['n'] -500, '↑\nGIFT世界配信' , va='top' , ha='left' , size='large' , color='blue')
day0 = datetime.datetime(2023,8,3)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(day0 , dfx.iloc[0]['n'] -500, '↑\n入籍の運び' , va='top' , ha='left' , size='large' , color='blue')
day0 = datetime.datetime(2023,5,12)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.text(dfx.iloc[0]['DateTime'] , dfx.iloc[0]['n'] +500, '1000名増加するのに49日間' , va='bottom' , ha='left' , rotation=3)
day0 = datetime.datetime(2023,4,20)
ax.text(day0 , 794000, '地上波ゴールデンの徹子様\n効果は最強絶大でしたが,\n一瞬で過ぎ去っていきました' , va='bottom' , ha='left')
day0 = datetime.datetime(2023,3,5)
ax.text(day0 , 792000, '前代未聞の東京ドームワンマン\nアイスストーリーGIFT\nDisneyPlusの配信が帰る家に' , va='top' , ha='left')
day0 = datetime.datetime(2023,2,1)
ax.text(day0 , 798000, '鎮魂のアイスショーnotte\nその翌日にevery生出演\n羽生結弦伝えたい思い#1' , va='bottom' , ha='left')
day0 = datetime.datetime(2023,3,10)
ax.text(day0 , 810000, '奥州地元の皆様の盛り上げに感謝\nガチ競技プロ「ファントム」\n奉納の舞「ハク様」\n衝撃の「阿修羅ちゃん」' , va='top' , ha='left')
day0 = datetime.datetime(2023,6,20)
ax.text(day0 , 803000, 'やっぱりGIFT\nそしてそして世界配信\n銀座GUCCI結弦のカッコ良さ\nドライバーがトレンド入り\nそらジロー羨ましい,などなど\n徹子様効果を上回って増加\n\nそしてそして入籍おめでとうございます\n幸せでいてください' , va='top' , ha='left')
day0 = datetime.datetime(2023,5,2)
day1 = day0 + datetime.timedelta(days=-3)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.annotate('' , (day1 , 801500) , (day1 , 806500) ,
arrowprops=dict(arrowstyle='<|-|>' , color='red'))
day0 = datetime.datetime(2023,6,30)
day1 = day0 + datetime.timedelta(days=-3)
dfx = df1[df1['DateTime']>=day0].reset_index(drop=True)
ax.annotate('' , (day0 , dfx.iloc[0]['n']) , (day0 , dfx.iloc[0]['n']+8500) ,
arrowprops=dict(arrowstyle='<|-|>' , color='red'))
plt.show()