
「𠮷」と「吉」 サロゲートペアって?

ふとしたことで、知ることになった「サロゲートペア」という単語。何のことかご存じですか?
サロゲートペアとは?
2007年 8月の記事、とちょっと古いようにも思えますが、丁寧に説明されているので、この辺りを確認するとわかりやすいです。
具体的には、従来のUnicodeでは未使用のだった0xD800~0xDBFF(1024通り)を「上位サロゲート」、0xDC00~0xDFFF(1024通り)を「下位サロゲート」と規定し、「上位サロゲート+下位サロゲート」の4バイトで文字を表現する方法です。
と説明されているように、Unicode で未使用だった領域を組み合わせて、これまで表現できなかった文字を表現する方法のことです。
以下 URL のサイトで確認すると、どのように表現されているのかがイメージできます。
↑ のサイトに、「吉」と「𠮷」を入力してみると、下図のような結果が表示されます。
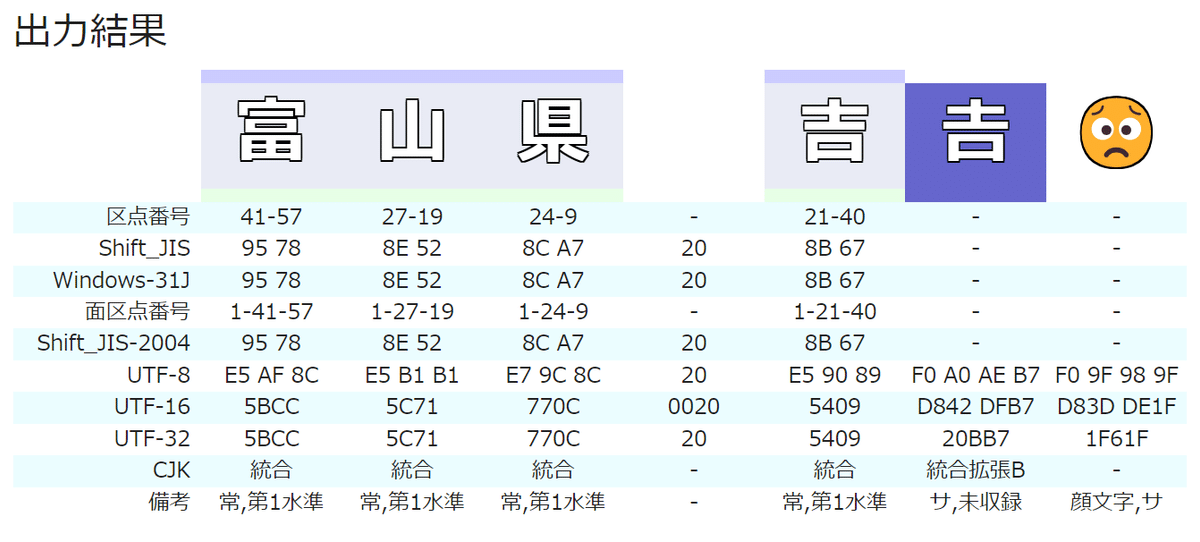
「吉」と「𠮷」のそれぞれの文字コードが表示されています。 ※中央の 20 と表示されているのは、区切りとして入力した半角スペースの文字コードです。
最下行「備考」の欄に、「𠮷」は「サ,未収録」と表示されていますが、この「サ」がサロゲートペアであることを示しています。
「𠮷」は「句点番号」や「Shift JIS」では表現できず、「UTF-8」や「UTF-16」では表現できる。
一般の文字は、UTF-8 なら 3byte、UTF-16 なら 2byte で表現される。しかし、サロゲートペアの文字は UTF-8 なら 4byte、UTF-16 なら 4byte で表現される。
という感じで、従来の文字コードの原則が変わってしまうくらいの、アクロバティックな手法が「サロゲートペア」なのです。
サロゲートペアを使用する文字は「1文字=4バイト」ですから、従来のUnicodeの特徴であった「文字数 × 2 = 使用バイト数」の原則が崩れてしまいます。そのため、Unicode対応の開発環境であったとしても、サロゲートペアが絡むと過去に作ったプログラムがうまく動かない場合が出てくると思われます。
顔文字も、サロゲートペア
以下 URL でも説明されていて、顔文字もこのサロゲートペアによって実現されているようです。実際、↑ のように 😟 もサロゲートペアと表示されています。
異体字?
更に話をややこしくしているのが異体字と呼ばれるもの。サロゲートペアと同様に、前述のサイトで確認してみると、↓ のような感じになります。
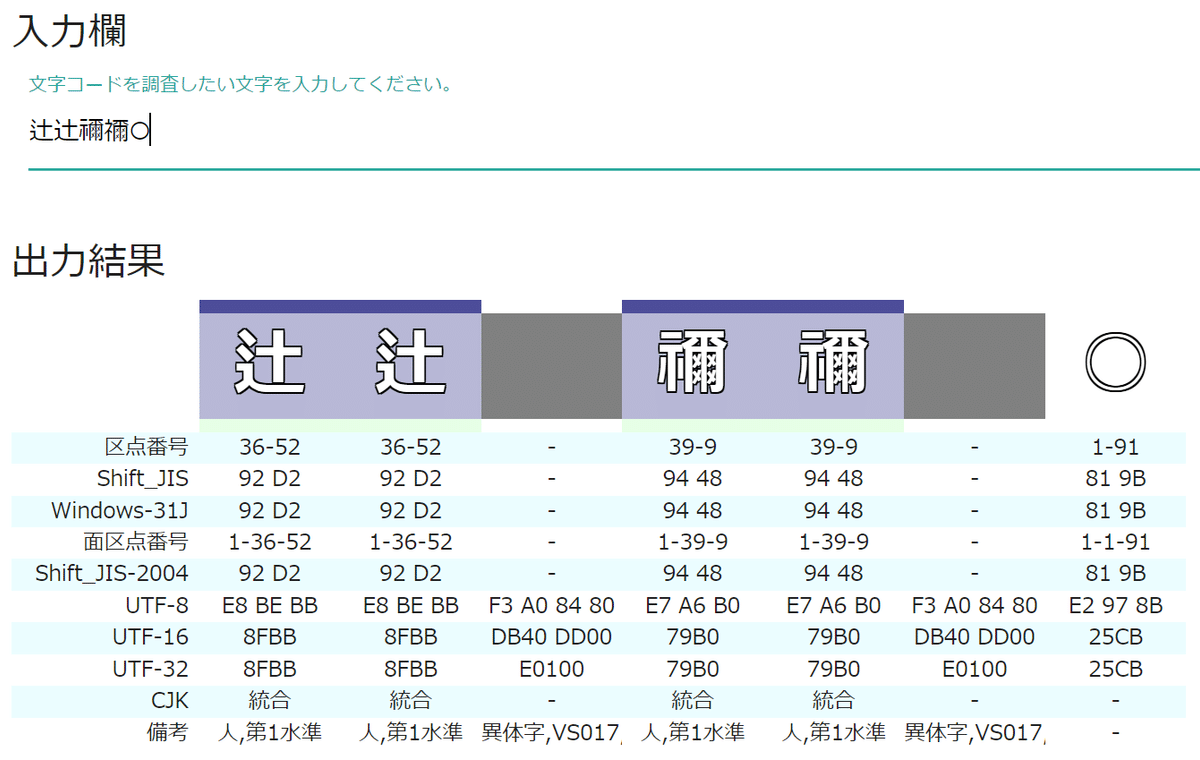
「辻辻󠄀禰禰󠄀○」と 5文字の文字コードを表示させると、↑ のようになります。「辻󠄀」は「辻」の異体字なので、「辻」に加えて異体字セレクタと呼ばれる U+E0100 が続いています。「禰󠄀」も同様です。
以下のサイトで
意味は同じだけど表記が少し異なる文字があります。「鬼滅の刃」 の 「竈門禰󠄀豆子」 の 「禰󠄀(部首がネ)」 は文字としては登録されておらず、「禰(部首が示)」 の 異体字(variant) として扱われます。異体字は、元の文字に 異体字セレクタ(variation Selector) と呼ばれる U+180B~U+180D(3個)、U+FE00~U+FE0F(16個)、U+E0100~U+E01EF(240個) を付加して表します。
と説明されているように、異体字セレクタは U+E0100 だけでなく、これも含めて文字コードとして動作する感じなので、サロゲートペアと同様に「文字数 × 2 = データサイズ」が成り立たなくなります。😥
この記事のまとめ
実際に確認してみるために、GAS でプログラムを作ってみました。
"use strict"; // 変数の宣言を強要する
/** @OnlyCurrentDoc */ // 他のファイルにはアクセスしない
/**
* 文字コードのチェック
* サロゲートペアの文字コードが含まれているかをチェックする。
*/
function checkCode(str) {
// 参考: http://glasses-se-note.com/surrogate1/
for (let i = 0; i < str.length; i++) {
let code = str.charCodeAt(i);
console.log('0x' + code.toString(16));
if (
(0xD800 <= code && code <= 0xDBFF) ||
(0xDC00 <= code && code <= 0xDFFF)
) {
console.log('サロゲートペア発見: ' + str + " (" + code.toString(16) + ")");
return true;
}
}
return false;
}
function test() {
console.log(checkCode('Abc'));
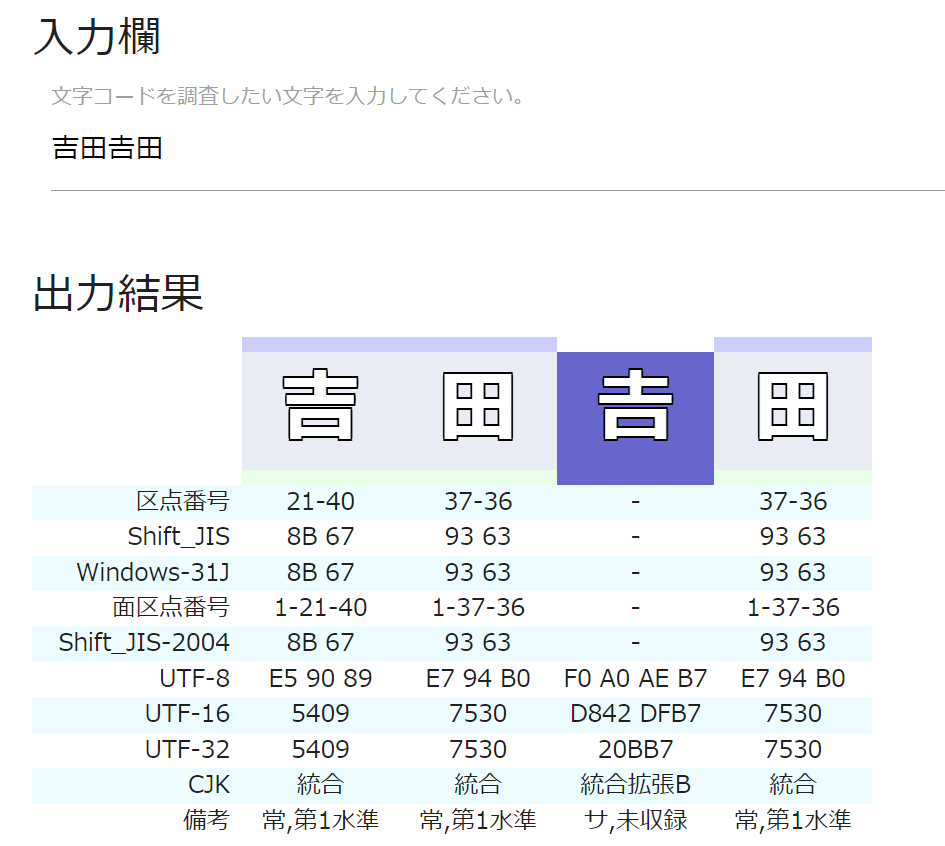
console.log(checkCode('吉田'));
console.log(checkCode('𠮷田'));
}

↑ のプログラムでは「abc」「吉田」「𠮷田」という 3つの文字列の文字コードを確認しています。test 関数を実行すると、以下のような結果が得られました。

このプログラムでは、charCodeAt( ) によって、文字列から 1文字ずつ切り出して、文字コードを確認しています。今回の実行結果からわかるのは…
表示されている文字コードから判断するに…
GAS のプログラムでは、プログラム中に定義した文字列中の漢字などは UTF-16 の文字コードが用いられている。 ※「吉」が 0x5409 となっている。charCodeAt( ) でもサロゲートペアの文字コードは、1文字分と解釈されず、「上位サロゲート」と「下位サロゲート」が別の文字のように扱われている。
といった感じです。
以下 URL で説明されているような内容を見て、Unicode で異体字などにも対応できるということは知っていましたが、その中身がこのような「サロゲートペア」や「異体字セレクタ」というものによって実現されていることがわかりました。
この辺りがわかってないと、今風の文字列処理ができないことがわかりました… 奥深いですね。😅
この記事が気に入ったらサポートをしてみませんか?