
CLIP Text Deprojectorを使って画像生成してみる ~再帰的な入力でLSTMを学習する~

前回、LSTMモデルを導入しましたが、学習手法はTransformerベースのVTモデルと同様でした。今回は、LSTMの特性を利用し、再帰的な入力を用いた学習を試してみます。
前回の記事
他のStable Diffusionの関連記事
Layered Diffusion Pipelineを使うためのリンク集
ライブラリの入手先と使用法(英語) : Githubリポジトリ
日本語での使用方法の解説 : Noteの記事
LSTMモデルの再帰的入力
前回のLSTMモデルの学習時、系列入力(x)の値を学習データから得ていました。これは、Transformerベースのモデルの学習手法と同じものですが、LSTMの場合はAttention機構がなく、各位置の計算が分離しているため、直前の位置の結果を次の位置の計算に渡すことが容易です。
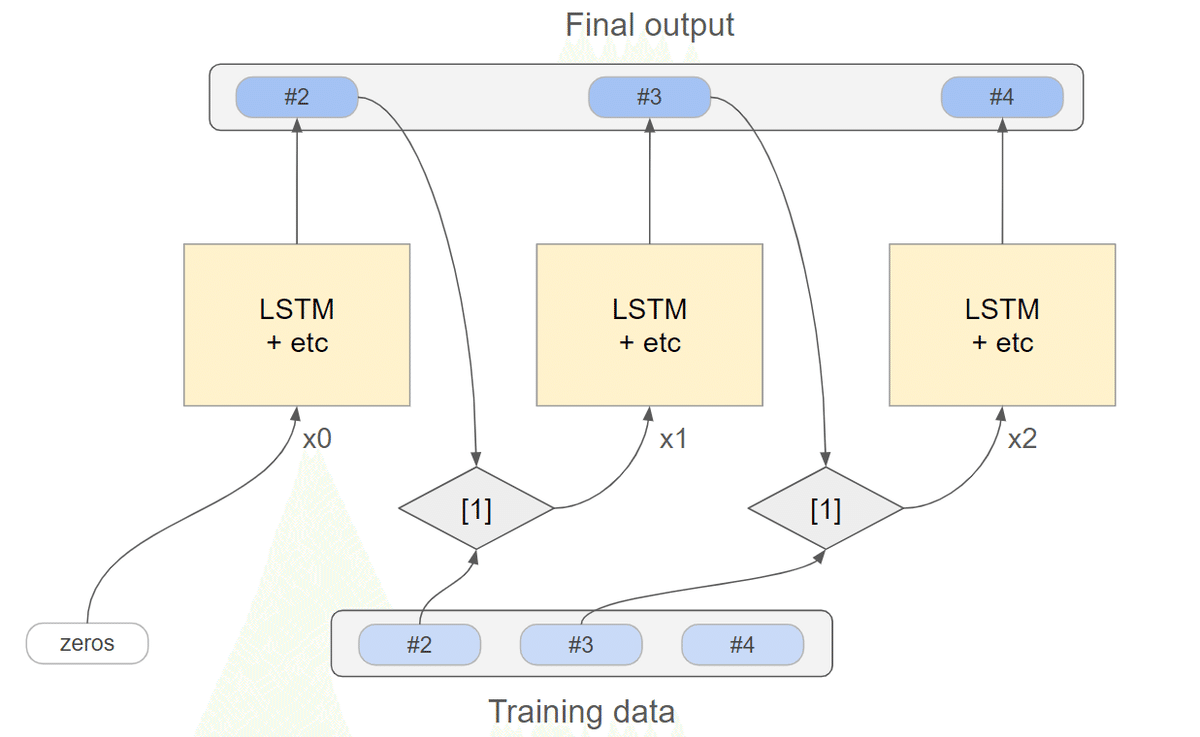
上図はLSTMモデルの模式図ですが、前回の学習では[1]の部分で学習データからの系列データを渡していました。今回の学習では、代わりに直前の位置の実際の出力を渡すようにします。
区別のため、この記事では、前者の方式を「一括入力」、後者の方式を「再帰的入力」と呼ぶことにします。
再帰的入力を用いた学習のメリットは、これが実際の推論時の計算方法と同じ方法なので、学習時と推論時の差がなくなるという点にあります。
実験方法
実験には、2種類の手法を試します。1つ目は、前回、一括入力で学習したモデルに対して、再帰的入力を用いて追加学習を行うという方法、2つ目は、最初から再帰的入力で学習をやり直すという方法です。
生成画像は上から
Deprojectorなし
一括入力(前回の学習結果)
追加学習 2エポック
追加学習 4エポック
再帰的入力でやり直し
となっています。使用したプロンプトはこれまでと同様、次の通りです。
単一embedding
cat maid (猫耳メイド)
1girl red hair blue eye black skirt(赤髪 青目 黒スカート)
1boy 1girl in class room(少年 少女 教室)
複数embeddingの合成
cat, maid (猫 メイド)
1girl, red hair, blue eye, black skirt (赤髪 青目 黒スカート)
1boy, 1girl, in class room (少年 少女 教室)
生成画像
レイヤー正規化を用いたモデル
前回、スカラ係数を用いたモデルを試しましたが、ここではそれに置き換えてレイヤー正規化を用いたモデルを使いました。


線形変換を用いたモデル
これは、前回の線形変換を用いたモデルをそのまま利用しました。


観察結果
今回生成した画像の範囲では、一括入力と再帰的入力の間で、決め手となるほどの差は観察されませんでした。
まとめ
LSTMモデルで再帰的入力を用いた学習を試しました。しかし、今回の実験の範囲では、学習結果に大きな差は生まれませんでした。