【Aidemy X Bio】Aidemyのコースを応用して、遺伝子解析データを機械学習させてみたら?第一弾

Aidemy X Bio 第一弾:遺伝子解析データつかって主成分分析(PCA)してみよう!

Aidemyの機械学習のコースがよくできていて、非常に面白かったので、そのうち教師なし学習のコースの例題を利用して、乳がん細胞と正常細胞を比較した遺伝子解析データ(RNAシーケンスによる遺伝子発現データ)を主成分分析(PCA)を行ってみることとした。
まずは環境設定:Jupyter NoteBookがおすすめ
Aidemyのサイトでなく、Pythonを自分のPCで使うため、Pythonのセットアップが必要である。アカデミアだとJupyter NotebookでPythonを利用している人が多いので、Pythonをダウンロードしたのち、アナコンダをダウンロード、その元でJupyterをインストールする。詳しくはJupyterのサイトに丁寧にかいてあるが、その通りやれば特に苦労なく環境設定できた。
データについて
データはハーバード大学医学部のバイオインフォマティックスコースで教材として用いられている10サンプルずつの乳がん細胞と正常細胞の遺伝子発現データーで、約23000遺伝子の発現量(RNA-seqのリード数)が20サンプルずつ入ったスプレッドシートが元である。
このデータをRにより前処理し、発現が半分のサンプルで0である遺伝子を除き、リード数のテーブルをcsvとしてまずは用意した。このデータを用いてまずは解析を行ってみたのであるが、データサイズが大きいせいか ブロードキャストの部分でエラーがでてしまう。またもともとのコースで使われていた教材と行列の構造が倒置された形になっているが、これをpythonで倒置するとこれまたエラーがでる。
エラー処理は次回の課題とし、全サンプルでの平均発現量が上位1999位までの遺伝子に数を絞り、さらに別ソフトで倒置したものを入力データとして今回は使用した。
データの読み込み

Aidemyの講座のコードを改変し、ファイルを読み込む。データを変数に代入するところで、数値データーが文字データに変わってしまうようなので、yの変数を強引に数値データにしている。これはもう少し工夫が必要だろう。
データーの解析
まずは標準化の有無でデータがどう変わるかをチェック。基本的には遺伝子の発現分布が正規分布と仮定し、平均値を0とし標準偏差を一定の範囲に収める処理をしている(のだと思うw)。遺伝子の発現分布は実は正規分布ではない(くわしくは元のデーターサイトのパワーポイント資料参照)ため、この標準化はしたほうがいいのかどうか迷うところである。

主因子分析
そして相関行列、固有値行列を求めて主成分分析を行う。
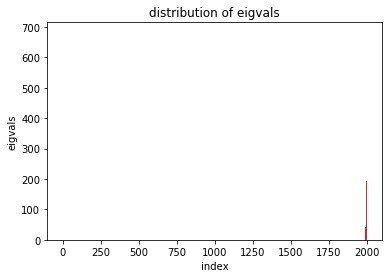
この辺りは順調で、ほぼPC1とPC2で乳がんと正常細胞の違いが説明できるのわかる。
最後におなじみのPCA分析の図を書かせてみる
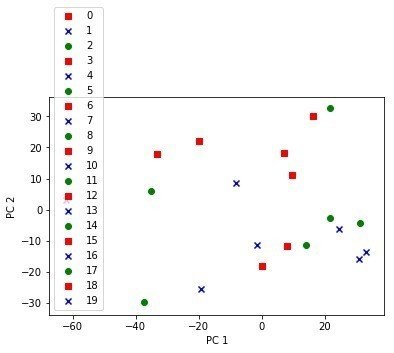
最初20サンプルを別々の色にしようと思ったのだが、今ひとつうまくいかなくで断念。。。
最初10サンプルががん細胞、残りの10サンプルが正常細胞ということがわかっているか、Aidemyのコースの例題をうまく改変してがん細胞を赤、残りを青にして表示させてみた
標準化あり
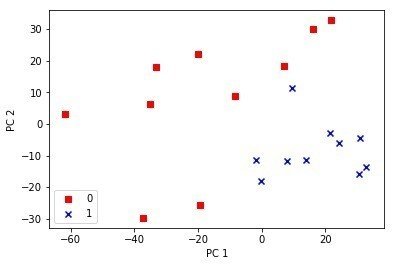
標準化なし

ものすごくクリアにわかれていないが一部の遺伝子のデータしかつかっていないからとりあえずはうまくいっているほうでないだろうか?
実際に自分で実装してみて気づいたこと
Aidemyのコースは非常にわかりやすくて、データを自分でいじることに抵抗感がなくなるのだけれど、細かな部分を分かったつもりになっていることが多く、また割と理想的な状況になっているので、実際に手を動かしてみて初めて課題、疑問点がはっきりしてくる気がした。
このためAidemyのコースで学ぶ際には
1)ある程度の時期が来たら、自分の手持ちのデータを用いて、自分自身で実装してみる
2)Aidemyのサイトだけでなく、自分のPCにもPythonを導入して、データ、リスト、データフレームなどの構造を理解しながら、学ぶこと
をお勧めする。また逆にワインのデーターより複雑な実際のケースに近いデーターを用いた実践編みたいなコースがあるといいのではないかと思われた。
今後の課題
今回見えてきた課題は
1)データー量が多いと、ブロードキャストがうまくいかず発現量が上位1999で比較した
2)標準化していないデータであるが、標準化はどうすればよいだろうか?統計量が正規分布でない(確かNegative Binomial distribution)
3)ファイル読み込み、Data Visualisationでちょっと強引にやったところがあるので、もう少し洗練させた方がいい
といったところになります。標準化以外についてはPythonのスキルが上がれば解決するト思われるのですが、一応今後の宿題として
1)データサイズの大きいデータの解析手法
2)ファイルの読み込み
3)データービジュアリゼーション(効率の良いデータの色指定、マーカー指定など)
4)標準化の問題
ということを挙げておきたいと思います。
もし何か良い知恵があればご教示いただければ幸いである。
この記事が気に入ったらサポートをしてみませんか?