
コンテンツのイラストをStableDiffusionでつくろう

こんにちは、てぃーえむです。
この記事は過去プレゼント企画で配布したものを期間限定で再配布します。
AIの進化は早く、少し今と情報が異なるかもしれませんのでご注意ください。
期間経過後は有料にしてしまいますので、今のうちに閲覧ください。
はじめに
いきなりですが、コンテンツ作成するときに
コンテンツの中で使うイラストはどうやって準備していますか?
・自分で描く?
・フリー素材サイトで探す?
・外注する?
フリー素材サイトで探していましたが、どうしても
「なんとなく関連するものを無理やり選んで」使ってました。
そんな人多くないですか?
近頃、急速に発達したAI画像生成技術によって
画像を生成することが出来るようになりました。
自分の意図に近い画像を生成して、
「無理やり選ぶ」ではなく「欲しいものを作って」
を利用したいとは思いませんか?
本記事では、
コンテンツ制作に役立つ
AIイラスト生成の方法について解説していきます。
AI画像生成のメリット
1. 時間と費用の削減

AI画像生成を使って、画像つくる場合のメリットは次の2つです。
・短時間でコンテンツ画像を準備する
・外注費の削減
この時間と費用が削減できるのはうれしいです。
特にコンテンツ販売初心者には
費用削減もうれしいです。
なんとしても習得したスキルですよね。
2. 大量のイラストを短時間で作成

AI画像生成を使えば、
短時間で大量のイラストを作れます。
大量のイラストを必要とする場合には、便利です、
また、気に入った画像を
多くのなかから選ぶこともできます。
3. 細かい調整も可能

手描きイラストでは難しい細かい調整も
簡単に行うことができます。
フリー素材は、少し違和感を感じても、変更はできませんが、
AI画像生成ならば調整できます。
さらにかなり品質の高いイラストも作ることができます。
コンテンツ作りの強力な手助けとなります。
是非とも習得しておきたいスキルですね。
AI画像生成を利用することで、
イラストを探す・作成するが簡単にでき、
かつ、時間と費用を大幅に削減することができます
AI画像生成の種類

AI画像生成するツールやサービスは多く出ています。
その中でも、定番なのが次の2つです。
・Midjourney
・StableDiffusion
どっちを選べば良いの?となりますよね。
コンテンツ作成・ビジネス界隈で
メジャーなのは「Midjourney」です。
みなさん「Midjourney」を推しが多いですが
「StableDiffusion」をお勧めします!
StableDiffusionは動作するPCさえ持っていれば、
100個生成しても1万個生成しても無料です。
さらに多機能なので、極めれば好みの画像を
調整して生成することもできます。
多機能な分、難しい部分があるのがデメリットですけどね。
2つの特徴をの違いをまとめました。

StableDiffusionは動くPCさえあれば費用がかからない。
高機能で細かな調整がやりやすいです。
導入が難しそうだから諦めてる人もいると思いますが、
1度導入してしまえば作り放題。◀ここ重要
動作環境は?
StableDiffusionを動作させるスペックは次のとおり。
【推奨スペック】
OS :Windows 10/11 64bit
CPU: Intel Core-i シリーズ・AMD Ryzenシリーズ
メモリー: 16GB以上
グラフィックボード: 8GB以上
必ず推奨を満たしてなくても動きます。
チャレンジしてみるものありかもしれません。
【1枚生成にどれくらいかかるか参考値】
(画像サイズ512x512)
[測定1]
OS :Windows 10 64bit
CPU:AMD Ryzen7 3700X
メモリー: 32GB
グラフィックボード: RTX 3050(12GB)
1枚生成 ▶▶▶ 約5秒
--------------------------------------------------------------
[測定2]
OS :Windows 10 64bit
CPU:AMD Ryzen7 3700X
メモリー: 32GB
グラフィックボード: GTX 1050Ti(4GB)
1枚生成 ▶▶▶ 約60秒
上手くいかない場合もオープンチャットで
サポートするので気軽に聞いてくださいね。
今回はStableDiffusionを使って、
コンテンツ用の画像作成の方法を解説していきます。
StableDiffusionの設定方法

それではいよいよStableDiffusionの設定を説明します。
StableDiffusionを動かすためのツールは数多くあります。
今回はその中でも「StableDiffusion WebUI」というものを使っていきます。
StableDiffusion WebUIはアップデートも頻繁で、拡張機能も豊富です。StableDiffusionを使うためのツールの中で最もメジャーなものになります。
下記の設定方法を参考に、セットアップを行ってください。
▶▶設定方法はこちら◀◀
StableDiffusionでの生成方法

設定が終わったら、早速画像を作っていきましょう。
本当に簡単に説明をすると
① 作ってほしいものをプロンプトを入れる
② 作ってほしくないものをネガティブプロンプトに入れる
③ 生成ボタンを押す
以上です。
いろい難しいことは抜きにして、まずは作ってみましょう
サンプルはこの画像
①プロンプトを入力する
StableDiffusionのプロンプトはアルファベットで「,」(カンマ)で区切ります。
a running person,blue wear入力するのは▼ココです。

生成は《Genarate》ボタンを押します。

出てきたのはこの画像(ランダムなので人によって違う)

②ネガティブプロンプトを入力する
ネガティブプロンプトとは、生成して欲しくないものを入力します。
例えば「boy」と入れれば男の子が生成されなくなります。
boy生成は《Genarate》ボタンを押します。
出てきたのはこの画像(ランダムなので人によって違う)

出来上がりが右のウインドウに表示されます。
この画像ファイルは
パソコンのフォルダーに保存されてます。
このフォルダボタンを押せば、保存フォルダが開きます。

どうでしたか?簡単でしたね?
ここでうまく動かない場合、困ったことがある場合は
オープンチャットでコメントください。
出来る限りのサポートさせてもらいます。
■コンテンツに利用するイラストの作り方

ここからは、コンテンツに利用するイラストの作り方を解説します。
コンテンツで利用するイラストは主に3種類あります。
・アイキャッチ(記事の先頭の画像)
・挿絵(記事の途中の画像)
・サムネイル
これを作ってきます。
今回は、プレゼント企画のアイキャッチ作りましょう。
大きな流れは次のとおり
STEP1:プロンプトを作る
STEP2:たくさん生成をする
STEP3:1つ決めて画質を上げる
STEP4:サイズを調整する
最初から綺麗な完成品を作るのではなく、
次の順番で徐々につくります。
たくさん候補をだす▶良いのを絞る▶調整する
STEP1:プロンプト作る
まずは、StableDiffusionのプロンプトを考えましょう。
本当はプロンプトの作り方を学ぶのが1番良いのですが、
今日はとりあえず使える事を目指します。
方法は2つ
①AI画像の投稿サイトからいいなと思った画像のプロンプトを拝借する②ChatGPTで作る
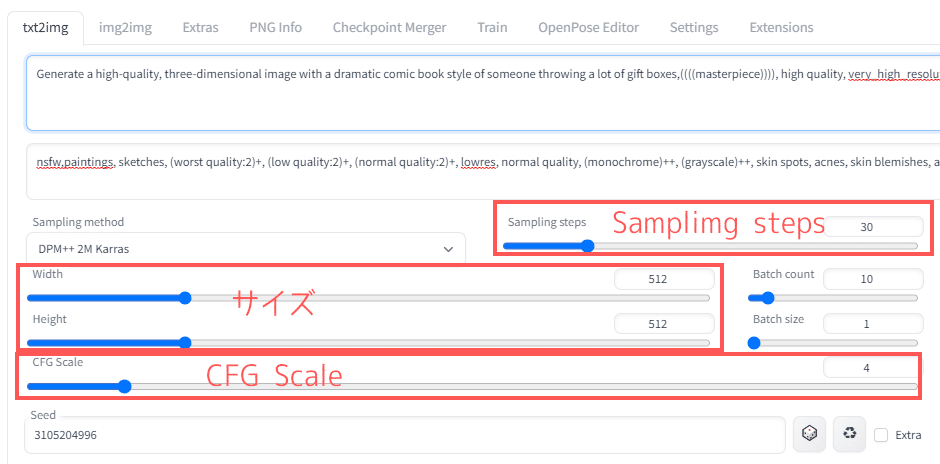
【パラメータ】
パラメータは一旦以下で設定しておけば良いです。
SamplingSteps:20
Width:512
Height:512
CFGScale:7
生成が遅すぎてどうしようもなければ
Width:256
Height:256
くらいにしてみてください。
▶STEP1-①:プロンプトの拝借
プロンプトを公開しているサイトがあります。ここからお借りしましょう。
おすすめは、モデルデータをダウンロードしたCivitAIあたりが良いでしょう。
まず好きな感じの画像を探すしてください。
見つかったら、画像の右側に「Prompt」と「Negative prompt」があるので、これをStableDiffusionのprompt,Negative prompt欄に貼り付けます。
これで《Generate》

出来た画像はこちらです。
使っているモデルが違う場合は、
全然違ったキャラクターになりますが、
感じは似てると思います。
▶STEP1-②:ChatGPTにお願い
ここはChatGPTにお願いしちゃいましょう。
StableDiffusionのプロンプトを生成するプロンプトを使います。
##指示
以下のテーマの画像を生成するStable Diffusionのプロンプトを作成してください。
立体的で高精細にしてください。低画質の画像は生成しないでください。
##ルール
・要素はすべて英語にしてください。
・要素は75個以内にしてください。
・要素の区切りは半角カンマを使用してください。
・品質を向上させるためにpromptには「」を必ず入れてください。
・品質を向上させるためにNegative promptには「」を必ず入れてください。
・年齢、髪の色、髪型、髪の長さ、目の色、視線の向き、表情、服装を要素に入れてください。
・英語で出力した後に、日本語翻訳を出力してください。
・プロンプトには必ず「(best quality)++,(masterpiece)++,(ultra detailed)++,」を先頭に付けてください。
##プロンプトの例
"""
prpmpt:
(best quality)++,(masterpiece)++,(ultra detailed)++.
worried face,round face,medium hair,streaked hair,blunt bangs,brown hair,overhead shot,lens flare,a girl sitting at a desk, holding a pen and looking contemplative.
Negative Prompt:
nsfw,paintings, sketches, (worst quality:2)+, (low quality:2)+, (normal quality:2)+, lowres, normal quality, (monochrome)++, (grayscale)++, skin spots, acnes, skin blemishes, age spot, glans
"""
##テーマ
{ここに作りたいテーマを記載する}
#出力形式
Prompt:
Negative Prompt:
{ここに作りたいテーマを記載する}のところに
「たくさんのプレゼントボックスを投げつけるスピード感満載の劇画調」
って入れてみました。
出てきたものをそれぞれStableDiffusionに貼り付けます
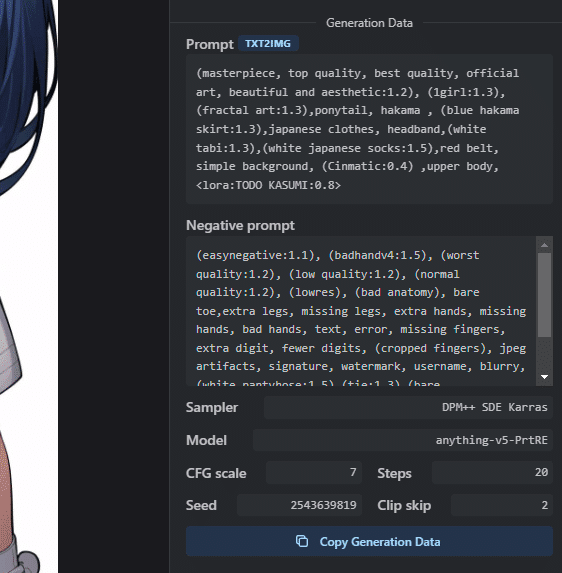
Prompt:
Generate a high-quality, three-dimensional image with a dramatic comic book style of someone throwing a lot of gift boxes,((((masterpiece)))), high quality, very_high_resolution, large_filesize, full color
Negative prompt:
nsfw,paintings, sketches, (worst quality:2)+, (low quality:2)+, (normal quality:2)+, lowres, normal quality, (monochrome)++, (grayscale)++, skin spots, acnes, skin blemishes, age spot, glansこれで《Generate》
できたうちの一つがこれ
(採用しませんでしたw)

STEP2:たくさん生成をする
前のSTEPの生成はどうでしたか?
イメージ通りのものができましたか?
一発ではなかなか出てこないと思います。
AIの匙加減でなにがでてくるかわからないので、
多くバリエーションを作って良いのを残していく選抜方式がおすすめです。
バリエーションの作り方は次の3つ
①モデルの変更
②プロンプトの調整
③パラメータの調整
この3つの方法どれでも良いので、
いろいろいじってみて好みの画像を探します。
では、実際のやり方です。
▶STEP2-①モデルを変えてみる
モデルを変えることで雰囲気がガラッと変わる
これがStableDiffusionの特徴でもあり、醍醐味でもあり、沼でもあります。
変更方法は左上のモデルの選択を変更してみてください。

これでGenerateしてみてください。
どうでしゃうか?だいぶ雰囲気変わったのではないでしょうか。
ここで、好みの画像に近いものを決めてください。
モデルはダウンロードしてきて増やせます。
設定方法で説明した「モデルのダウンロード」の要領で
CivitaiやHuggingFaceから落としてください。
▶STEP2-②プロンプトの調整
プロンプトとネガティブプロンプトに単語を追加してみて、
調整してみてください。
例えば夜にしたければ「night」をプロンプトに加えてみます。

(きっとこれは盆踊りしてるw)
▶STEP2-③パラメータを調整してみる
StableDiffusionには、実は多くのパラメータがあります。
全部覚えるのは後にして、まずは調整するのに覚えて欲しい
最低限のパラメータを紹介します。
[①CFG Scale]
これは「どれだけ独創的な絵を描くか?」です。
小さい▶︎なるべくプロンプト通りに生成
大きい▶︎自由に生成
この数値を変えるだけで画像の雰囲気が変わるので
変更を試して見てください
[②サイズ]
画像のサイズです。
512×512が良いです。(後で調整します)
ほとんどのモデルは512×512学習しているので、
比率変えると破綻した画像になりやすいです。
大きくしすぎると時間がかかるため、
たくさん出すには小さめで。
この2つを調整しながら、たくさん生成して好みの画像を生成します。
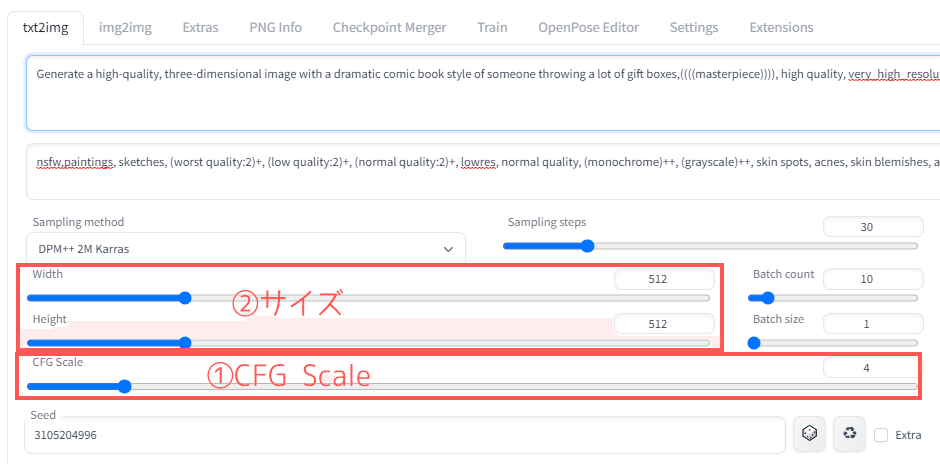
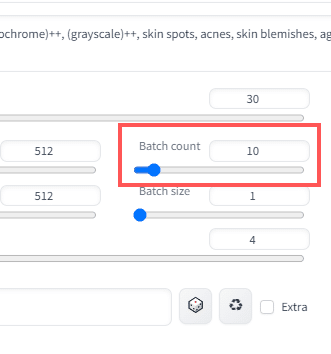
[Batch count]
たくさん作るときですが、「Batch count」という項目があります。
これは1回《Genarate》ボタンを押すとこの数の画像を
一括で作るよというものです。
10なら、1回ボタンをおしたら10個連続で作ってくれます。
最大100個まで作れます。
STEP3:ひとつ決めて画質をあげる
良い画像が出てきたら、コンテンツに使うために画質を良くします。
▶STEP3-①絞り込み
お気に入りの画像ひとつ決めて、さらに絞り込みます。
そのためにひとつ決めた画像に近い画像をたくさん生成します。
「シード値」と呼ばれるものを入力して生成します。
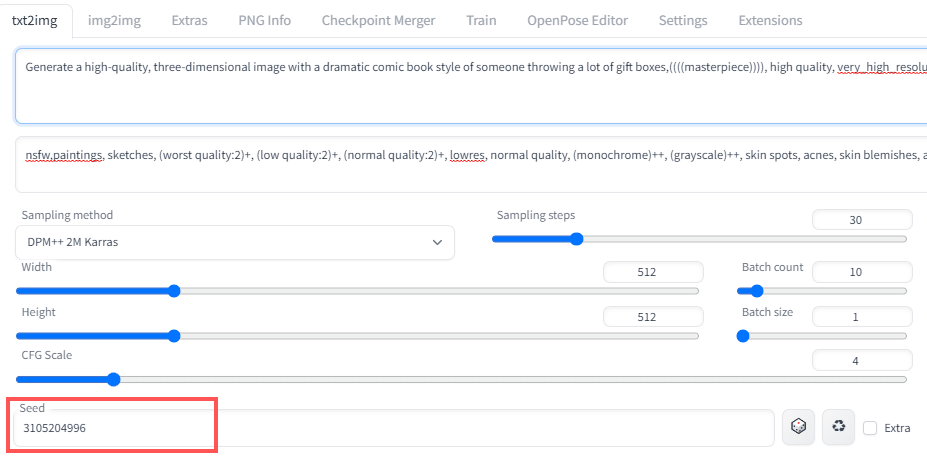
【シード値とは】
画像を生成する「種」みたいな数字です。
この値を元にAIは画像を生成します。
最初はこの値がランダムになっているので、生成の度に色んな違う構図や人物が出てきます。
(値が-1の場合がランダム)
このシード値を固定するとある程度似た画像が生成されます。
【シード値の調べ方】
StableDiffusionのタブから「PNFInfo」を選びます。
画像をドラック&ドロップする場所があるので、ここにお気に入りの画像を放り込みます。
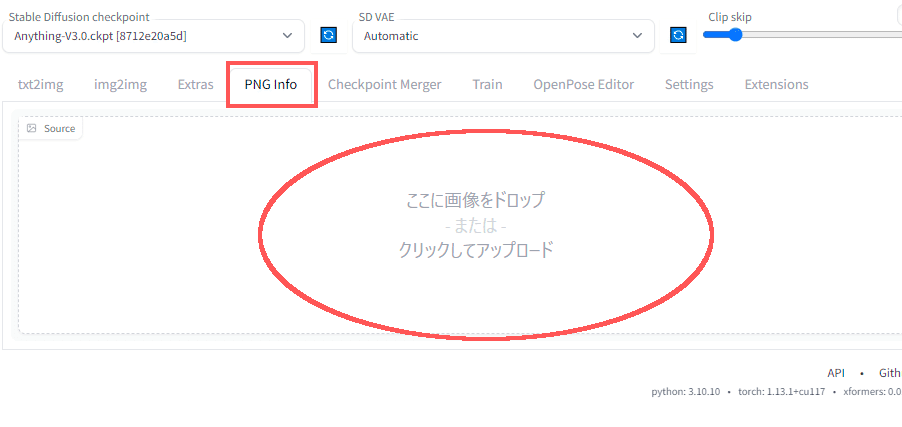
すると、その画像生成時のプロンプトや設定値が右側に表示されます。
ここに「SEED値」も表示されます。
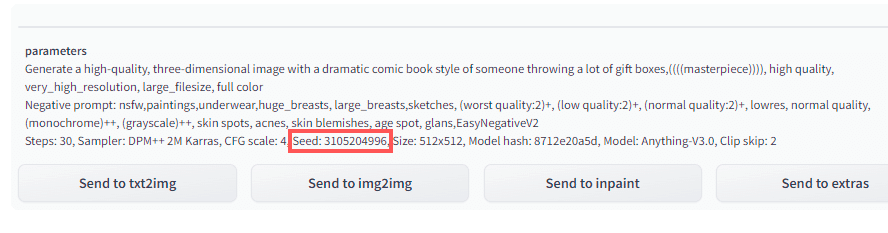
同じパラメータで
シード値をさっき調べた値で固定して
5から10枚程度生成してみましょう。
「Send to txt2img」ボタンでパラメータが全部反映されます。
これ楽です。
どうですか?
似た感じのものが生成されましたか?
もしお気に入りがなければ、
もういちどパラメータを少しいじってみましょう。
今回はプレゼント企画なので、プレゼント持って投げてる。これで。

STEP4:仕上げる
仕上げとして、
サイズの変更して仕上げます。
コンテンツのアイキャッチ画像は横長の画像が多いです。
note記事の場合、画像の横幅620pxです。
アイキャッチ(記事の先頭)は1280px×670pxです。
note記事の場合はこの横幅に合わせて、
投稿時に自動的にリサイズ(縮小)されますが、
これに近い形にサイズ変更をします。
今回は、縦512px×幅1024pxにサイズ変更をして仕上げます。
割といろいろなやり方があり、追及しだすとキリがないです。
今回は3つ紹介します。
方法①:img2img機能を使ってサイズ変更をする
方法②:コントロールネットを使ってサイズ変更する
方法③:高解像度の画像を作ってトリミングする
やりやすい&妥協できる方法でお試しください。
方法①:img2imgを使ってサイズを変更する
StableDiffusionにはイメージ画像から別のイメージ画像を生成する
「img2img」という機能があります。
その機能を利用して、なるべく同じイメージをサイズを変えて
生成します。
▶方法①-1:Inpaintの設定
StableDiffusionの「img2img」のタブを選択して、
「Inpaint」を選んでください。

【設定】
以下の値を設定しましょう。
Resize mode:copy and resize
width:1024
height:512
他の項目はそのままで良いです。

▶方法①-2:生成する
《Generate》ボタンを押してください。
設定したサイズにあわせて大きさが変更されます。
※今回はちょっと微妙。見切れてしまいました。

方法②:コントロールネットを使ってサイズ変更する
コントロールネットという拡張機能があります。
自分の好きなポーズを指定できる機能です。
これを利用して、同じ画像のサイズを変える事ができます。
今は主にこの機能を使っています。
コントロールネットの導入方法長くなるので、ここでは説明しません。
リクエストが多かったら、次回の企画か、オープンチャットでお伝えしますね。
▶方法②-1:コントロールネットの設定
・「txt2img」を選択して、次の設定をしてください。
【設定】
width:1024
height:512
・ControlNet「▼」クリックして
「image」欄に画像をドロップしてください。
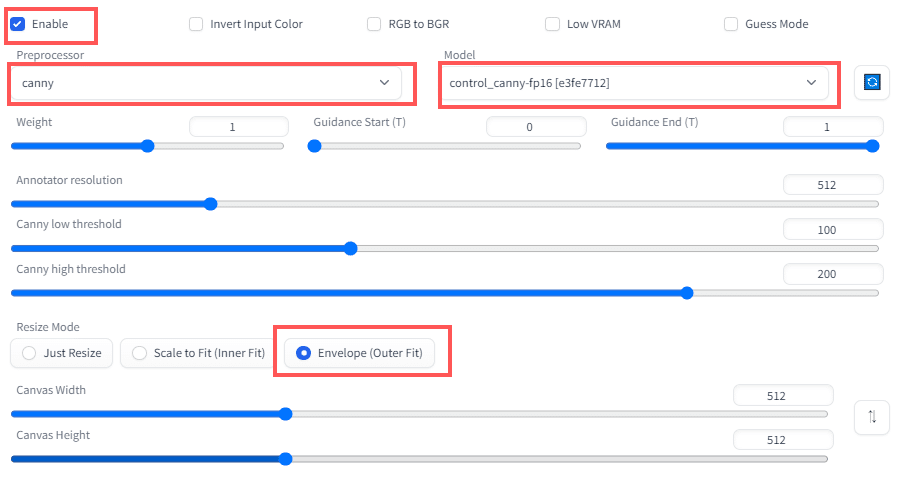
・ControlNet欄を次の設定にしてください。
【設定】
Enable:チェック
preprocessor:canny
Model:control_canny-fp15
Resize Mode:Scale to Fit(Inner Fit)
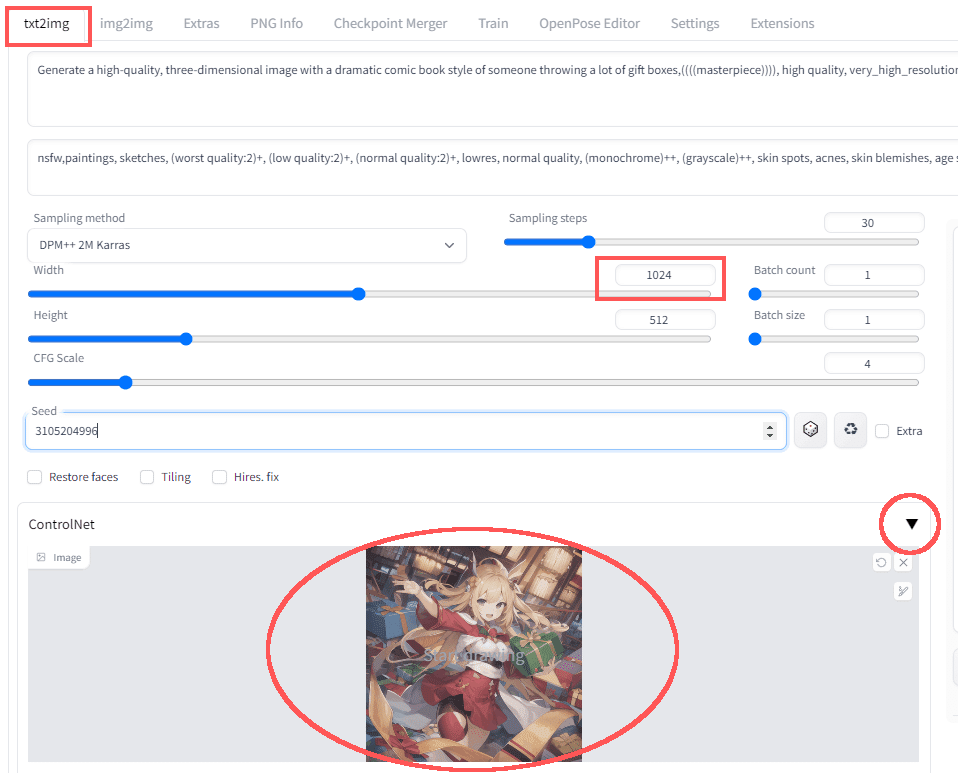
▶方法②-2:生成する
《Generate》ボタンを押してください。
この方法は、元の絵の線画を抽出して再描画します。
色などは変わるので、複数出して好きなのを選びます。
出来上がりはこれ▼

方法③高解像度の画像を作ってトリミングする
STEP2の「txt2img」の段階で解像度の高い画像を生成して、
ペイントや市販の画像処理ソフトでトリミングします。
txt2imgで縦横比を変えると、おかしな画像が多くなります。
設定の画像サイズは512px×512pxのまま
「Hires.fix」という機能を使います。
「Hires.fix」は、解像度を上げる(アップコンバート)する機能です。
チェックをいれると、時間はかかるけど、画質が上がります。

1024px×1024pxで出来上がります。
▼出来上がりはこちら

あとは市販の画像編集ツールで、トリミングします。
出来上がり

上下をカットしたくなかったら、ここから「②コントロールネットを使う」の手順でサイズ調整することもできます。
これが一番キレイにできます。
まとめ
ここまで、コンテンツに利用する
イラスト作成の手順について説明してきました。
まだまだ
いろいろな画質向上する方法たくさんあります。
こだわり始めると、肝心のコンテンツ作成が進まなくなるので、
どこで区切りをつけるか?が大事になってきます。
みなさんもほどほどに。
そろそろおなか一杯だと思いますので、
今回はここまでです。
他にリクエストありましたら、次回以降の企画にしたいと思います。
それでは最後まで読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?