
Seq2SeqからのAttentionの件

Attentionとは、名前の通り必要な情報に「注意」を払わせる技術です。
イメージでいうと、
「こんにちは。私の名前はJohn トラボルタです」を英語に翻訳するときは、特定の単語に注目して、適宜英語に脳内変換していると思います。
「こんにちは」は「Hi」、「私の名前」は「my name」という感じで、適宜特定の単語に注意していると思います。この特定の単語に注目しようという機構を実現するのが、Attentionです。
それでは以降
・seq2seqと翻訳
・seq2seqの弱点
・Attentionとは
という順番で説明していきます。
seq2seqと翻訳
Seq2seqとは、Encoder-Decoderモデルとも呼ばれ、入力となる時系列データを別の時系列データに変換します。そしてSeq2seqは、名前の通りEncoderとDecoderによって構成されています。
今回は「you say hey」を日本語に翻訳するとします。Encoderは「you say hey」と言う文字列が渡されて、「you say hey」を翻訳に必要なコンパクト情報hにまとめます。ここで翻訳に必要なコンパクト情報hはベクトルです。つまりEncoderは、入力文書をある固定のベクトルに変換する機能を持ちます。Encoderは翻訳に必要なコンパクト情報hを元に、文章を予測していきます。流れとしては、まずは「あなた」という予測を出し、「あなた」という予測から次に来る単語「ヘイ!」を予測します。
これは「PytorchでBackNumber…」のブログと同じことをやっています。

seq2seqの弱点
seq2seqには弱点があります。それは「入力文書の長さにかかわらずベクトルhが固定長」と言う点です。これではすごく長い文章を、コンパクトな情報(ベクトルh)にまとめ切らなくなります。そこで出てくるのがAttentionです。
Attentionを理解するためには、「Encoderの工夫」と「Decoderの工夫」の2点を抑えましょう。
Attentionとは
上記の通りAttentionを理解するためには、「Encoderの工夫」と「Decoderの工夫」を理解する必要があります。それでは早速説明していきます。
■Encoderの工夫
通常のseq2seqでは、最終時刻の出力ベクトルhしか利用しませんでした。
しかしAttentionにおいては、全ての時刻の出力ベクトルを利用します。
したがって、3単語ならば(3×n)の行列が出力され、50単語ならば(50×n)の行列が出力されます。これによってEncoderは、「入力文書の長さにかかわらずベクトルhが固定長」と言う弱点を克服します。
また各時刻の隠れ状態には、直前に入力された単語の情報が多く含まれているはずです。よって行列hsは、入力単語に対応したベクトルの集まりだと考えられます。例えば「1行目は最初に入力された単語のベクトル」に対応し、「2行目は二番目に入力された単語のベクトル」に対応すると言った感じです。

■Decoderの工夫
Decoderの工夫は、「行列hsの各行が単語ベクトルを表しているならば、着目するべき単語(行)に対して重みを掛けてあげよう!」と言うものです。
そうすると冒頭でもご説明した「特定の単語に注目」することができるようになるわけです。

ここで問題になるのが、「重みa」はどのように求めるのか?だと思います。以降は重みaの求め方を説明します。
重みaの算出の手順は以下の通りです。
1 行列hsの各行とベクトルhの内積を計算する
LSTMレイヤの出力hと行列hsの各行の内積を計算することで、ベクトルhとの類似度が高い行(単語)を見つける。つまりこれは、LSTMレイヤの出力から、着目するべき行(単語)を見つけていることと一緒です。
2 softmaxで正規化する
おなじみのsoftmaxでは、値を0~1且つ合計1に正規化しています。
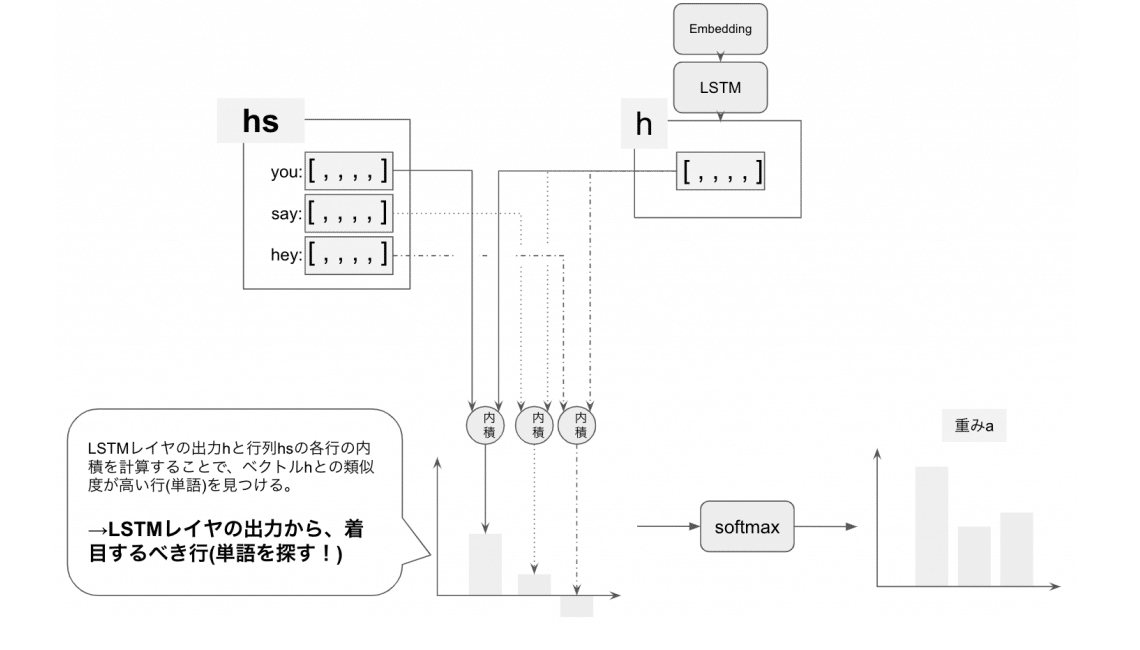
以上の「行列hsの重み付き和を算出するレイヤ」と「重みaを算出するレイヤ」を合わせて、Attentionレイヤと言います。

そしてこのAttentionレイヤを活用することで、精度向上が期待できるようです!(実際にまだ試していない…)
以上でAttentionの備忘録ブログ終了です!
最後に
間違っていたら(優しく)教えてください!