
「BackNumberっぽい歌詞を…」の追加説明

「PyTorchでBackNumberっぽい歌詞を生成してみた」の説明がすごい長くなったので、こちらのブログで追加の説明を行います。
前述のブログでは、シンプルなRNNについて説明しました。しかしPyTorchによる歌詞生成についてはLSTMを利用しました。
一部の読者(読者がいるかわからないが…)は、
「は?LSTMで歌詞生成してるじゃん。RNNと全く関係ないじゃん。」
と思われたでしょう。しかし一般的に「RNN」と言ったら、「LSTM(ゲート付きRNN)」を指すことが多いです。まあそのぐらい密接な関係があるわけですね。(強引)ということですので、LSTM(ゲート付きRNN)について説明していきます。
なぜRNNだといけないのか?
RNNでは、文章が長い(時刻tの値が大きい)と、勾配消失問題や勾配爆発問題が起きる可能性が出てきます。
RNNの誤差逆伝播の簡単な流れを下図で表しました。
下図でも確認できる通り、RNNの誤差逆伝播においては「tanhの微分」と「行列Whの微分」がtの数だけ出現します。
「tanhの微分」による勾配消失
𝑦=tanh(𝑥)の時、導関数は∂𝑦/∂𝑥=1–𝑦2となります。したがってtanhの数が多ければ、勾配情報が小さくなる可能性があるのです。
「行列Whの微分」による勾配爆発
正直完全理解には程遠いので後で追記します。
取り急ぎは他サイトの文章を引用させていただきます。。。
行列の積の微分は、掛けられる側の行列の転置であり、行列のノルムは特異値で決まるので、簡単に勾配爆発が起きてしまいます。(参照元:マサムネの部屋「勾配の更新に関する問題」)

早速LSTM!
LSTMは以下5つのポイントを抑えておけば、とりあえずは大丈夫かなと思いました。
・記憶セル
・outputゲート
・forgetゲート
・新しい記憶セル
・inputゲート
それでは5つについて、図を用いて簡単に説明します。
また以下図はLSTMレイヤに着目した図です。

より良いLSTMネットワークを作るには
・LSTMレイヤの多層化

層を重ねれば、複雑なモデル表現ができるから、まあ精度が上がる可能性はあるなというのは納得できます。
・Dropout
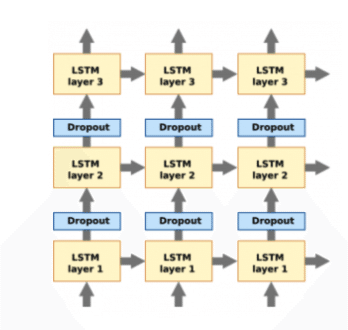
参照元:https://discuss.pytorch.org/t/lstm-dropout-clarification-of-last-layer/5588
Dropoutは深さ(縦方向)に入れるのが基本です。
「t-1のLSTMレイヤ」と「tのLSTMレイヤ」の間にDropoutを入れると、時間が進むに比例して情報が失われてしまい、よくないらしいです。通常のDNNと同じ考え方だとすると、これもまあ納得できます。
(一方で変分Dropoutと言った、時間方向(左右のLSTMレイヤの間)にDropoutを挟む方法もあるようです。)
・重み共有
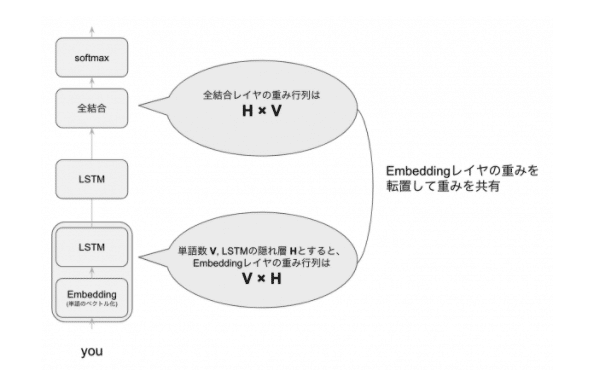
ファ!?
もはやなぜ精度が上がるのかわからない….
重みを共有することで、パラメーター数を減らすことができ過学習を防げるのだとか…納得できない….
詳細は以下論文にあるらしいので、後で読んでみます。。。
https://arxiv.org/abs/1611.01462
最後に
間違えてる箇所あったらご指摘ください!