
BigQuery Scheduled QueryをTerraformで管理する

はじめに
現在Google Cloud Platformでデータ分析基盤を構築しています。そこでETL処理の実装が必要でしたが、現在プロトタイプを構築するフェーズであり、ETL処理を作りこむ必要はありません。色々調べていくと、BigQueryにはScheduled QueryというSQLを定期実行する機能があると知りました。SQLでETL処理を書ける手軽さから、Scheduled QueryとSQLでETL処理を実装する方針を採用しました。さらに、SQLを修正するたびにGCPコンソールから手動でScheduled Queryを設定する手間を削減するため、Terraformを利用しデプロイを自動化しました。
本記事ではTerraformによるScheduled QueryおよびSQLの管理方法を解説します。
システム構成
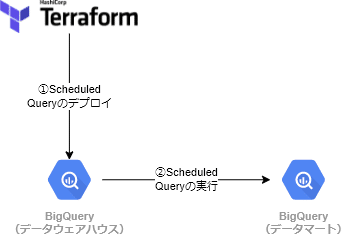
①Teraformを利用し、Scheduled QueryをBigQueryに登録します。
②Scheduled Queryで、データウェアハウス用データセットからデータを抽出・集計し、データマート用データセットに投入します。
BigQuery Scheduled Query
Scheduled Queryは、登録したSQLを定期実行するBigQueryの機能です。
公式ドキュメントを参考に、Scheduled Queryを登録します。公式ドキュメントで具体的な手順をわかりやすく説明しているため、本記事では手順を説明しません。ブラウザのQuery EditorでSQLを作成し、クエリ結果を確認しながら加工ロジックを確立しました。
TerraformによるScheduled QueryのIaC化
ここまででScheduled Queryを登録できました。しかし、クエリを手動で追加しなければならず、単純に手間がかかります。さらに追加時に設定ミスが起きてしまうかもしれません。なので、Scheduled QueryをTerraformでIaC化して管理します。
ディレクトリ構成
まずTerraformのディレクトリ構成を示します。Scheduled Queryを実行するサービスアカウントとその権限、Scheduled QueryのTerraformモジュールを定義します。
.
|-- main.tf // Terraformリソースの宣言
|-- modules
| |-- scheduled-query
| | `-- module.tf // Scheduled Queryモジュールの定義
| `-- service-account
| `-- module.tf // Scheduled Query実行サービスアカウントモジュールの定義
`-- query.sql // Scheduled Queryとして実行するSQLファイルmodules/service-account/module.tf
variable "project" {}
variable "service_account_id" {}
variable "service_account_display_name" {}
variable "custom_role_id" {}
variable "custom_role_title" {}
variable "custom_role_description" {}
variable "custom_role_permissions" {
type = list(string)
default = []
}
// サービスアカウントの定義
resource "google_service_account" "service_account" {
account_id = "${var.service_account_id}"
display_name = "${var.service_account_display_name}"
project = "${var.project}"
}
// サービスアカウントに紐づけるロールの定義
resource "google_project_iam_custom_role" "custom_role" {
role_id = "${var.custom_role_id}"
title = "${var.custom_role_title}"
description = "${var.custom_role_description}"
permissions = var.custom_role_permissions
}
// サービスアカウントとロールの対応
resource "google_project_iam_member" "iam" {
project = "${var.project}"
role = "${google_project_iam_custom_role.custom_role.name}"
member = "serviceAccount:${google_service_account.service_account.email}"
}
output "service_account_email" {
value = google_service_account.service_account.email
}modules/scheduled-query/module.tf
variable "data_source_id" {}
variable "project" {}
variable "location" {}
variable "schedule" {}
variable "display_name" {}
variable "query" {}
variable "service_account_name" {}
resource "google_bigquery_data_transfer_config" "scheduled_query" {
data_source_id = "${var.data_source_id}"
project = "${var.project}"
location = "${var.location}"
schedule = "${var.schedule}"
display_name = "${var.display_name}"
params = {
"query" = "${var.query}"
}
service_account_name = "${var.service_account_name}"
}main.tf
provider "google" {
project = "{GCPプロジェクト名}"
region = "asia-northeast1"
}
// ---サービスアカウントとその権限の定義---
module "service_account_for_job_executor" {
source = "./modules/service-account"
project = "{GCPプロジェクト名}" // GCPプロジェクト名
service_account_id = "bigquery-job-test" // 任意のサービスアカウントID
service_account_display_name = "BigQuery-Job-Executor" // 任意のサービスアカウントの表示名
custom_role_id = "BigQueryDataTransferService_test" // 任意のロールID
custom_role_title = "BigQuery Job Executor" // 任意のロール名
custom_role_description = "Execute Jobs that extract data from Bigquery tables and transform, load to Bigquery tables." // 任意のロールの説明
custom_role_permissions = [
"bigquery.jobs.create",
"iam.serviceAccounts.getAccessToken",
"logging.logEntries.create",
"resourcemanager.projects.get",
"bigquery.datasets.get",
"bigquery.datasets.getIamPolicy",
"bigquery.tables.create",
"bigquery.tables.createSnapshot",
"bigquery.tables.delete",
"bigquery.tables.export",
"bigquery.tables.get",
"bigquery.tables.getData",
"bigquery.tables.getIamPolicy",
"bigquery.tables.list",
"bigquery.tables.restoreSnapshot",
"bigquery.tables.update",
"bigquery.tables.updateData",
"bigquery.tables.updateTag"
] // 解説①
}
// ---Scheduled Queryの定義---
module "scheduled_query" {
source = "./modules/scheduled-query"
depends_on = [module.service_account_for_job_executor]
data_source_id = "scheduled_query"
project = "{GCPプロジェクト名}" // GCPプロジェクト名
location = "asia-northeast1" // Scheduled Queryの実行リージョン
schedule = "every day 15:00" // 定期実行タイミング(UTC)
display_name = "Scheduled Query" // 任意の表示名
query = templatefile("./query.sql", {
warehouse_table: "{プロジェクト名}.{データセット名}.{テーブル名}",
datamart_table: "{プロジェクト名}.{データセット名}.{テーブル名}",
}) // ※解説②
service_account_name = "${module.service_account_for_job_executor.service_account_email}"
}解説①:今回は上記権限を設定しました。それぞれのユースケースに合わせて最小権限を付与してください。
解説②:Terraformの定義ファイルにそのままSQLを記載できます。しかし、管理のしやすさを考えると、SQLファイルを別途用意し、Terraform実行時に読み込めると便利です。そこでTerraformが提供するtemplatefile関数を利用しました。
開発環境やステージング環境ごとにGCPプロジェクトを分けたいケースが多々あります。SQL内にプロジェクト名を直接書いてしまうと、環境ごとにSQLファイルを用意しなければなりません。それは手間なので、templatefile関数から変数を代入します。以下のコードでは、templatefile関数の第一引数にSQLファイルのパス、第二引数にSQLファイルで利用する変数名とその値を渡します。
query = templatefile("./query.sql", {
warehouse_table: "{プロジェクト名}.{データセット名}.{テーブル名}",
datamart_table: "{プロジェクト名}.{データセット名}.{テーブル名}",
})query.sql
集計などデータマートの作成ロジックをSQLファイルで実現します。Terraformのtemplatefile関数で定義した変数は、SQLファイルでは${ 変数名 }で利用できます。
INSERT INTO ${datamart_table}
SELECT
count(*)
FROM ${warehouse_table}
GROUP BY id;以下の例ではデータウェアハウス用テーブルからIDごとの数を集計し、その値をデータマートに投入するだけです。ここはユースケースに応じて集計ロジックを実装してください。
まとめ
TerraformによるScheduled QueryおよびSQLの管理方法を解説しました。
データアナリストがSQLを用いてアドホックに分析するケースは多いと思います。そのSQLを手軽に定期実行できるScheduled Queryは重宝するのではないでしょうか。さらに、TerraformによるIaC化が一度できれば、Scheduled Queryの設定ミスや手間を削減できます。ここまでくると、GitリポジトリSQLがプッシュされたらScheduled Queryを自動で登録するといったCI/CDパイプラインを構築も考えられます。エンジニアの開発工数を最小限にしつつ、データアナリストが手動してETL処理を作れるため、PoCとしてデータ連携したい場合はとても有用だと思います。
データ分析基盤を正式に構築するとなり、Scheduled Queryだけでは要件を満たせない場合(例えば、処理のリトライやエラーハンドリング、ジョブの実行制御等)、ワークフロー管理ツールの導入や、ETL処理の独自実装を検討してください。
本記事がデータ分析基盤とETLを実装しようとする方々の一助になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?