
SAM2をUltralyticsで試してみた

概要
YOLOv8等が利用できる Ultralytics がSAM2をサポートしたので試してみました。
SAM2の tiny ~ large サイズの重みを利用できます。
画像や動画のセグメンテーションが可能です。
YOLOv8等の物体検出モデルを組み合わせたセグメンテーションの自動アノテーション関数が利用できます。
タイトルの通り本記事はUltralytics上のSAM2を利用しています。
Meta公式のSAM2の利用方法はnpakaさんが記事を投稿されておりますので是非そちらをご覧ください!
実施内容
Google Colab (Pro)のL4で実行しました。
準備
Ultralyticsのライブラリをインストールします。
!pip install ultralytics使用するライブラリをインポートします。
# 結果の可視化関連の処理で使用
from IPython.display import Image
import cv2
import numpy as np
# 画像/動画のセグメンテーションで使用
from ultralytics import SAM
# 自動アノテーションで使用
from ultralytics.data.annotator import auto_annotate
from ultralytics.utils.plotting import colors画像/動画のセグメンテーションを行うSAM2のインスタンスを作成します。
今回はlargeサイズを試したいので "sam2_l.pt" を指定しています。
指定した重みファイルは自動でダウンロードされ、作業フォルダに保存されます。
# モデル読み込み
model = SAM("sam2_l.pt")
# モデル概要情報の表示
model.info()入力画像として Ultralytics のサンプル画像 bus.jpg を使用します。

画像のセグメンテーション (プロンプト: 矩形)
対象を囲む矩形の座標を指定してセグメンテーションを行います。
指定する座標を下記のコードで可視化します。
# 矩形の左上と右下となる2点の座標(0, 200)と(809, 750)を指定し、緑色で描画
cv2.imwrite("show_box.jpg", cv2.rectangle(cv2.imread("bus.jpg"), (0, 200), (809, 750), color=(0, 255, 0), thickness=2))
Image("show_box.jpg")
入力画像と矩形の座標を指定してセグメンテーションを実行します。
# 矩形指定のプロンプトでセグメンテーションを実行
box_results = model("bus.jpg", bboxes=[0, 200, 809, 750])
# 結果を保存
box_results[0].save("box_result.jpg")
Image("box_result.jpg")
画像のセグメンテーション (プロンプト: 点)
対象の座標を指定してセグメンテーションを行います。
指定する座標を下記のコードで可視化します。
# 任意の点の座標(120, 600)を指定し、緑色で描画
cv2.imwrite("show_point.jpg", cv2.circle(cv2.imread("bus.jpg"), (120, 600), radius=5, color=(0, 255, 0), thickness=-1, lineType=cv2.LINE_8, shift=0))
Image("show_point.jpg")
入力画像と点の座標を指定してセグメンテーションを実行します。
# 点指定のプロンプトでセグメンテーションを実行
point_results = model("bus.jpg", points=[120, 600], labels=[1])
# 結果を保存
point_results[0].save("point_result.jpg")
Image("point_result.jpg")
動画のセグメンテーション
入力する動画は NHKクリエイティブ・ライブラリーのWebサイト で公開されている以下の素材をお借りしました。
素材名: 横浜 馬車道の風景
ファイル名: D0002040360_00000_V_000.mp4
上記動画のそのままの尺ではSAM2の推論に時間がかかりすぎてしまうので、約10秒にトリミングした動画ファイルを作成して使用しました。
それでも推論に30分以上はかかったかと思います。
Ultralyticsの記事を参考にプロンプト無しで動画を入力し、各フレームの推論結果を画像として保存します。
# プロンプト無しで動画のセグメンテーションを実行
video_results = model("D0002040360_00000_V_000_trim.mp4", stream=True, verbose=False)
# 推論結果を保存(保存先フォルダ video_outputs は事前に手動で作成しました。)
frame_num = 0
for result in video_results:
result.save(f"video_outputs/frame_{frame_num:04d}.jpg")
frame_num += 1保存された各フレームの推論結果画像を繋げて動画ファイルにします。
# 推論結果の動画化
video = cv2.VideoWriter("result_video.mp4", cv2.VideoWriter_fourcc(*"mp4v"), 30.0, (1280, 720))
for i in range(frame_num):
video.write(cv2.imread(f"video_outputs/frame_{i:04d}.jpg"))
video.release()結果の動画は以下の様になりました。
参考として、50、150、250フレーム目を以下に添付します。
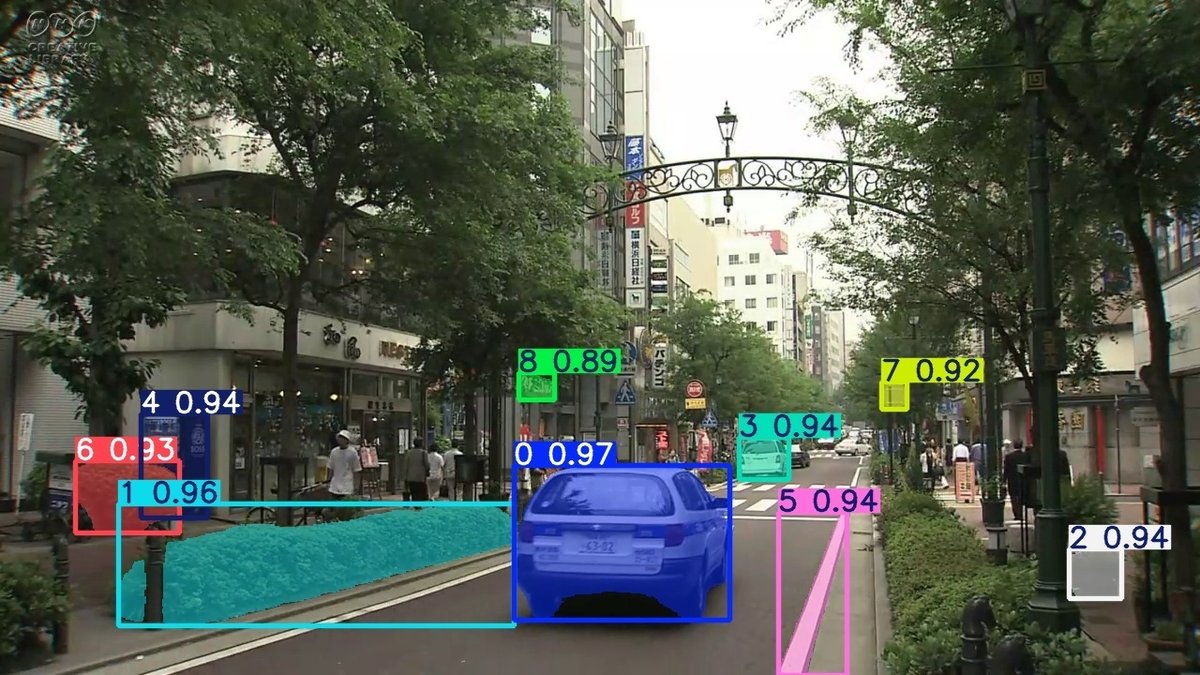

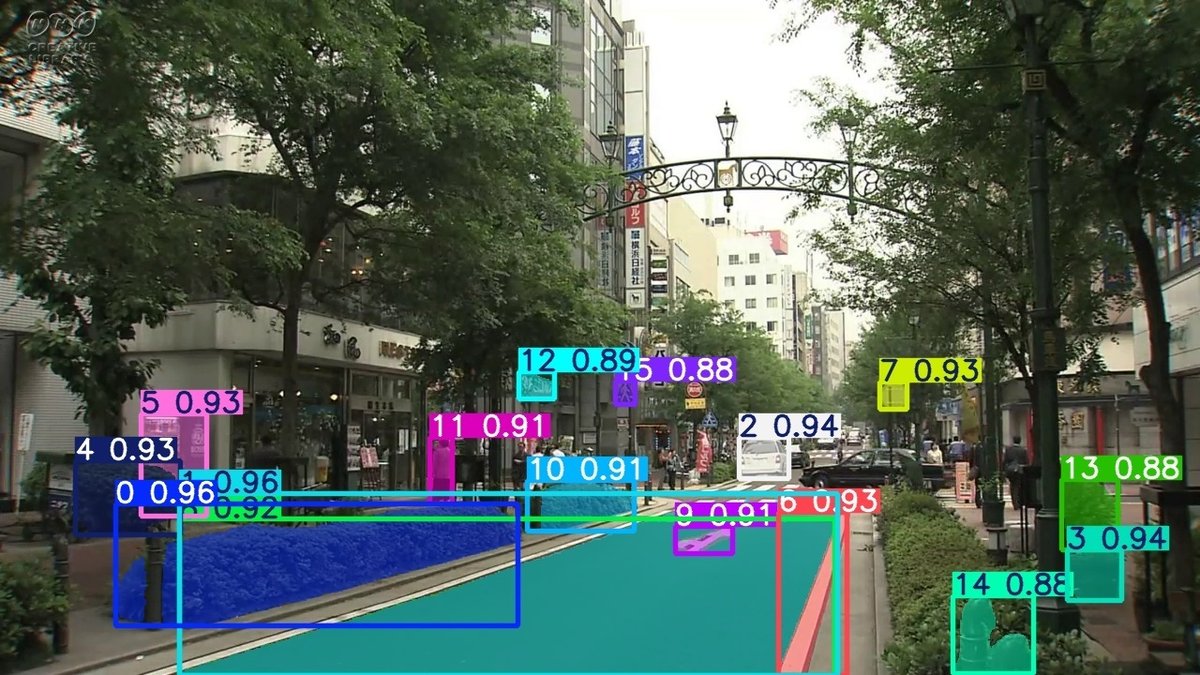
50フレーム辺りまでは中央の白い車が同じ色の矩形で描画されていますが、遠ざかると別の色の矩形で描画されました。
詳細は調査できていないのでただの想像ですが、
矩形の左上ラベル部分はSAM2から出力された順番とスコアが表示されており、矩形の色はその順番に紐づいている感じでしょうか。
実行前の予想ではもっと多くの物体がセグメンテーションされるかと期待していたので、個人的にこの結果は少し消化不良でした。
色々実験が必要そうです。
自動アノテーション
Ultralyticsには自動アノテーション用の関数 auto_annotate が用意されています。
引数は入力画像、物体検出モデル、SAM/SAM2のモデルを指定します。
# 物体検出にYOLOv8のXサイズ、SAMのモデルにSAM2のLサイズを指定
auto_annotate(data="bus.jpg", det_model="yolov8x.pt", sam_model="sam2_l.pt")自動アノテーション結果は、入力データ名に「_auto_annotate_labels」がついたフォルダにtxtファイルとして保存されます。
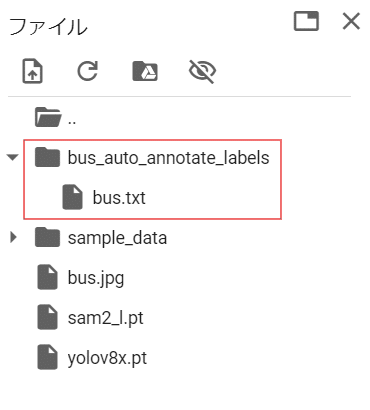
txtファイルはYOLOのセグメンテーション用フォーマットになっています。
1行がセグメンテーションマスク1つを示しており、各行は以下の様にクラスIDとマスクの輪郭座標がスペース区切りで記録されています。
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
※座標は0~1の値に正規化されています。

保存されたtxtファイルのマスク情報を読み込みます。
img = cv2.imread("bus.jpg")
img_h, img_w = img.shape[:2]
# 自動アノテーション結果のtxtファイル読み込み
with open("bus_auto_annotate_labels/bus.txt") as f:
lines = f.readlines()
cls_ids = []
poly_points_list = []
for line in lines:
cols = line.replace("\n", "").split(" ")
cls_ids.append(int(cols[0])) # クラスID
poly_cols = cols[1:] # マスクの輪郭座標
assert len(poly_cols) % 2 == 0
poly_points_list.append(
[(int(float(poly_cols[2*n])*img_w), int(float(poly_cols[2*n+1])*img_h)) for n in range(int(len(poly_cols) / 2))]
)読み込んだマスクを可視化します。
anno_img = img.copy()
for idx, cls_id in enumerate(cls_ids):
cv2.fillConvexPoly(anno_img, np.array(poly_points_list[idx]), colors(cls_id, True))
cv2.imwrite("auto_annotate_result.jpg", anno_img)
Image("auto_annotate_result.jpg")
色とクラスの対応は以下の通りです。
青色: 人 水色: 自転車 ピンク: バス
ただし、この画像のバスの様に形状が複雑なマスクの可視化は要注意です。下記のコードでバスのマスクだけ可視化してみます。
bus_masks = []
for idx, cls_id in enumerate(cls_ids):
if cls_id != 5: # バス(ID=5)以外はスキップ
continue
bus_masks.append(
cv2.fillConvexPoly(img.copy(), np.array(poly_points_list[idx]), colors(cls_id, True))
)
cv2.imwrite("auto_annotate_bus_result.jpg", bus_masks[0])
Image("auto_annotate_bus_result.jpg")
画像左側の人まで塗りつぶされてしまっています。
確認のため、塗りつぶしではなく輪郭座標自体を描画すると以下の様になりました。
poly_img = img.copy()
for cls_id, poly_points in zip(cls_ids, poly_points_list):
if cls_id != 5:
continue
for poly_point in poly_points:
cv2.circle(poly_img, poly_point, radius=2, color=colors(cls_id, True), thickness=-1, lineType=cv2.LINE_8, shift=0)
cv2.imwrite("bus_poly.jpg", poly_img)
Image("bus_poly.jpg")
輪郭座標はきれいに人を避けていることがわかります。
そのため自動アノテーションの結果自体は正常で、可視化方法が悪いだけでした。
過去に記事を作成した🍩のように、YOLO形式のマスクを可視化する際は工夫が必要そうです。
まとめ
SAM2の結果をYOLOv8等と同様の形式で取得できます。
今回試した動画では、想像していたよりセグメンテーションされる物体が少ない印象を受けました。
複雑な形状のマスクの可視化方法が課題です。
この記事が気に入ったらサポートをしてみませんか?